Двоичное кодирование информации
Любая информация внутри компьютера хранится и обрабатывается в виде длинного кода, состоящего всего из двух символов. Этот код называется двоичным или бинарным.
По своей сути он очень похож на всем известный код Морзе, в котором двумя символами (длинный и короткий импульс) шифруются буквы для передачи текстовой информации по проводам или другим способом.
Компьютеры же пошли значительно дальше. В них в форме бинарного кода хранятся не только текстовые данные, но и программы, музыка, изображения и даже видео высокой четкости.
Перед выводом информации на экран, в аудиосистему или распечатыванием, компьютер «переводит» ее в понятный человеку язык. Но внутри компьютера она хранится и обрабатывается исключительно в виде двоичного кода.
Если вы не программист, знать систему использования бинарного кода в совершенстве не обязательно. Для понимания принципов работы компьютера достаточно разобраться с вопросом в общих чертах. В этом вам и поможет предлагаемая статья.
Содержание статьи
Как считает компьютер?
В компьютере используется элементарная двоичная система исчисления: числа складываются только из двух знаков – нуля и единицы. Это связано в первую очередь с внутренним строением компьютера. Внутри процессора находятся миллионы транзисторов, которые по своим техническим особенностям имеют два состояния: включен (ток свободно протекает) или выключен (ток не течет).
Различия между двоичной, десятичной и шестнадцатеричной системой
Свойства числовой информации
Конечность. Информация, выраженная числовым значением, должна быть конечной. Процессор персонального компьютера не сможет обработать число, которое не является конечным или завершенным. То есть прежде чем приступить к кодированию числовой информации, процессор должен быть уверен, что данное значение записано полностью и не будет изменено пользователем.
Понятность. Если мы говорим о кодировании числовой информации, которая представлена десятичным числом, то необходимо, чтобы само число состояло из элементов, которые будут понятны исполнителю при кодировании. Исполнителем является, в строгом приближении, процессор персонального компьютера. Например, число 129 состоит из трех цифр: 1, 2 и 9. Каждое из этих цифр входит в состав арабского алфавита. Если мы представим числовую информацию в виде значения 89J1’4, то подобное значение будет некорректно обработано процессором и он выдаст исключение, то есть сгенерирует ошибку. Почему? Потому что входное число 89J1’4 состоит из элементов: 8, 9, J, 1, ‘, 4, не каждое из которых входит в состав арабского алфавита. Например, элементы J и ‘ не являются арабскими цифрами.
Приведенные два свойства являются ключевыми в алгоритмах кодирования числовой информации. Пожалуй, еще стоит отметить неосновное свойство – размер числа. Но в современном мире мощности персональных компьютеров постоянно увеличиваются и самые эффективные процессоры способы обрабатывать огромные значения.
Кодирование информации, применяемое в ЭВМ
1.Коды, применяемые в ЭВМ
Каким образом обрабатывается информация в компьютере и как обеспечить обмен информацией между пользователем и ЭВМ?
Процесс приема и передачи информации можно изобразить на схеме:

Кодирование – операция, связанная с переходом от исходной формы представления информации в форму, удобную для хранения, передачи или обработки.
Декодирование – связано с обратным переходом к исходному представлению информации.
В настоящее время существуют разные способы кодирования и декодирования информации в компьютере.
Выбор способа зависит от вида информации, которую необходимо кодировать: текст, число, графическое изображение и т.д.
ЭВМ может обрабатывать информацию, представленную только в числовой форме. Любая другая информация (текстовая, графическая) преобразуется в числовую информацию. Так, например, при вводе текста, каждый символ кодируется определенным числом (существуют специальные таблицы кодировки, наиболее известные и распространенные коды ASCII), а при выводе наоборот, каждому числу соответствует изображение определенного символа.
Восемь двоичных разрядов позволяют закодировать 2 8 =256 символов, этого достаточно, чтобы закодировать любую букву, цифру или служебный символ. Нажатие клавиши на клавиатуре приводит к тому, что сигнал посылается в компьютер в виде двоичного числа, которое хранится в кодовой таблице.
2. Кодовая таблица символов
Кодовая таблица символов — это внутреннее представление символов в компьютере. Во всем мире в качестве стандарта принята таблица ASCII (American Standart Code for Information Interchange) – Американский стандартный код для обмена информацией.
Первые 128 символов (от 0 до 127) – это цифры, прописные и строчные буквы латинского алфавита, управляющие символы. Вторая половина кодовой таблицы (от 128 до 255) предназначена для национальных символов (в том числе кириллицы), математических символов и так называемых псевдографических символов, которые используются для рисования рамок.
