4. Кодирование информации
В настоящее время во всех вычислительных машинах информация представляется с помощью электрических сигналов. При этом возможны две формы ее представления – в виде непрерывного сигнала (с помощью сходной величины – аналога) и в виде нескольких сигналов (с помощью набора напряжений, каждое из которых соответствует одной из цифр представляемой величины).
Первая форма представления информации называется аналоговой, или непрерывной. Величины, представленные в такой форме, могут принимать принципиально любые значения в определенном диапазоне. Количество значений, которые может принимать такая величина, бесконечно велико. Отсюда названия – непрерывная величина и непрерывная информация. Слово непрерывность отчетливо выделяет основное свойство таких величин – отсутствие разрывов, промежутков между значениями, которые может принимать данная аналоговая величина. При использовании аналоговой формы для создания вычислительной машины потребуется меньшее число устройств (каждая величина представляется одним, а не несколькими сигналами), но эти устройства будут сложнее (они должны различать значительно большее число состояний сигнала). Непрерывная форма представления используется в аналоговых вычислительных машинах (АВМ). Эти машины предназначены в основном для решения задач, описываемых системами дифференциальных уравнений: исследования поведения подвижных объектов, моделирования процессов и систем, решения задач параметрической оптимизации и оптимального управления. Устройства для обработки непрерывных сигналов обладают более высоким быстродействием, они могут интегрировать сигнал, выполнять любое его функциональное преобразование и т. п. Однако из-за сложности технической реализации устройств выполнения логических операций с непрерывными сигналами, длительного хранения таких сигналов, их точного измерения АВМ не могут эффективно решать задачи, связанные с хранением и обработкой больших объемов информации.
Вторая форма представления информации называется дискретной (цифровой). Такие величины, принимающие не все возможные, а лишь вполне определенные значения, называются дискретными (прерывистыми). В отличие от непрерывной величины, количество значений дискретной величины всегда будет конечным. Дискретная форма представления используется в цифровых электронно-вычислительных машинах (ЭВМ), которые легко решают задачи, связанные с хранением, обработкой и передачей больших объемов информации.
Для автоматизации работы ЭВМ с информацией, относящейся к различным типам, очень важно унифицировать их форму представления – для этого обычно используется прием кодирования.
Кодирование – это представление сигнала в определенной форме, удобной или пригодной для последующего использования сигнала. Говоря строже, это правило, описывающее отображение одного набора знаков в другой набор знаков. Тогда отображаемый набор знаков называется исходным алфавитом, а набор знаков, который используется для отображения, – кодовым алфавитом, или алфавитом для кодирования. При этом кодированию подлежат как отдельные символы исходного алфавита, так и их комбинации. Аналогично для построения кода используются как отдельные символы кодового алфавита, так и их комбинации.
Совокупность символов кодового алфавита, применяемых для кодирования одного символа (или одной комбинации символов) исходного алфавита, называется кодовой комбинацией, или, короче, кодом символа. При этом кодовая комбинация может содержать один символ кодового алфавита.
Символ (или комбинация символов) исходного алфавита, которому соответствует кодовая комбинация, называется исходным символом.
Совокупность кодовых комбинаций называется кодом.
Взаимосвязь символов (или комбинаций символов, если кодируются не отдельные символы исходного алфавита) исходного алфавита с их кодовыми комбинациями составляет таблицу соответствия (или таблицу кодов).
В качестве примера можно привести систему записи математических выражений, азбуку Морзе, морскую флажковую азбуку, систему Брайля для слепых и др.
В вычислительной технике также существует своя система кодирования – она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1 (используется двоичная система счисления). Эти знаки называются двоичными цифрами, или битами (binary digital).

Если увеличивать на единицу количество разрядов в системе двоичного кодирования, то увеличивается в два раза количество значений, которое может быть выражено в данной системе. Для расчета количества значений используется следующая формула:
где N – количество независимо кодируемых значений,
а m – разрядность двоичного кодирования, принятая в данной системе.
Например, какое количество значений (N) можно закодировать 10-ю разрядами (m)?
Для этого возводим 2 в 10 степень (m) и получаем N=1024, т. е. в двоичной системе кодирования 10-ю разрядами можно закодировать 1024 независимо кодируемых значения.
Кодирование текстовой информации
Для кодирования текстовых данных используются специально разработанные таблицы кодировки, основанные на сопоставлении каждого символа алфавита с определенным целым числом. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы. Но не все так просто, и существуют определенные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а в настоящее время, наоборот, вызваны изобилием одновременно действующих и противоречивых стандартов. Практически для всех распространенных на земном шаре языков созданы свои кодовые таблицы. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, что до сих пор пока еще не стало возможным.
Кодирование графической информации
Кодирование графической информации основано на том, что изображение состоит из мельчайших точек, образующих характерный узор, называемый растром. Каждая точка имеет свои линейные координаты и свойства (яркость), следовательно, их можно выразить с помощью целых чисел – растровое кодирование позволяет использовать двоичный код для представления графической информации. Черно-белые иллюстрации представляются в компьютере в виде комбинаций точек с 256 градациями серого цвета – для кодирования яркости любой точки достаточно восьмиразрядного двоичного числа.
