Реферат на тему: Кодирование информации
В статье «Как научиться правильно писать реферат», я написала о правилах и советах написания лучших рефератов, прочитайте пожалуйста.
Собрала для вас похожие темы рефератов, посмотрите, почитайте:
Строки символов
Рассмотрим еще один структурный тип данных — строковый тип. Строковый тип данных был введен в Турбо Паскале. Он позволяет программировать обработку слов, предложений, текстов.

Строка — это последовательность символов. Каждый символ занимает 1 байт памяти (код ASCII). Количество символов в строке называется ее длиной. Длина строки может находиться в диапазоне от 0 до 255. Строковые величины могут быть константами и переменными.
Строковая константа записывается как последовательность символов, заключенная в апострофы. Например:
‘ Язык программирования ПАСКАЛЬ’
‘ IBM PC — computer’
Строковая переменная описывается в разделе описания переменных следующим образом:
Var Name: String[20]
Параметр длины может и не указываться в описании. В таком случае подразумевается, что он равен максимальной величине — 255. Например:
Var slovo: String
Строковая переменная занимает в памяти на 1 байт больше, чем указанная в описании длина. Дело в том, что один (нулевой) байт содержит значение текущей длины строки. Если строковой переменной не присвоено никакого значения, то ее текущая длина равна нулю. По мере заполнения строки символами ее текущая длина возрастает, но она не должна превышать максимальной по описанию величины.
Символы внутри строки индексируются (нумеруются), начиная с единицы. Каждый отдельный символ идентифицируется именем строки с индексом, заключенным в квадратные скобки. Например:
Name[5], Name[i], slovo[k+1].
Значение индекса может быть задано положительной константой, переменной, выражением целочисленного типа. Оно не должно выходить за границы описания.
Тип String и стандартный тип Char совместимы: строки и символы могут употребляться в одних и тех же выражениях.
Строковые выражения строятся из строковых констант, переменных, функций и знаков операций. Над строковыми данными допустимы операция сцепления и операции отношения.
Операция сцепления (+) применяется для соединения нескольких строк в одну результирующую строку. Сцеплять можно как строковые константы, так и переменные.
В результате получится строка:
Длина результирующей строки не должна превышать 255.
Операции отношения: =, , =, < >производят сравнение двух строк, в результате чего получается логическая величина (true или false). Операции отношения имеют более низкий приоритет, чем операция сцепления. Сравнение строк производится слева направо до первого несовпадающего символа, и та строка считается больше, в которой первый несовпадающий символ имеет больший номер в таблице символьной кодировки.
Если строки имеют различную длину, но в общей части символы совпадают, считается, что более короткая строка меньше, чем более длинная. Строки равны, если они полностью совпадают по длине и содержат одни и те же символы.

Функции и процедуры
Функция Copy(S, Poz, N) выделяет из строки S подстроку длиной N символов, начиная с позиции Poz. N и Роz — целочисленные выражения.

Функция Concat (SI, S2, . . ., SN) выполняет сцепление (конкатенацию) строк S1. SN в одну строку.
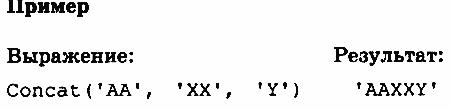
Функция Length (S) определяет текущую длину строки S. Результат — значение целочисленного типа.

Функция Pos (SI, S2) обнаруживает первое появление в строке S2 подстроки S1. Результат — целое число, равное номеру позиции, где находится первый символ подстроки S1. Если в S2 не обнаружена подстрока S1, то результат равен 0.

Процедура Delete (S, Poz, N) удаляет N символов из строки S, начиная с позиции Poz.

В результате выполнения процедуры уменьшается текущая длина строки в переменной S.
Процедура Insert (SI, S2, Poz) выполняет вставку строки S1 в строку S2, начиная с позиции Poz.

Примеры программ обработки строк

Пример 1. Составить программу, формирующую символьную строку, состоящую из N звездочек (N — целое число, 1 ≤ N ≤ 255).

здесь строковой переменной А вначале присваивается значение пустой строки, обозначаемой двумя апострофами (‘ ‘). Затем к ней присоединяются звездочки.
Пример 2. В символьной строке подсчитать количество цифр, предшествующих первому символу ‘ ! ‘.

В этой программе переменная К играет роль счетчика цифр, а переменная I — роль параметра цикла. Цикл закончит выполнение при первом же выходе на символ ‘ ! ‘ или если в строке такого символа нет, то при выходе на конец строки. Символ S[I] является цифрой, если истинно отношение: ‘O’ ≤ S[I] ≤ ‘9’.