Нужно помнить о трех особенностях алфавита в кодовой таблице и их следствия:
1) прописные и строчные буквы представлены разными кодами, т.е. “А” и “а” – разные объекты;
2) при упорядочивании слов по алфавиту сравниваются между собой десятичные коды букв. Поэтому, чтобы избежать недоразумений, если не указано “нечувствителен к регистру”, используйте только латинский или русский алфавит и только прописные или только строчные первые буквы. Необходимо помнить, что любая цифра “меньше” любой буквы, код латинских букв “меньше” чем русских;
3) Многие латинские и русские буквы имеют визуально неразличимое начертание, но разные коды.
Итак, компьютер способен распознавать только значения бита. Однако он редко работает с конкретными битами в отдельности, а совокупность из 8 битов, воспринимаемая компьютером как единое целое, называется байтом.
Вся работа компьютера – это управление потоками байтов, которые устремляются в компьютер с клавиатуры или дисков (или по линии связи), преобразовываются по командам программ, запоминаются временно или записываются на постоянное хранение на магнитный диск, а также выводятся на экран дисплея или бумагу принтера в виде букв, цифр, значков.


3.Кодирование информации. Кодирование данных в ЭВМ
В ЭВМ применяется двоичная система счисления, т.е. все числа в компьютере представляются с помощью нулей и единиц, поэтому компьютер может обрабатывать только информацию, представленную в цифровой форме.
Для преобразования числовой, текстовой, графической, звуковой информации в цифровую необходимо применить кодирование.
Кодирование – это преобразование данных одного типа через данные другого типа. В ЭВМ применяется система двоичного кодирования, основанная на представлении данных последовательностью двух знаков: 1 и 0, которые называются двоичными цифрами (binary digit – сокращенно bit).
Целые числа кодируются двоичным кодом довольно просто (путем деления числа на два). Для кодирования нечисловой информации используется следующий алгоритм: все возможные значения кодируемой информации нумеруются и эти номера кодируются с помощью двоичного кода.
Кодирование чисел
Есть два основных формата представления чисел в памяти компьютера. Один из них используется для кодирования целых чисел, второй (так называемое представление числа в формате с плавающей точкой) используется для задания некоторого подмножества действительных чисел.
Кодирование целых чисел производиться через их представление в двоичной системе счисления: именно в этом виде они и помещаются в ячейке. Один бит отводиться при этом для представления знака числа (нулем кодируется знак «плюс», единицей – «минус»).
Для кодирования действительных чисел существует специальный формат чисел с плавающей запятой. Число при этом представляется в виде:
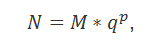
где M – мантисса, p – порядок числа N, q – основание системы счисления. Если при этом мантисса M удовлетворяет условию , то число N называют нормализованным.

Кодирование координат
Закодировать можно не только числа, но и другую информацию, например, о том, где находится некоторый объект. Величины, определяющие положение объекта в пространстве, называются координатами. В любой системе координат есть начало отсчёта, единица измерения, масштаб, направление отсчёта, или оси координат. Примеры систем координат – декартовы координаты, полярная система координат, шахматы, географические координаты.
Кодирование текста
Для представления текстовой информации используется таблица нумерации символов или таблица кодировки символов, в которой каждому символу соответствует целое число (порядковый номер). Восемь двоичных разрядов могут закодировать 256 различных символов.
Существующий стандарт ASCII (сокращение от American Standard Code for Information Intercange – американский стандартный код для обмена информацией; 8 – разрядная система кодирования) содержит две таблицы кодирования – базовую и расширенную. Первая таблица содержит 128 основных символов, в ней размещены коды символов английского алфавита, а во второй таблице кодирования содержатся 128 расширенных символов.
Так как в этот стандарт не входят символы национальных алфавитов других стран, то в каждой стране 128 кодов расширенных символов заменяются символами национального алфавита. В настоящее время существует множество таблиц кодировки символов, в которых 128 кодов расширенных символов заменены символами национального алфавита.
Так, например, кодировка символов русского языка Widows – 1251 используется для компьютеров, работающих под ОС Windows. Другая кодировка для русского языка – это КОИ – 8, которая также широко используется в компьютерных сетях и российском секторе Интернет.
В настоящее время существует универсальная система UNICODE, основанная на 16 – разрядном кодировании символов. Эта 16 – разрядная система обеспечивает универсальные коды для 65536 различных символов, т.е. в этой таблице могут разместиться символы языков большинства стран мира.
Кодирование графической информации
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие группы – растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселями (pixel, от англ. picture element). Код пикселя содержит информации о его цвете.
