Исправляем проблемы с отображением русских букв в Windows 10
В процессе работы в Windows 10 может возникнуть ситуация, когда русские символы в системе перестают корректно отображаться. Вместо них мы видим нечто невразумительное, некие иероглифы или кракозябры, не обладающие каким-либо практическим смыслом. Обычно такое случается, когда неправильно выбрана локаль в региональных настройках.
Частенько это имеет место быть, когда вы работаете с русскоязычными символами в операционке с английской локализацией, поскольку в ней для русскоязычной программы по умолчанию отсутствуют средства обработки кириллицы, да и какого-либо другого языка с нелатинскими символами, будь это греческая, китайская либо японская языковая конструкция. В этой статье я расскажу, как убрать кракозябры в Windows 10, и вместо них работать с корректно отображающимися русскими символами.
Обычно кракозябры отображаются не везде. К примеру, кириллические символы в названиях программ на рабочем столе написаны абсолютно правильно, без ошибок, а вот если запустить на инсталляцию один из дистрибутивов с поддержкой русского языка, то тут же все начинает идти вкривь и вкось, текст становится нечитаемым, и вы буквально не знаете, что делать.

Ниже я расскажу, как избавиться от этой проблемы, решив ее в свою пользу раз и навсегда.
Стоит понимать, что вся проблема в том, что в вашей операционной системе изначально отсутствует поддержка кириллицы. Скорее всего, вы установили дистрибутив на английском языке, и поверх него установили расширенный пакет для русификации системы, но это не решает всех проблем. Текст все равно является нечитаемым, а описанная проблема остается и никуда не исчезает.
Первое, что может прийти в голову в данной ситуации — это переставить ОС с нуля на русскую версию, где изначально уже присутствует поддержка кириллических символов. Но предположим, что этот вариант для вас не годится, поскольку вы хотите работать именно в англоязычной среде, где все символы кириллицы отображаются корректно и без багов. Именно о такой ситуации и пойдет речь в моей инструкции, которая в этом случае и придется вам как никогда кстати.
Программы для очистки компьютера от мусора
Предпосылки появления кодировок
Исторически компьютер создавался как машина для ускорения и автоматизации вычислений. Само слово computer с английского можно перевести как вычислитель, а в 20 веке в СССР, до распространения термина компьютер, использовалась аббревиатура ЭВМ — электронно вычислительная машина.
Всё, чем компьютеры оперировали — числа. Основным заказчиком и драйвером появления первых моделей были оборонные предприятия. На компьютерах проводили расчёты параметров полёта баллистических ракет, самолётов, спутников. В 1950-е годы вычислительные мощности компьютеров стали использовать для:
- прогноза погоды;
- вычислений экспериментальной и теоретической физики;
- расчета заработной платы сотрудников (например, компьютер LEO применялся для нужд компании, владеющей сетью чайных магазинов);
- прогнозирование результатов выборов президента США (1952 год, компьютер UNIVAC).