Вопросы и задания
1. Как в программе обозначается строковая константа, как определяется строковая переменная?
2. Какой может быть максимальная длина строки?
3. Составьте программу получения из слова «дисковод» слова «воск», используя операцию сцепления и функцию Сору.
4. Составьте программу получения слова «правило» из слова «операция», используя процедуры Delete, Insert.
5. В данном слове замените первый и последний символы на символ ‘*’.
6. В данном слове произведите обмен первого и последнего символов.
7. К данному слову присоедините столько символов ‘!’, сколько в нем имеется букв (например, из строки ‘УРА’ надо получить ‘УРА. ‘).
8. В данной строке вставьте пробел после каждого символа.
9. Переверните введенную строку (например, из ‘ДИСК’ должно получиться ‘КСИД’).
10. В данной строке удалите все пробелы.
11. Строка представляет собой запись целого числа. Составьте программу ее перевода в соответствующую величину целого типа.
Единая коллекция цифровых образовательных ресурсов

1) тренажер «Интерактивный задачник. Раздел «Представление символьной информации»» (N 119265).
http://sc.edu.ru/catalog/res/c7f4d16f-4956-41fe-b3a4-562ee67db716/? — Карточка ресурса на портале Единой коллекции ЦОР
Текстовое значение
Кодирование и обработка текстовой информации Уже с 60-х годов прошлого столетия, компьютеры всё больше стали использовать для обработки текстовой информации. Для кодирования текстовой информации в компьютере применяется двоичное кодирование, т.е. представление текста в виде последовательности 0 и 1. Чтобы выразить текст числом, каждая буква сопоставляется с числовым значением. Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111.
Текстовая информация состоит из символов: букв, цифр, знаков препинания и др. Одного байта достаточно для хранения 256 различных значений, что позво ляет размещать в нем любой из алфавитно-цифровых символов. Первые 128 сим волов (занимающие семь младших бит) стандартизированы с помощью кодировки ASCII (American Standart Code for Information Interchange). Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 0000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Самым распространенным, но не единственным видом кодирования является код ASCII. В соответствии с этим стандартом, знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальных кодировок применяются значения 128−255. В разных национальных кодировках одному и тому же коду соответствуют различные символы. К примеру, существует 5 кодировочных таблиц для русских букв (Windows, MS-DOS, Mac, ISO, КОИ – 8). Поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой.
Первоначально в кодах ASCII было 7 бит информации. В последующем ее расширили до 8-битной (1 байт) кодировки. Обьем 7-битного кодирования по сравнению с 8-битным в 2 раза меньше. 2 7 =128 < 2 8 =256.
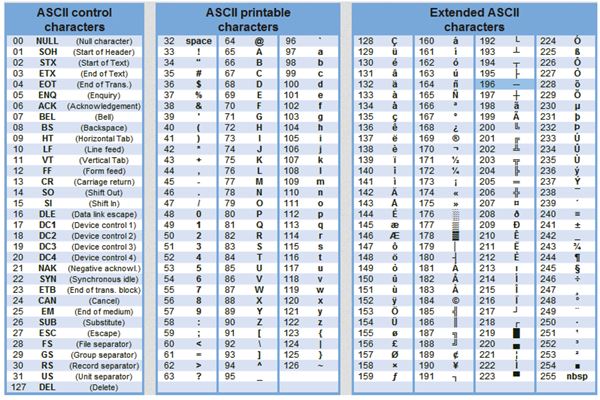
Таблица стандартной и альтернативной частей кодов ASCII
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица СР1251, которая используется в операционных системах семейства Windows фирмы Microsoft. Во всех современных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 65536 различных символов.
Поиск в символьных строках
Существуют функции для поиска подстроки (и отдельного символа) в строке. Им нужно передать образец для поиска и строку, в которой надо искать:

