Учитель информатики
Информатика. 9 класса. Босова Л.Л. Оглавление
Ключевые слова:
- постановка задачи
- формализация
- алгоритмизация
- программирование
- отладка и тестирование
Типы машинного обучения: два подхода к обучению
В основе машинного обучения лежат алгоритмы. Сегодня используются два основных типа алгоритмов машинного обучения: контролируемое обучение и самостоятельное обучение. Разница заключается в способе изучения данных для последующего прогнозирования.
- значение цикла обслуживания заказчика;
- выявление аномалий;
- динамическое ценообразование;
- предиктивное управление обслуживанием;
- распознавание образов;
- Разработка рекомендаций.
Сценарий
Построитель моделей может создавать модели машинного обучения для приложения на основе множества различных сценариев.
Сценарий описывает тип прогноза, который нужно сделать с использованием данных. Пример:
- прогнозирование будущего объема продаж продукта на основе исторических данных по продажам;
- классификация тональности как положительной или отрицательной на основе отзывов клиентов;
- определение того, является ли банковская операция мошеннической;
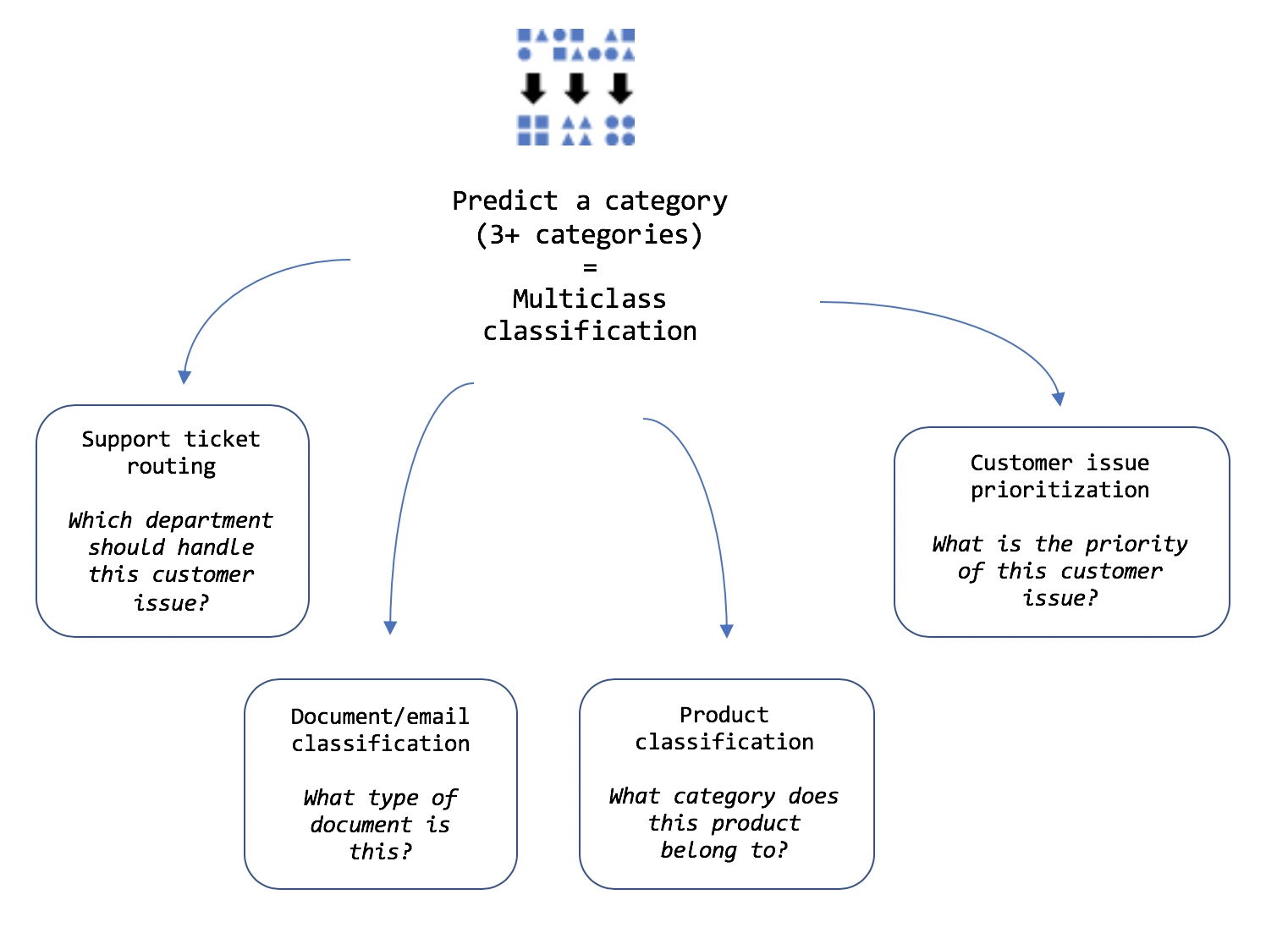
- направление проблем, с которыми обращаются клиенты, на рассмотрение соответствующим сотрудникам компании.
