Что такое бот в компьютере
Bot – это программа, в заданном пользователем или автоматическом режиме выполняющая ряд действий с помощью интерфейсов, обычно используемых людьми.
Слово «бот» является сокращением от robot – чешской лексемы, обозначающей автоматическое устройство, выполняющее ряд механических операций согласно алгоритму.
Также под ботом понимается виртуальная программа, которая выполняет повторяемые однообразные действия в сети. Она может делать это с высокой скоростью в отличие от живого человека.
Бот — что это такое простыми словами
Бот – это программа, которая в автоматическом или заданном пользователем режиме выполняет ряд действий через интерфейсы, которые обычно используются людьми.
Слово «Бот» — калька с английского bot. Это сокращение от robot – чешской лексемы для обозначения автоматического устройства, выполняющего механические операции согласно алгоритму.
В свою очередь, под ботом принято понимать виртуальную программу, которая выполняет однообразные повторяемые действия в интернете. Она умеет делать это с высокой скоростью, чем превосходит живого человека.
Что такое интернет-боты
Вы найдете интернет-ботов везде. Боты «тусуются» на сайтах и в приложениях для обмена сообщениями, часто прячась за фальшивыми персонами, скрываясь в темных местах поджидая момента для атаки.
Вот некоторые из наиболее распространенных ботов, с которыми вы столкнетесь при просмотре веб-страниц.
Виды ботов, с помощью которых можно заработать?
- Боты-скупщики – покупают что-либо у пользователя за реальные или виртуальные деньги.
- Чат-боты для выполнения заданий – пользователь выполняет задания, например, в социальных сетях, после чего бот проверяет выполненную работу и оплачивает задание.
- Боты с партнерскими программами – пользователь продвигает товар или услугу в интернете и получает за это процент от прибыли или фиксированное вознаграждение.
- Чат-Боты-опросники – пользователь получает деньги за прохождение опросов или тестов.
Это основные виды ботов, с помощью которых может заработать каждый желающий.
Аренда и продажа ботнетов
Злоумышленникам и нечистым на руку бизнесменам совсем не обязательно своими силами создавать ботнет «с нуля». Ботнеты самых разных размеров и производительности они могут купить или арендовать у хакеров – например, обратившись на специализированные форумы.
Стоимость готового ботнета, равно как и стоимость его аренды, напрямую зависит от количества входящих в него компьютеров. Наибольшей популярностью готовые ботнеты пользуются на англоязычных форумах.
Аренда почтового ботнета со скоростью рассылки порядка 1000 спамовых писем в минуту (при 100 находящихся в онлайне зомби-машинах) обойдется примерно в 2000 долларов в месяц.
Маленькие ботнеты, состоящие из нескольких сотен ботов, стоят от 200 до 700 долларов. При этом средняя цена одного бота составляет примерно 50 центов. Более крупные ботнеты стоят больших денег.
Зомби-сеть Shadow, которая была создана несколько лет назад 19-летним хакером из Голландии, насчитывала более 100 тысяч компьютеров, расположенных по всему миру, продавалась за 25 000 евро. За эти деньги можно купить небольшой домик в Испании, однако преступник из Бразилии предпочел приобрести ботнет.
Чат боты — что это такое на наглядных примерах
Как говорится, лучше один раз увидеть, чем сто раз услышать. Поэтому давайте рассмотрим несколько примеров чат-ботов крупных компаний с подробным указанием целей создания.
Чат бот популярного такси «Максим»
- Платформа: Telegram.
- Цель: быстрый заказ машины без звонка оператору и без приложения.
В ближайшее время планируется добавить в сервис функционал, позволяющий информировать пользователей о состоянии заказа прямо в мессенджере.
Сейчас этот чат-бот выглядит так:

Бот Aviasales
- Платформы: Telegram и корпоративный мессенджер Slack.
- Цель: осуществлять поиск билетов и отелей со скидками без необходимости устанавливать приложение.
Представители компании утверждают, что эффективней всего работают алертботы, которые держат клиентов в курсе текущих цен (по их предварительному запросу).