Для описания черно-белых изображений используются оттенки серого цвета, то есть при кодировании учитывается только яркость. Она описывается одним числом, поэтому для кодирования одного пикселя требуется от 1 до 8 бит: чёрный цвет – 0, белый цвет – N = 2 k -1, где k – число разрядов, которые отводятся для кодирования цвета. Например, при длине ячейки в 8 бит это 256-1 = 255. Человеческий глаз в состоянии различить от 100 до 200 оттенков серого цвета, поэтому восьми разрядов для этого вполне хватает.
Цветные изображения воспринимаются нами как сумма трёх основных цветов – красного, зелёного и синего. Например, сиреневый = красный + синий; жёлтый = красный + зелёный; оранжевый = красный + зелёный, но в другой пропорции. Поэтому достаточно закодировать цвет тремя числами – яркостью его красной, зелёной и синей составляющих. Этот способ кодирования называется RGB (Red – Green – Blue). Его используют в устройствах, способных излучать свет (мониторы). При рисовании на бумаге действуют другие правила, так как краски сами по себе не испускают свет, а только поглощают некоторые цвета спектра. Если смешать красную и зелёную краски, то получится коричневый, а не жёлтый цвет. Поэтому при печати цветных изображений используют метод CMY (Cyan – Magenta – Yellow) – голубой, сиреневый, жёлтый цвета. При таком кодировании красный = сиреневый + жёлтый; зелёный = голубой + жёлтый.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент такого изображения – линия, прямоугольник, окружность или фрагмент текста – располагается в своем собственном слое, пиксели которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т.д.) Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Объекты векторного изображения, в отличие от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость).
Кодирование звука
Как всякий звук, музыка является не чем иным, как звуковыми колебаниями, зарегистрировав которые достаточно точно, можно этот звук безошибочно воспроизвести. Нужно только непрерывный сигнал, которым является звук, преобразовать в последовательность нулей и единиц. С помощью микрофона звук можно превратить в электрические колебания и измерить их амплитуду через равные промежутки времени (несколько десятков тысяч раз в секунду). Каждое измерение записывается в двоичном коде. Этот процесс называется дискретизацией. Устройство для выполнения дискретизации называется аналогово-цифровым преобразователем (АЦП). Воспроизведение такого звука ведётся при помощи цифро-аналогового преобразователя (ЦАП). Полученный ступенчатый сигнал сглаживается и преобразуется в звук при помощи усилителя и динамика. На качество воспроизведения влияют частота дискретизации и разрешение (размер ячейки, отведённой под запись значения амплитуды). Например, при записи музыки на компакт-диски используются 16-разрядные значения и частота дискретизации 44 032 Гц.
Описанный способ кодирования звуковой информации достаточно универсален, он позволяет представить любой звук и преобразовывать его самыми разными способами. Но бывают случаи, когда выгодней действовать по-иному.
Издавна используется достаточно компактный способ представления музыки – нотная запись. В ней с помощью специальных символов указывается высота и длительность, общий темп исполнения и как сыграть. Фактически, такую запись можно считать алгоритмом для музыканта, записанным на особом формальном языке. В 1983 г. ведущие производители компьютеров и музыкальных синтезаторов разработали стандарт, определивший такую систему кодов. Он получил название MIDI (Musical Instrument Digital Interface). При таком кодировании запись компактна, легко меняется инструмент исполнителя, тональность звучания, одна и та же запись воспроизводится как на синтезаторе, так и на компьютере.
Конечно, такая система кодирования позволяет записать далеко не всякий звук, она годится только для инструментальной музыки. Но есть у нее и преимущества: чрезвычайно компактная запись, естественность для музыканта (практически любой MIDI-редактор позволяет работать с музыкой в виде обычных нот), легкость замены инструментов, изменения темпа и тональности мелодии.
Есть и другие форматы записи музыки. Среди них – формат MP3, позволяющий с очень большим качеством и степенью сжатия кодировать музыку, при этом вместо 18 – 20 музыкальных композиций на стандартном компакт-диске (CDROM) помещается около 200. Одна песня занимает примерно 3,5 Mb, что позволяет пользователям сети Интернет легко обмениваться музыкальными композициями.
Если есть сигнал — единичка, если нет — нолик
В статье «Пять поколений ЭВМ» перечисляется элементная база компьютеров разных поколений: электронные лампы, транзисторы, микросхемы. До сих пор ничего принципиально нового не появилось.
Перечисленные элементы четко распознают только два состояния: включено или выключено, есть сигнал или нет сигнала. Для того чтобы закодировать эти два состояния, достаточно двух цифр: 0 (нет сигнала) и 1 (есть сигнал).