Каждый сценарий сопоставлен с соответствующей задачей Машинного обучения:
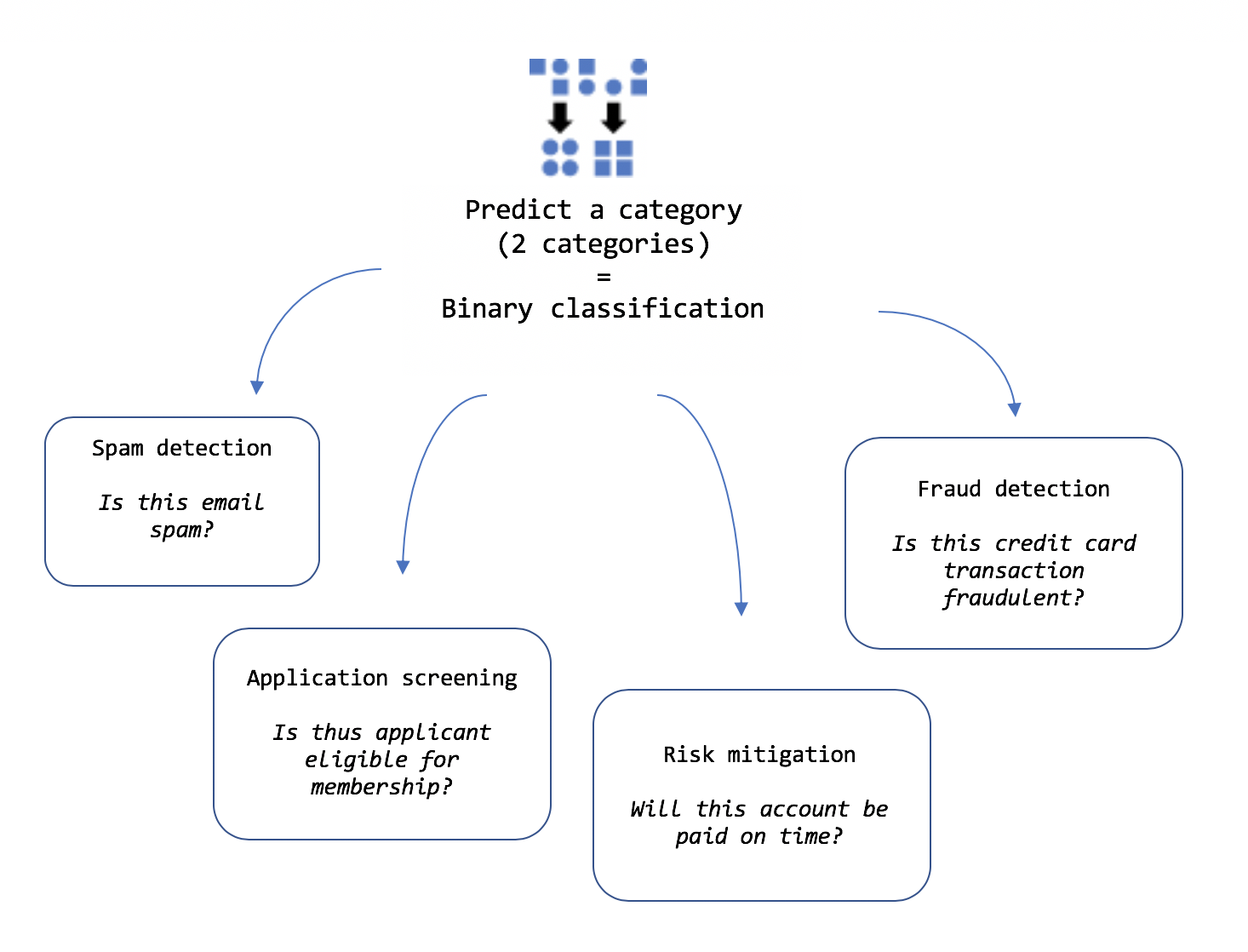
- Двоичная классификация
- Многоклассовая классификация
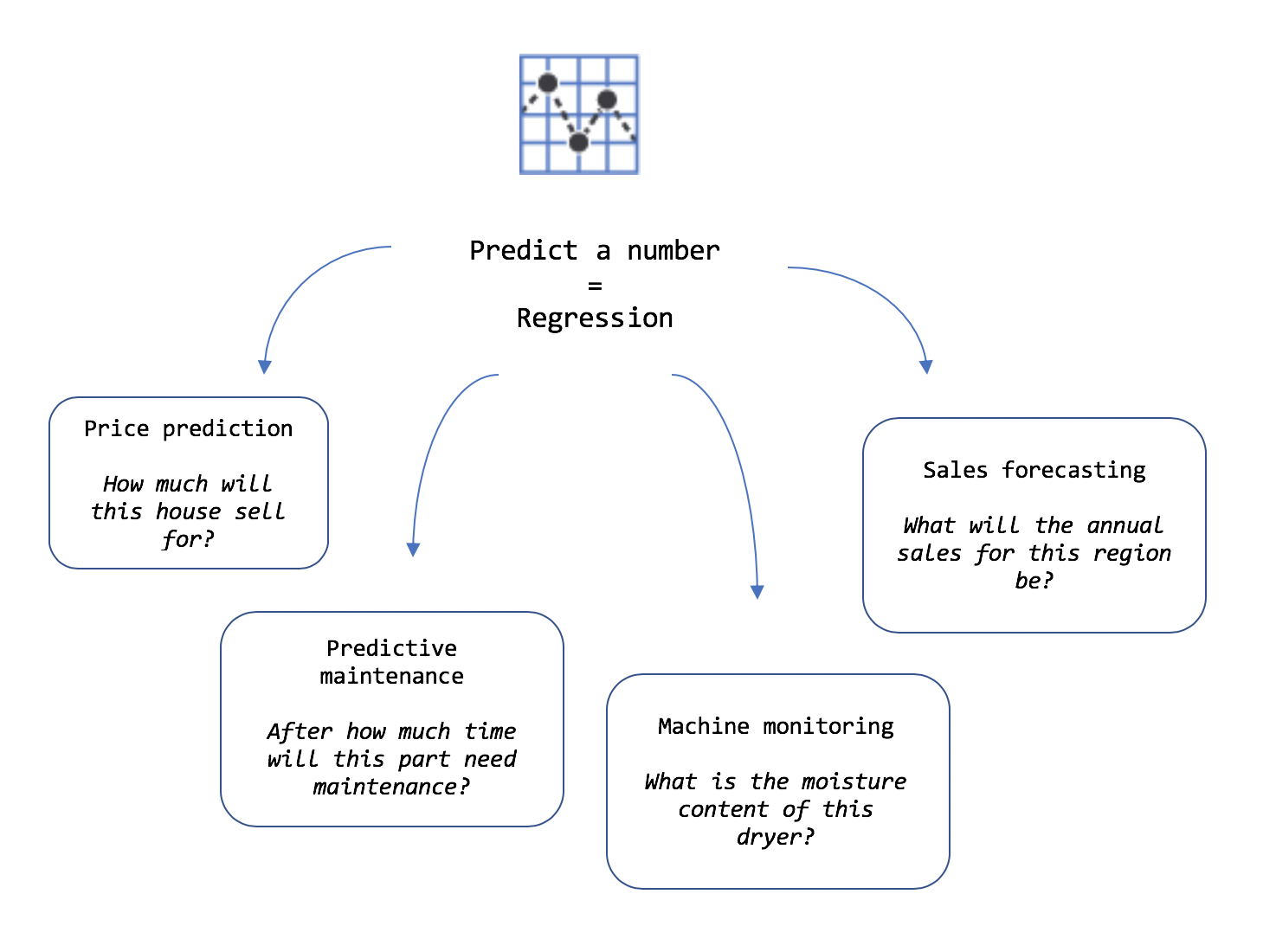
- Регрессия
- Кластеризация
- Обнаружение аномалий
- Функции ранжирования
- Рекомендация
- Прогнозирование
Например, сценарий для классификации тональностей на положительные или отрицательные относится к задаче классификации двоичных файлов.