Взаимодействие осуществляется с помощью специальных команд /fly и /hotel.
Сейчас этот чат-бот выглядит так:

Бот каршеринга YouDrive
- Платформа: Telegram.
- Цели:
- Снизить количество обращений в колл-центр;
- Упростить и ускорить процесс уведомления о возможных проблемах;
- Ускорить скорость обработки данных и сократить время ожидания для клиента.
Сценарии и функции этого сервиса задавались разработчиками на основе частых вопросов клиентов: от бального «как завести автомобиль» до более существенного «что делать при попадании в ДТП».
Кроме того, такой виртуальный помощник осуществляет распределение заявок от пользователей в соответствующий отдел, что ускоряет решение проблем клиентов.

Можно приводить много примеров. Но думаю теперь вам стало примерно понятно, чат бот — что это и зачем.
Виды машинного обучения
Распознавание интентов, выделение именованных сущностей, поиск в документах и поиск мест в документе, которые соответствуют семантике вопроса – все это без машинного обучения, без некого статистического анализа реализовать невозможно. Поэтому в основе современных чат-ботов лежит машинное обучение –методы задач, аппроксимации некой скрытой закономерности, которая есть в больших массивах данных и выявление этих закономерностей. Такой подход имеет смысл применять, когда закономерности, задачи есть, но простую формулу, формализм для описания этой закономерности придумать невозможно.
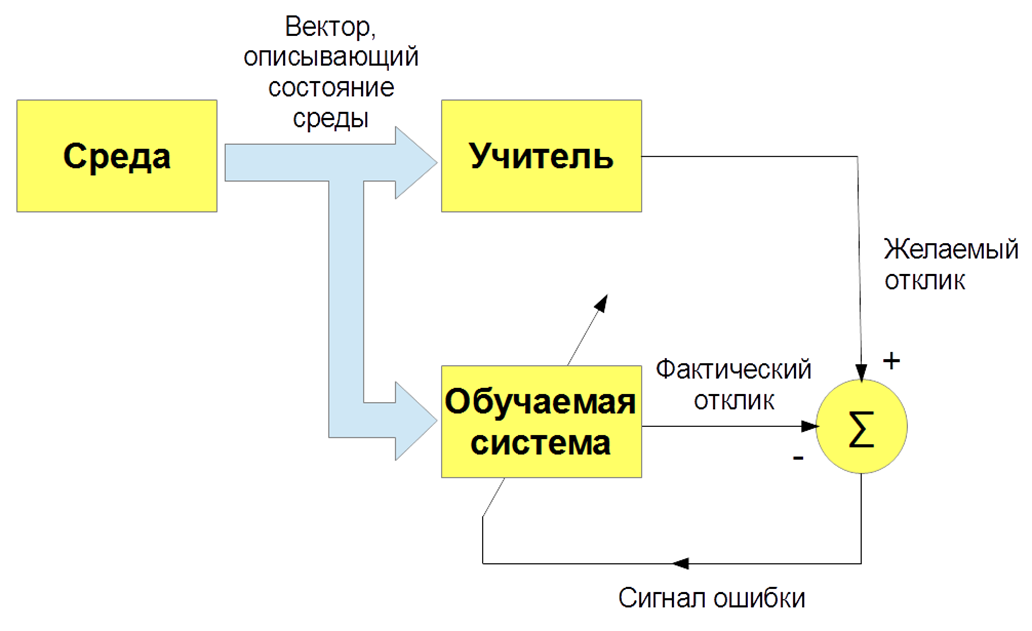
Существует несколько видов машинного обучения: с учителем (supervised learning), без учителя (unsupervised learning), с подкреплением (reinforcement learning). Нас интересует, прежде всего, задача обучения с учителем – когда есть входные изображения и указания (метки) учителя и классификация этих изображений. Либо входные речевые сигналы и их классификация. И мы учим нашего бота, наш алгоритм воспроизводить работу учителя.