Таким образом, с помощью комбинации 0 и 1 компьютер (с первого поколения и по сей день) способен воспринимать любую информацию: тексты, формулы, звуки и графику.
Иными словами, компьютеры обычно работают в двоичной системе счисления, состоящей из двух цифр 0 и 1. Все необходимые преобразования (в привычную для нас форму или, наоборот, в двоичную систему счисления) могут выполнить программы, работающие на компьютере.
Обычная для нас десятичная форма счисления состоит из десяти цифр: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. Кстати, числа 10 в этом списке нет: оно состоит из 0 и 1 — чисел, входящих в десятичную систему счисления.
Введение
Для того чтобы было намного проще понять, как представляются файлы в компьютере приведем несколько примеров из жизни с которыми сталкивался каждый:
- Вы хотите перейти дорогу, но дойдя до перекрестка, вы останавливаетесь, потому что загорелся красный свет. После небольшого ожидания цвет светофора меняется на зеленый. Машины тормозят, а вы продолжайте свой путь.
- Вы сильно торопитесь, когда едете на работу или учебу. Участник дорожного движения, который едет спереди двигается на низкой скорости. Вы моргаете ему фарами, он уступает вам дорогу, и вы едете дальше.
А теперь переведем эти ситуации на язык информатики – в данных ситуациях светофор и фары передают код. Красный сигнал говорит нам о том, что нужно остановиться, а моргание фарами это “код” с помощью которого мы просим уступить дорогу. Быть может вы удивитесь, но в основу любого человеческого языка тоже положен код, только символы в нем называются алфавитом. Теперь рассмотрим это определение более подробно. Итак:
Код – набор обозначений, с помощью которого можно представить информацию.
Кодирование – процесс, при котором данные переводятся в код.
По мере развития информационной сферы учеными и разработчиками предлагались многие способы кодирования информации. Некоторые из них остались незамеченными, другими же мы пользуемся до сих пор. В качестве примера приведем азбуку Морзе, разработанную Самюэлем Морзе в 1849 году. Буквы и цифры определяются в ней тремя символами:
- Тире (длинный сигнал);
- Точка (короткий сигнал);
- Пауза или отсутствие сигнала.
Однако наибольшую популярность завоевал “двоичный код”, который предложил использовать Вильгельм Лейбниц в семнадцатом веке. Информация в нем определяется двумя символами – 0 и 1. Разработчикам данный метод кодирования сильно понравился из-за простоты его реализации. 0- это пропуск сигнала, а число 1- его наличие. Именно двоичное представление используется сегодня в ПК и в другой цифровой технике.
Стандарты кодирования графических данных
Чтобы закодировать изображение требуется гораздо больше байт, чем для кодирования символов. Большинство созданных и обработанных изображений, хранящихся в памяти компьютера, разделяют на две основные группы:
- изображения растровой графики;
- изображения векторной графики.
Растровая графика
В растровой графике изображение представлено набором цветных точек. Такие точки называют пикселями (pixel). При увеличении изображения такие точки превращаются в квадратики.
Для кодирования чёрно-белого изображения каждый пиксель кодируется одним битом. К примеру, чёрный цвет — 0, а белый — 1)
Наше прошлое изображение можно закодировать так:
При кодировании нецветных изображений чаще всего применяют палитру из 256 оттенков серого, начиная от белого и заканчивая чёрным. Поэтому для кодирования такой градации достаточно одного байта (28=256).
В кодирования цветных изображений применяют несколько цветовых схем.

На практике, чаще применяют цветовую модель RGB, где соответственно используется три основных цвета: красный, зелёный и синий. Остальные цветовые оттенки получаются при смешивании этих основных цветов.
Таким образом, для кодирования модели из трёх цветов в 256 тонов, получается свыше 16,5 миллионов разных цветовых оттенков. То есть для кодирования применяют 3⋅8=24 бита, что соответствует 3 байтам.
Естественно, что можно использовать минимальное количество бит для кодирования цветных изображений, но тогда может быть образовано и меньшее количество цветовых тонов, в связи, с чем качество изображения существенно понизится.
Чтобы определить размер изображения нужно умножить количество пикселей в ширину на длину количество пикселей и ещё раз умножить на размер самого пикселя в байтах.
I=a*b*i
- а — количество пикселей в ширину;
- b — количество пикселей в длину;
- I – размер одного пикселя в байтах.
К примеру, цветное изображение размером 800⋅600 пикселей, занимает 60000 байт.
Векторная графика
Объекты векторной графики кодируются совершенно по-другому. Здесь изображение состоит из линий, которые могут иметь свои коэффициенты кривизны.