Для кодирования цветных графических изображений применяется принцип декомпозиции (разложения) произвольного цвета на основные составляющие. При этом могут использоваться различные методы кодирования цветной графической информации. Например, на практике считается, что любой цвет, видимый человеческим глазом, можно получить путем механического смешивания основных цветов. В качестве таких составляющих используют три основных цвета: красный (Red, R), зеленый (Green, G) и синий (Blue, B). Такая система кодирования называется системой RGB.
На кодирование цвета одной точки цветного изображения надо затратить 24 разряда. При этом система кодирования обеспечивает однозначное определение 16,5 млн различных цветов, что на самом деле близко к чувствительности человеческого глаза. Режим представления цветной графики с использованием 24 двоичных разрядов называется полноцветным (True Color).
Каждому из основных цветов можно поставить в соответствие дополнительный цвет, то есть цвет, дополняющий основной цвет до белого. Соответственно дополнительными цветами являются: голубой (Cyan, C), пурпурный (Magenta, M) и желтый (Yellow, Y). Такой метод кодирования принят в полиграфии, но в полиграфии используется еще и четвертая краска – черная (Black, K). Данная система кодирования обозначается CMYK, и для представления цветной графики в этой системе надо иметь 32 двоичных разряда. Такой режим называется полноцветным (True Color).
Если уменьшать количество двоичных разрядов, используемых для кодирования цвета каждой точки, то можно сократить объем данных, но при этом диапазон кодируемых цветов заметно сокращается. Кодирование цветной графики 16-разрядными двоичными числами называется режимом High Color.
Кодирование звуковой информации
Приемы и методы кодирования звуковой информации пришли в вычислительную технику наиболее поздно и до сих пор далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, хотя можно выделить два основных направления.
Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармоничных сигналов разной частоты, каждый из которых представляет правильную синусоиду, а следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства – аналогово-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях часть информации теряется, поэтому качество звукозаписи обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с «окрасом», характерным для электронной музыки.
Метод таблично-волнового синтеза (Wave-Table) лучше соответствует современному уровню развития техники. Имеются заранее подготовленные таблицы, в которых хранятся образцы звуков для множества различных музыкальных инструментов. В технике такие образцы называются сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения. Поскольку в качестве образцов используются «реальные» звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
Единицы измерения данных
Наименьшей единицей измерения информации является байт, равный восьми битам. Одним байтом можно закодировать одно из 256 значений. Существуют и более крупные единицы, такие как килобайт (Кбайт), мегабайт (Мбайт), гигабайт (Гбайт) и терабайт (Тбайт).
1 Кбайт = 1024 байт
1 Мбайт = 1024 Кбайт = 2 20 байт
1 Гбайт = 1024 Мбайт = 2 30 байт
1 Тбайт = 1024 Гбайт = 2 40 байт
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРес
Какие бывают символы?

В роли символов для компьютера выступают не только русские, английские и другие буквы, но и еще знаки препинания, а также другие знаки. Даже пробел, которым мы разделяем слова при печатании на компьютере, устройство воспринимает как символ. Чем-то очень напоминает высшую математику, ведь там, по мнению многих профессоров, ноль имеет двойное значение: он и является числом, и одновременно ничего не обозначает. Даже для философов вопрос пробела в тексте может стать актуальной проблемой. Шутка, конечно, но, как говорится, в каждой шутке есть доля правды.
Кодирование текстовой информации и таблицы кодировок
Таблица кодировки — это место, где прописано какому символу какой код относится. Все таблицы кодировки являются согласованными — это нужно, чтобы не возникало путаницы между документами, закодированными по одной таблице, но на разных устройствах.
На сегодняшний день существует множество таблиц кодировок. Из-за этого часто возникают проблемы с переносом текстовых документов между устройствами. Так получается, что если текстовая информация была закодирована по одной какой-то таблице, то и раскодирована она может быть только по этой таблице. Если попытаться раскодировать другой таблицей, то в результате получим только набор непонятных символов, но никак не читабельный текст.
Наиболее популярные таблицы кодировки:
- ASCII,
- MS-DOS,
- ISO,
- Windows,
- КОИ8,
- CP866,
- Mac,
- CP 1251,
- Unicode,
- и др.
Текстовое значение
Кодирование и обработка текстовой информации Уже с 60-х годов прошлого столетия, компьютеры всё больше стали использовать для обработки текстовой информации. Для кодирования текстовой информации в компьютере применяется двоичное кодирование, т.е. представление текста в виде последовательности 0 и 1. Чтобы выразить текст числом, каждая буква сопоставляется с числовым значением. Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111.