Дополнительные сведения о различных задачах Машинного обучения, поддерживаемых ML.NET, см. в статье Задачи машинного обучения в ML.NET.
Выбор подходящего сценария машинного обучения
В построителе моделей необходимо выбрать сценарий. Тип сценария зависит от того, какой прогноз вы пытаетесь сделать.
Классификация данных
Классификация используется для разбиения данных по категориям.
Прогнозирование значений
Прогнозирование значений, которое относится к задачам регрессии, используется для прогнозирования чисел.
Классификация изображений
Классификация изображений помогает идентифицировать изображения разных категорий. Например, различные виды рельефа, животных или производственного брака.
Вы можете использовать сценарий классификации, если у вас есть набор изображений и вы хотите классифицировать изображения по различным категориям.
Обнаружение объектов
Обнаружение объектов используется для поиска и классификации сущностей на изображениях по категориям. Например, на изображениях можно находить и идентифицировать людей и автомобили.
Обнаружение объектов можно использовать, если изображения содержат несколько объектов разных типов.
Рекомендация
В сценарии рекомендации прогнозируется список предлагаемых элементов для конкретного пользователя на основе схожести с понравившимися, а также не понравившимися публикациями других пользователей.
Сценарий рекомендаций можно использовать, когда у вас есть набор пользователей и набор «продуктов», таких как элементы для покупки, фильмы, книги или телепередачи, наряду с набором пользовательских «оценок» этих продуктов.
Какие задачи решает машинное обучение?
С помощью машинного обучения ИИ может анализировать данные, запоминать информацию, строить прогнозы, воспроизводить готовые модели и выбирать наиболее подходящий вариант из предложенных.
Особенно полезны такие системы там, где необходимо выполнять огромные объемы вычислений: например, банковский скоринг (расчет кредитного рейтинга), аналитика в области маркетинговых и статистических исследований, бизнес-планирование, демографические исследования, инвестиции, поиск фейковых новостей и мошеннических сайтов.
В Леруа Мерлен используют Big Data и Machine Learning, чтобы находить остатки товара на складах.
В маркетинге и электронной коммерции машинное обучение помогает настроить сервисы и приложения так, чтобы они выдавали персональные рекомендации.
Стриминговый сервис Spotify с помощью машинного обучения составляет для каждого пользователя персональные подборки треков на основе того, какую музыку он слушает.
Сегодня ключевые исследования сфокусированы на разработке машинного обучения с эффективным использованием данных — то есть систем глубокого обучения, которые могут обучаться более эффективно, с той же производительностью, за меньшее время и с меньшими объемами данных. Такие системы востребованы в персонализированном здравоохранении, обучении роботов с подкреплением, анализе эмоций.
Китайский производитель «умных» пылесосов Ecovacs Robotics обучил свои пылесосы распознавать носки, провода и другие посторонние предметы на полу с помощью множества фотографий и машинного обучения.