Функция позиция возвращает целое число — номер символа, с которого начинается образец (буква «с») в строке s. Если образец встречается в строке несколько раз, функция находит первый из них. В языке Паскаль функция pos (от англ. position — позиция, расположение) работает точно так же.
Выясните экспериментально, какое значение возвращает функция позиция (pos), если образец для поиска не найден в строке.
Как можно найти вторую букву «с» с начала строки?
Вводится строка, в которой сначала записана фамилия человека, а затем через пробел — его имя, например ‘Семёнов Андрей’.
Запишите операторы, которые позволяют:
а) найти номер пробела, разделяющего фамилию и имя, и записать его в переменную р;
б) выделить из строки фамилию и записать её в переменную fam;
в) выделить из строки имя и записать его в переменную name;
г) приписать перед фамилией первую букву имени, точку и пробел.
Введение
Для того чтобы было намного проще понять, как представляются файлы в компьютере приведем несколько примеров из жизни с которыми сталкивался каждый:
- Вы хотите перейти дорогу, но дойдя до перекрестка, вы останавливаетесь, потому что загорелся красный свет. После небольшого ожидания цвет светофора меняется на зеленый. Машины тормозят, а вы продолжайте свой путь.
- Вы сильно торопитесь, когда едете на работу или учебу. Участник дорожного движения, который едет спереди двигается на низкой скорости. Вы моргаете ему фарами, он уступает вам дорогу, и вы едете дальше.
А теперь переведем эти ситуации на язык информатики – в данных ситуациях светофор и фары передают код. Красный сигнал говорит нам о том, что нужно остановиться, а моргание фарами это “код” с помощью которого мы просим уступить дорогу. Быть может вы удивитесь, но в основу любого человеческого языка тоже положен код, только символы в нем называются алфавитом. Теперь рассмотрим это определение более подробно. Итак:
Код – набор обозначений, с помощью которого можно представить информацию.
Кодирование – процесс, при котором данные переводятся в код.
По мере развития информационной сферы учеными и разработчиками предлагались многие способы кодирования информации. Некоторые из них остались незамеченными, другими же мы пользуемся до сих пор. В качестве примера приведем азбуку Морзе, разработанную Самюэлем Морзе в 1849 году. Буквы и цифры определяются в ней тремя символами:
- Тире (длинный сигнал);
- Точка (короткий сигнал);
- Пауза или отсутствие сигнала.
Однако наибольшую популярность завоевал “двоичный код”, который предложил использовать Вильгельм Лейбниц в семнадцатом веке. Информация в нем определяется двумя символами – 0 и 1. Разработчикам данный метод кодирования сильно понравился из-за простоты его реализации. 0- это пропуск сигнала, а число 1- его наличие. Именно двоичное представление используется сегодня в ПК и в другой цифровой технике.
Обработка информации на компьютере: основные этапы
Компьютер изначально был задуман для автоматизации процессов обработки информации. Он устроен соответствующим образом, чтобы иметь все возможности для успешного выполнения своего предназначения.
Для того чтобы обрабатывать в компьютере информацию, с ней необходимо делать следующие основные операции:
1) вводить информацию в компьютер:

Эта операция нужна для того, чтобы компьютеру было что обрабатывать. Без возможности ввода информации в компьютер он становится как бы вещью в себе.

2) хранить введенную информацию в компьютере:
Очевидно, что если дать возможность вводить информацию в компьютер, то надо также иметь возможность эту информацию в нем хранить, и затем использовать в процессе обработки.

3) обрабатывать введенную информацию:
Здесь надо понимать, что для обработки введенной информации нужны определенные алгоритмы обработки, иначе ни о какой обработке информации речи быть не может. Компьютер должен быть снабжен такими алгоритмами и должен уметь их применять к вводимой информации с тем, чтобы «правильно» преобразовывать ее в выходные данные.
4) хранить обработанную информацию
Так же как и с хранением введенной информации, в компьютере должны храниться результаты его работы, результаты обработки входных данных с тем, чтобы в дальнейшем ими можно было бы воспользоваться.
5) выводить информацию из компьютера

Эта операция позволяет вывести результаты обработки информации в удобочитаемом для пользователей виде. Именно эта операция дает возможность воспользоваться результатами обработки информации на компьютере. Иначе эти результаты обработки так и остались бы внутри компьютера, что сделало бы их получение совершенно бессмысленным.
Дискретная форма представления звуковой информации
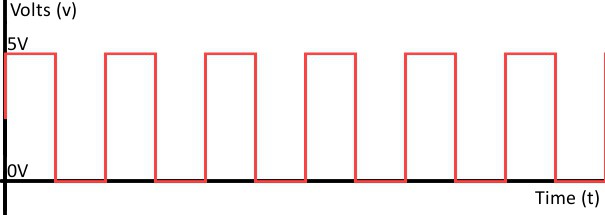
Если же говорить о дискретном способе, то в этом случае величина может принимать только ограниченное количество значений. При этом изменение происходит скачкообразно. Закодировать дискретно можно не только звуковую, но и графическую информацию. Что касается и аналоговой формы, кстати.
Аналоговая звуковая информация хранится на виниловых пластинках, например. А вот компакт-диск уже является дискретным способом представления информации звукового характера.
В самом начале мы говорили о том, что компьютер воспринимает всю информацию на машинном языке. Для этого информация кодируется в форме последовательности электрических импульсов – нулей и единиц. Кодирование звуковой информации не является исключением из этого правила. Чтобы обработать на компьютере звук, его для начала нужно превратить в ту самую последовательность. Только после этого над потоком или единичным звуком могут совершаться операции.
Когда происходит процесс кодирования, поток подвергается временной дискретизации. Звуковая волна непрерывна, она развивается на малые участки времени. Значение амплитуды при этом устанавливается для каждого определенного интервала отдельно.