Текстовая информация состоит из символов: букв, цифр, знаков препинания и др. Одного байта достаточно для хранения 256 различных значений, что позво ляет размещать в нем любой из алфавитно-цифровых символов. Первые 128 сим волов (занимающие семь младших бит) стандартизированы с помощью кодировки ASCII (American Standart Code for Information Interchange). Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 0000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Самым распространенным, но не единственным видом кодирования является код ASCII. В соответствии с этим стандартом, знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальных кодировок применяются значения 128−255. В разных национальных кодировках одному и тому же коду соответствуют различные символы. К примеру, существует 5 кодировочных таблиц для русских букв (Windows, MS-DOS, Mac, ISO, КОИ – 8). Поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой.
Первоначально в кодах ASCII было 7 бит информации. В последующем ее расширили до 8-битной (1 байт) кодировки. Обьем 7-битного кодирования по сравнению с 8-битным в 2 раза меньше. 2 7 =128 < 2 8 =256.
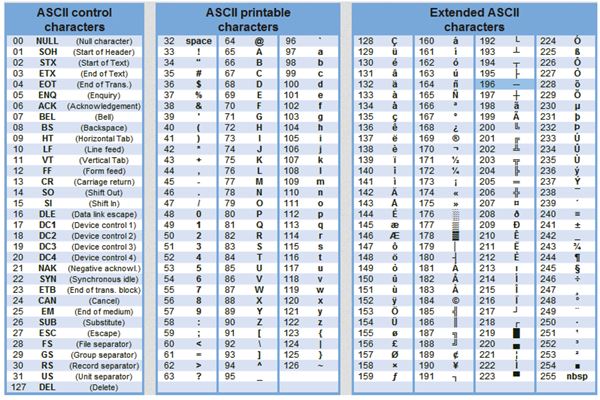
Таблица стандартной и альтернативной частей кодов ASCII
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица СР1251, которая используется в операционных системах семейства Windows фирмы Microsoft. Во всех современных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 65536 различных символов.
Метод координат
Любые данные можно передать с помощью двоичных чисел, в том числе и графические изображение, представляющие собой совокупность точек. Чтобы установить соответствие чисел и точек в бинарном коде, используют метод координат.
Метод координат на плоскости основан на изучении свойств точки в системе координат с горизонтальной осью Ox и вертикальной осью Oy. Точка будет иметь 2 координаты.
Если через начало координат проходит 3 взаимно перпендикулярные оси X, Y и Z, то используется метод координат в пространстве. Положение точки в таком случае определяется тремя координатами.
Система координат в пространстве
Начало
Поскольку я обращаюсь к новичкам в этом вопросе, то не посчитаю зазорным обратиться к Википедии. А там, для обозначения кодирования информации, у нас есть такое определение — процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
Чего мне не хватало в 70-80-е, так это в школе, пусть не на информатике, а, например, на уроках математики — базовой информации по кодированию. Дело в том, что кодированием информации каждый из нас занимается ежесекундно, постоянно и в целом — не концентрируясь на самом кодировании. То есть в быту мы это делаем постоянно. Так как это происходит?
Мимика, жесты, речь, сигналы разного уровня — табличка с надписью, знак на дороге, светофоры, и для современного мира — штрих- и бар-коды, URL, хэш-тэги.
Давайте рассмотрим некоторые более подробно.
Зачем кодировать информацию?
Во-первых, необходимо ответить на вопрос для чего кодировать информацию? Дело в том, что компьютер способен обрабатывать и хранить только лишь один вид представления данных – цифровой. Поэтому любую входящую в него информацию необходимо переводить в цифровой вид.
Чтобы все компьютеры могли однозначно понимать тот или иной текст, необходимо использовать общепринятые стандарты кодирования текста. В прочих случаях потребуется дополнительное перекодирование или несовместимость данных.

ASCII
Самым первым компьютерным стандартом кодирования символов стал ASCII (полное название — American Standart Code for Information Interchange). Для кодирования любого символа в нём использовали всего 7 бит. Как вы помните, что закодировать при помощи 7 бит можно лишь 27 символов или 128 символов. Этого достаточно, чтобы закодировать заглавные и прописные буквы латинского алфавита, арабские цифры, знаки препинания, а так же определенный набор специальных символов, к примеру, знак доллара — «$». Однако, чтобы закодировать символы алфавитов других народов (в том числе и символов русского алфавита) пришлось дополнять код до 8 бит (28=256 символов). При этом, для каждого языка использовалась свой отдельная кодировка.
UNICODE
Нужно было спасать положение в плане совместимости таблиц кодировки. Поэтому, со временем были разработаны новые обновлённые стандарты. В настоящее время наиболее популярной является кодировка под названием UNICODE. В ней каждый символ кодируется с помощью 2-х байт, что соответствует 216=62536 разным кодам.

Кодирование звуков
Звуки появляются из-за колебаний воздуха. У звука есть две величины:
— амплитуда колебания, которая указывает на громкость звука;
— частота колебания, которая указывает на тональность звука.
Звук можно переделать в электрический сигнал, например, микрофоном.
Звук кодируют, после точного интервала времени измеряя размер сигнала и присваивая ему бинарную величину. Чем чаще проводятся эти измерения, тем лучше качество звука.
Пример:
На одном компакт диске, с объемом 700 Мб, может вместиться 80 минут звука CD качества.