«Умная» камера на базе микрокомпьютера Raspberry Pi 3B+ с помощью фреймворка TensorFlow Light научилась распознавать улыбку и делать снимок ровно в этот момент, а также — выполнять голосовые команды.
В сфере инвестиций алгоритмы на базе машинного обучения анализируют рынок, отслеживают новости и подбирают активы, которые выгоднее всего покупать именно сейчас. При этом с помощью предикативной аналитики система может предсказать, как будет меняться стоимость тех или иных акций за конкретный период и корректирует свои данные после каждого важного события в отрасли.
Согласно исследованию BarclayHedge, более 50% хедж-фондов используют ИИ и машинное обучение для принятия инвестиционных решений, а две трети — для генерации торговых идей и оптимизации портфелей.
Наконец, машинное обучение способствует настоящим прорывам в науке.
Нейросеть AlphaFold от DeepMind в 2020 году смогла расшифровать механизм сворачивания белка. Над этой задачей ученые-биологи бились больше 50 лет.
В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобрев в каталоге.
Получите невероятные возможности


2. Раздавайте видеоуроки в личные кабинеты ученикам.

3. Смотрите статистику просмотра видеоуроков учениками.
Конспект урока «Основные этапы разработки и исследования моделей на компьютере»
· основные этапы компьютерного моделирования;
· построение компьютерной модели.
XXI век – это век информационных технологий. И естественно компьютер используется для разработки и исследования моделей. Компьютерное исполнение информационных моделей, очень удобно, так как становится возможным проведение вычислительного эксперимента и осуществление прогнозирования.

Компьютерная модель – это компьютерная программа, работающая на отдельном компьютере, суперкомпьютере или множестве взаимодействующих компьютеров, реализующая представление объекта, системы или понятия в форме, отличной от реальной, но приближенной к алгоритмическому описанию, включающей и набор данных, характеризующих свойства системы и динамику их изменения со временем.
На сегодняшний день компьютерные модели стали обычным инструментом математического моделирования и применяются в физике, астрофизике, механике, химии, биологии, экономике, социологии, метеорологии, других науках и прикладных задачах в различных областях радиоэлектроники, машиностроения, автомобилестроения и прочих.

Компьютерные модели используются для получения новых знаний о моделируемом объекте или для приближенной оценки поведения систем, слишком сложных для аналитического исследования.
Компьютерное моделирование незаменимо:
1. когда реальные объекты очень сложные. Число факторов, которые относятся к решаемой проблеме, выходит за пределы человеческих возможностей.
2. необходимость проведения экспериментов. На практике встречается много ситуаций, когда экспериментальное исследование объектов ограничено высокой стоимостью или вовсе невозможно (опасно или вредно).
3. необходимость прогнозирования. Важное достоинство моделей состоит в том, что они позволяют «заглянуть в будущее», дать прогноз развития ситуации и определить возможные последствия принимаемых решений.
Компьютерное моделирование состоит из двух этапов.
1. для исследования объекта или процесса, составляется описательная информационная модель. Что это значит? Здесь необходимо определить цель исследования. И в зависимости от цели, выделить главные (существенные) свойства модели, необходимые для данного исследования.
2. создаётся формализованная модель. Разберёмся что это значит.
Формализованная модель – это перевод описательной информационной модели на формальный язык. Формальный значит специальный, то есть язык формул, уравнений, неравенств. Здесь мы устанавливаем формальные взаимосвязи между начальными и конечными значениями свойств объектов, а также задаём некоторые ограничения на допустимые значения этих свойств.
То есть чем больше значимых свойств будет выявлено и перенесено на компьютерную модель – тем более приближенной она окажется к реальной модели, тем большими возможностями сможет обладать система, использующая данную модель.
Компьютерное же моделирование заключается в проведении серии вычислительных экспериментов на компьютере, целью которых является анализ, истолкование и сопоставление результатов моделирования с реальным поведением изучаемого объекта и, при необходимости, последующее уточнение модели.
Выделим основные преимущества компьютерного моделирования.