О’кей, вроде бы все круто. А как научить компьютер понимать тексты? Текст – это сложный объект, и как буквы превратить в числа и придумать векторное описание текста? Есть самый простой вариант – «мешок слов». Мы задаем словарь всей системы, например, все слова, которые есть в русском языке, и формулируем вот такие очень разреженные вектора с частотами слов. Этот вариант хорош для простых вопросов, но для более сложных задач он не годится.
В 2013 году произошла в некотором роде революция в моделировании слов и текстов. Томас Миколов предложил специальный подход эффективного векторного представления слов, основанный на дистрибутивной гипотезе. Если разные слова встречаются в одном и том же контексте, значит, они имеют что-то общее. Например: «Ученые провели анализ алгоритмов» и «Ученые провели исследование алгоритмов». Так, «Анализ» и «исследование» являются синонимами и обозначают примерно одно и то же. Поэтому можно научить специальную нейронную сеть прогнозировать слово по контексту, либо контекст по слову.
Наконец, как мы обучаем? Для того чтобы обучить бота понимать интенты, истинные намерения, нужно вручную разметить кучу текстов с помощью специальных программ. Чтобы научить бота понимать именованные сущности – имя человека, название фирмы, локация – тоже нужно размещать тексты. Соответственно, с одной стороны, алгоритм обучения с учителем наиболее эффективный, он позволяет создавать эффективную распознающую систему, но, с другой стороны, возникает проблема: нужны большие размеченные дата-сеты, а это делать дорого и долго. В процессе разметки дата-сетов могут быть ошибки, вызванные человеческим фактором.
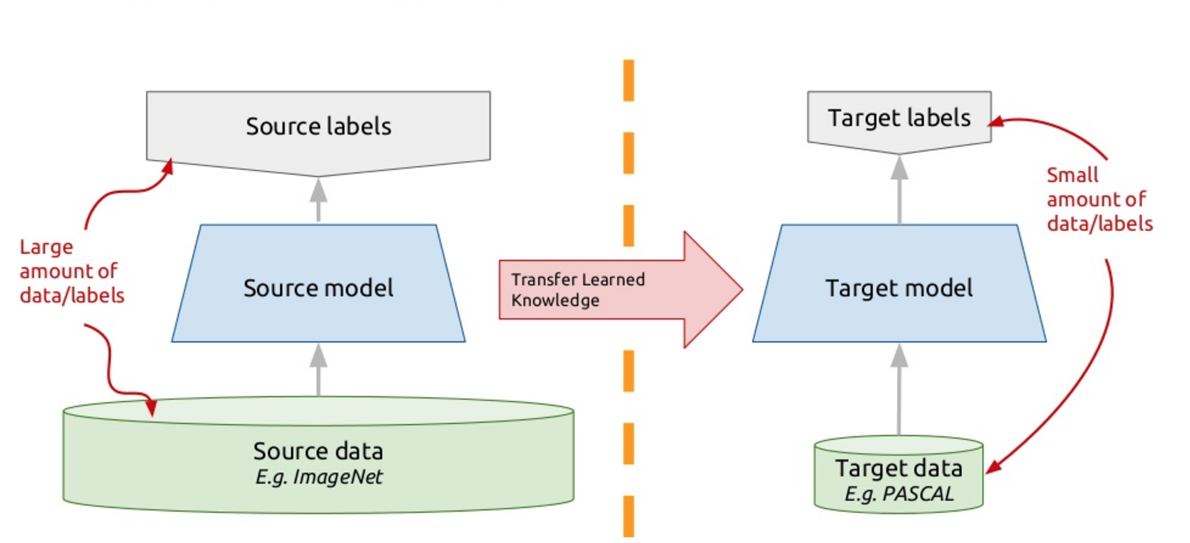
Для решения этой проблемы в современных чат-ботах применяют так называемый перенос обучения – transfer learning. Те, кто знают много иностранных языков, наверняка замечали такой нюанс, что очередной иностранный язык учить легче, чем первый. Собственно, когда вы изучаете какую-то новую задачу, то пытаетесь использовать для этого свой прошлый опыт. Так вот, transfer learning (перенос обучения) как раз основан на этом принципе: мы обучаем алгоритм решать одну задачу, для которой у нас есть большой дата-сет. А потом этот обученный алгоритм (то есть берем алгоритм не с нуля, а обученный решению другой задачи), дообучаем решать нашу задачу. Таким образом, мы получаем эффективное решение с использованием небольших различных данных.
Одна из таких моделей – это ELMo (Embeddings from Language Models), как ELMo из Улицы Сезам. Мы используем рекуррентные нейронные сети, они имеют память и могут обрабатывать последовательности. Например: «Программист Вася любит пиво. Каждый вечер после работы он заходит в «Джонатан» и пропускает бокал-другой». Так вот, он – это кто? Он – это вечер, он – это пиво, или он – это программист Вася? Нейронная сеть, которая обрабатывает слова, как элементы последовательности, учитывая контекст, рекуррентная нейронная сеть, может понять взаимосвязи, решить эту задачу и выделить какую-то семантику.
Мы обучаем такую глубокую нейронную сеть моделировать тексты. Формально это задача обучения с учителем, но учителем у нас выступает сам неразмеченный текст. Следующее слово в тексте является учителем по отношению ко всем предыдущим. Таким образом, можем использовать гигабайты, десятки гигабайт текстов, обучать эффективные модели, которые выделяет семантика в этих текстах. И потом, когда мы используем модель Embeddings from Language Models (ELMo) в режиме вывода, мы подаем слово с учетом контекста. Не просто stick, a let’s stick. Смотрим, что нейронная сеть генерирует в этот момент времени, какие сигналы. Эти сигналы мы катанируем и получаем векторное представление слова в конкретном тексте, с учетом его конкретной сематической значимости.
В анализе текстов есть еще одна особенность: когда решается задача машинного перевода, один и тот же смысл одним количеством слов на английском может быть передан и другим количеством слов на русском. Соответственно, идет не линейное сопоставление, и нам необходим механизм, который бы акцентировал внимание на тех или иных кусочках текста, чтобы адекватно их перевести на другой язык. Изначально внимание было придумано для машинного перевода – задача преобразования одного текста в другой с обычными рекуррентными нейронными системами. В это мы добавляем специальный слой внимания, который в каждый момент времени оценивает, какое слово нам сейчас важно.
Но потом ребята из Google подумали, а почему не использовать механизм внимания вообще без рекуррентных нейронных сетей – только внимание. И придумали архитектуру, которая называется трансформер (BERT (Bidirectional Encoder Representations from Transformers)).
На базе такой архитектуры, когда есть только многоголовое внимание, были придуманы специальные алгоритмы, которые тоже могут анализировать взаимосвязи слов в текстах, взаимосвязи текстов друг с другом – как это делает ELMo, только более хитро. Во-первых, это более крутая и сложная сеть. Во-вторых, мы решаем одновременно две задачи, а не одну, как в случае с ELMo – языковое моделирование, прогнозирование. Мы пытаемся восстановить скрытые слова в тексте и восстановить связи между текстами. То есть, допустим: «Программист Вася любит пиво. Каждый вечер он ходит в бар». Два текста связаны между собой. «Программист Вася любит пиво. Журавли осенью улетают на юг» – это два несвязанных текста. Опять-таки, эту информацию можно извлечь из неразмеченных текстов, обучить BERT и получить очень крутые результаты.
Об этом в ноябре прошлого года была опубликована статья «Attention Is All You Need», которую очень я очень рекомендую прочитать. На данный момент это является самым крутым результатом в области анализа текстов для решения разных задач: для классификации текста (распознавание тональности, намерений пользователя); для вопросно-ответных систем; для распознавания именованных сущностей и так далее. Современные диалоговые системы используют BERT, предобученные контекстные эмбеддинги (ELMo или BERT) для того, чтобы понять, что хочет пользователь. Но модуль управления диалогом по-прежнему часто проектируется на основе правил, потому что конкретный диалог может быть очень зависим от предмета или даже от задачи.