Компьютерное моделирование даёт возможность:
· расширить круг исследовательских объектов — становится возможным изучать не повторяющиеся явления, явления прошлого и будущего, объекты, которые не воспроизводятся в реальных условиях;
· визуализировать объекты любой природы, в том числе и абстрактные;
· исследовать явления и процессы в динамике их развёртывания;
· управлять временем (ускорять или замедлять);
· совершать многоразовые испытания модели, каждый раз возвращая её в первичное состояние;
· получать разные характеристики объекта в числовом или графическом виде;
· находить оптимальную конструкцию объекта, не изготовляя его пробных экземпляров;
· проводить эксперименты без риска негативных последствий для здоровья человека или окружающей среды.
Современные компьютеры позволяют строить весьма сложные модели, достаточно полно отражающие реальные объекты или процессы.
Рассмотрим основные этапы компьютерного моделирования
1. Постановка задачи: описание объекта и определение цели моделирования.
На этом этапе необходимо выяснить, с какой целью создаётся модель. Определить, какие исходные данные нужны для создания модели и что ожидается получить в результате.
2. Построение информационной модели.
Здесь необходимо определить параметры модели и выявить взаимосвязь между ними. Оценить, какие из параметров важны для данной задачи, а какими можно пренебрегать. А также математически описать зависимость между параметрами модели.
3. Разработка метода и алгоритма реализации компьютерной модели.
То есть нужно выбрать или разработать метод получения исходных результатов. Составить алгоритм получения результатов по избранным методам. И проверить правильность алгоритма.
4. Разработка компьютерной модели.
Здесь выбираются средства программной реализации алгоритма на компьютере. Разрабатывается компьютерная модель. Проверяется правильность созданной компьютерной модели.
5. Проведение эксперимента.
На этом этапе разрабатывается план исследования. Проводится эксперимент на базе созданной компьютерной модели. Анализируются полученные результаты. И в конце делают выводы.
Рассмотрим основные этапы компьютерного моделирования на примере.
Лесной участок оценивается в 200000 кубометров древесины. Ежегодно этот объём увеличивается на 7% за счёт естественного прироста. Начиная с четвёртого года на хозяйственные нужды вырубается 20 000 кубометров ежегодно.
· наступит ли уменьшение объёма древесины на участке до 100 000 кубометров и на каком году.
· что произойдёт, если, начиная с седьмого года естественный прирост уменьшится до 6%.
· какой может быть максимально вырубка леса, чтобы объём древесины на участке не сокращался.
Итак, первый этап. Постановка задачи: описание объекта и определение цели моделирования.
Для нашей задачи объектом моделирования является лесной участок. Наша цель – сделать прогноз, на каком году наступит уменьшение объёма древесины на участке до ста тысяч.
Второй этап. Построение информационной модели.
Построим математическую модель.
Пусть V0 – это начальный объём древесины на участке. P – процент естественного прироста леса. Ri – это объём вырубки леса в i-том году. Vi – объём древесины в i-том году.
В нашей задаче мы будем учитывать естественный прирост древесины и пренебрегать остальными свойствами объекта, например, влияние погодных условий.
Третий этап. Разработка метода и алгоритма реализации компьютерной модели.

Аналогично будем поступать далее, пока не ответим на поставленные вопросы.
Четвёртый этап. Разработка компьютерной модели
Решим эту задачу с помощью электронных таблиц, например, Microsoft Excel.
Назовём нашу модель: Вырубка леса. Заполним исходные данные.
Теперь приступим к разработке компьютерной модели. То есть нам нужно заполнить Расчётную таблицу.

В столбец «Год» введём числа от 0 до 30. Мы увеличим количество лет, если это понадобится при решении задачи.
Начнём заполнять столбец «Объём древесины в начале года». В ячейку B9 необходимо ввести начальный объём древесины, то есть: =A3. Далее нам известно, что на следующий год объём древесины увеличится на 7% за счёт естественного прироста. Значит, в ячейку B10 вводим формулу: =B9+$A$4*B9-C10.
Заполним столбец «Вырубка». Мы знаем, что, начиная с четвёртого года на хозяйственные нужды вырубается двадцать тысяч кубометров древесины ежегодно, значит первых три года вырубка не производилась, ставим нули, а далее заполняем столбец до конца значением двадцать тысяч.
То есть в ячейку C13 запишем формулу: =$A$5.
Теперь скопируем её в диапазон ячеек C14; C39.
Вернёмся к столбцу «Объём древесины в начале года». Скопируем формулу в диапазон ячеек B11; B39.
Теперь проверим правильность скопированных данных. Проверим данные для второго года. Объём древесины в начале второго года равен значению в ячейке B10. То есть формула записана правильно.
Проверим правильность созданной компьютерной модели.
Мы построили модель в соответствии с условием задачи.
Ответим на первый вопрос нашей задачи. Уменьшение объёма древесины до 100000 кубометров наступит на 25 году, то есть в начале 26 года объём древесины будет уже меньше 100000 кубометров.
Пятый этап компьютерного моделирования. Проведение эксперимента.
В задаче необходимо ответить ещё на два вопроса:
Итак, для того чтобы выяснить, что произойдёт, если, начиная с седьмого года естественный прирост уменьшится до 6% введём в электронную таблицу ещё одно исходное значение. Теперь необходимо в ячейке B15 изменить формулу, то есть теперь у нас будет ссылка на ячейку A6, причём ссылка абсолютная. Скопируем формулу в диапазон B16; B39.
Обратите внимание, теперь уменьшение объёма древесины до 100000 кубометров наступит на 20 году, то есть в начале 21 года объём древесины будет меньше 100000 кубометров.
То есть чем меньше естественный прирост древесины, тем быстрее происходит вырубка леса.
Чтобы ответить на последний вопрос нашей задачи, необходимо заметить, что для того чтобы объём древесины на участке не сокращался максимальная вырубка леса должна быть равна естественному приросту.
Проведём эксперимент для начальных условий.
Нам нужно изменить значение в ячейке C13. Естественный прирост составляет 7% от начального объёма. Значит запишем формулу: =B12*$A$4.
Обратите внимание, для того чтобы объём древесины на участке не сокращался максимальная вырубка леса должна быть равна 17150,602 кубометра.
Пришло время подвести итоги урока.
Компьютерная модель – это компьютерная программа, работающая на отдельном компьютере, суперкомпьютере или множестве взаимодействующих компьютеров, реализующая представление объекта, системы или понятия в форме, отличной от реальной, но приближенной к алгоритмическому описанию, включающей и набор данных, характеризующих свойства системы и динамику их изменения со временем.
К основным этапам компьютерного моделирования относятся:
Первый. Постановка задачи: описание объекта и определение цели моделирования.
Второй. Построение информационной модели
Третий этап. Разработка метода и алгоритма реализации компьютерной модели
Четвёртый этап. Разработка компьютерной модели
И пятый этап. Проведение эксперимента.
Также сегодня на уроке мы с вами рассмотрели пример построения компьютерной модели.

Жизненный цикл модели машинного обучения — это многоэтапный процесс, в течении которого исследователи, инженеры и разработчики обучают, разрабатывают и обслуживают модель машинного обучения. Разработка модели машинного обучения принципиально отличается от традиционной разработки программного обеспечения и требует своего собственного уникального способа разработки. Модель машинного обучения — это приложение искусственного интеллекта (ИИ), которое дает возможность автоматически учиться и совершенствоваться на основе собственного опыта без явного участия человека. Основная цель модели заключается в том, чтобы компания смогла использовать преимущества алгоритмов искусственного интеллекта и машинного обучения для получения дополнительных конкурентных преимуществ. Над каждым этапом работает SCRUM-команда. Сотрудничество команд организуется по методике SCRUM of SCRUMs.
В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобретя в каталоге.



Шаг пятый: моделирование — какую модель выбрать? Как вы можете улучшить её? Как вы сравниваете её с другими моделями?
После того как вы определили задачу, подготовили данные, критерии оценки и характеристики, можно начинать моделировать.
Моделирование делится на три части: выбор модели, улучшение модели, сравнение её с другими.
Выбор модели
При выборе модели вы должны принять во внимание следующее: интерпретируемость и простота отладки, объём данных, ограничения на обучение и прогнозирование.
- Интерпретируемость и простота отладки — почему модель приняла решение, которое она приняла? Как исправить ошибки?
- Количество данных — сколько данных у вас есть? Изменится ли их количество?
- Ограничения в обучении и прогнозировании — это связано с вышеизложенным: сколько времени и ресурсов у вас есть для обучения и прогнозирования?
Чтобы решить эти проблемы, начните с простого. Сделать свою модель идеальной — заманчивая цель. Но если для обучения требуется в 10 раз больше вычислительных ресурсов, в 5 раз больше времени прогнозирования, а показатель оценки увеличится на 2 %, это будет не лучшее решение.
Линейные модели, такие как логистическая регрессия, обычно легче интерпретировать, они очень быстро обучаются и прогнозируются быстрее, чем более глубокие модели, такие как нейронные сети.
Но, скорее всего, ваши данные взяты из реального мира. Данные из реального мира не всегда линейны.
Что делать в таком случае?
Наборы деревьев решений и алгоритмов повышения градиента (модные слова, определения, которые пока не важны) обычно лучше всего работают со структурированными данными, такими как таблицы Excel и датафреймы. Обратите внимание на случайные леса, XGBoost и CatBoost.
Глубокие модели, такие как нейронные сети, обычно лучше всего работают с неструктурированными данными вроде изображений, аудиофайлов и текстов на естественном языке. Тем не менее, компромисс заключается в том, что они обычно дольше обучаются, их сложнее отлаживать и прогнозирование занимает больше времени. Но это не значит, что вы не должны их использовать.
Трансферное обучение — это подход, который использует преимущества глубоких и линейных моделей. При трансферном обучении берётся предварительно обученная глубокая модель и шаблоны, которые она изучила, используются в качестве входных данных для вашей линейной модели. Это значительно экономит время настройки и позволяет вам экспериментировать быстрее.
Где можно найти предварительно обученные модели?
Такие модели доступны в PyTorch hub, TensorFlow hub, model zoo и в fast.ai framework. Это хорошие ресурсы, которые стоит посмотреть перед созданием вашего прототипа.
Что насчёт других видов моделей?
Для создания прототипа вам вряд ли когда-нибудь понадобится создавать собственную модель машинного обучения. Люди уже написали код для них.
Вам нужно сосредоточиться на подготовке ваших входных и выходных данных таким образом, чтобы их можно было использовать с существующей моделью. Это означает, что ваши данные и метки должны быть строго определены. А вы должны понимать, какую задачу вы пытаетесь решить.

Настройка и улучшение модели
Первые результаты модели не являются финальными. Как и в случае с тюнингом автомобиля, модели машинного обучения можно настраивать для повышения производительности.
Настройка модели включает изменение гиперпараметров вроде скорости обучения или оптимизатора. Или специфические для модели архитектурные факторы, такие как количество деревьев для случайных лесов и количество и тип слоёв для нейронных сетей.
Раньше приходилось настраивать их вручную, но они всё больше автоматизируются. И должны быть автоматизированными везде, где это возможно.
Использование предварительно обученной через трансферное обучение модели часто даёт дополнительное преимущество всех этих шагов.
Приоритетами для настройки и улучшения моделей должны быть воспроизводимость и эффективность. Кто-то должен быть в состоянии воспроизвести шаги, которые вы предприняли для повышения производительности. И поскольку вашим главным узким местом будет время обучения модели, а не новые идеи для улучшения, ваши усилия должны быть направлены на повышение эффективности.
Сравнение моделей
- Модель 1, обученная на данных X, оценена на данных Y.
- Модель 2, обученная на данных X, оценена на данных Y.
Где-то модели 1 и 2 могут отличаться, но не в данных X или Y.