Компьютеры и числа
Цели, для которых разрабатывались компьютеры, привели к появлению архитектуры, предназначенной для работы с числами. Они хранятся в компьютере следующим образом:
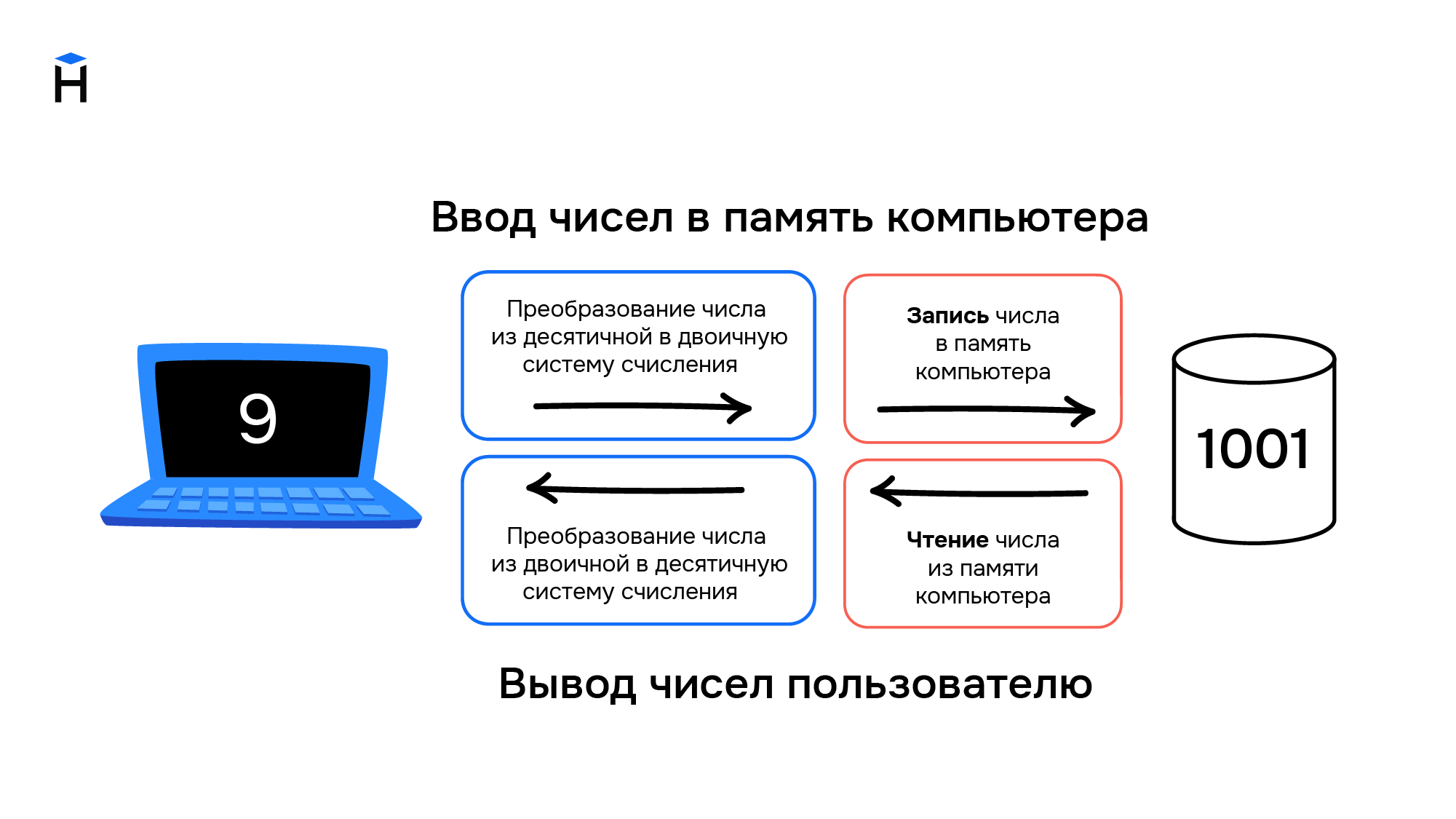
- Число из десятичной системы счисления переводится в двоичную, т.е. набор нулей и единиц. Например, 3 в двоичной системе счисления можно записать в виде 11, а 9 как 1001. Подробнее о системах счисления читайте в соответствующем гайде.
- Полученный набор нулей и единиц хранится в ячейках памяти компьютера. Например, наличие тока на элементе памяти означает единицу, его отсутствие — ноль.
В конце 1950-х годов происходит замена ламп накаливания на полупроводниковые элементы (транзисторы и диоды). Внедрение новой технологии позволило уменьшить размеры компьютеров, увеличить скорость работы и надёжность вычислений, а также повлияло на конечную стоимость. Если первые компьютеры были дорогостоящими штучными проектами, которые могли себе позволить только государства или крупные компании, то с применением полупроводников начали появляться серийные компьютеры, пусть даже и не персональные.
Компьютеры и символы
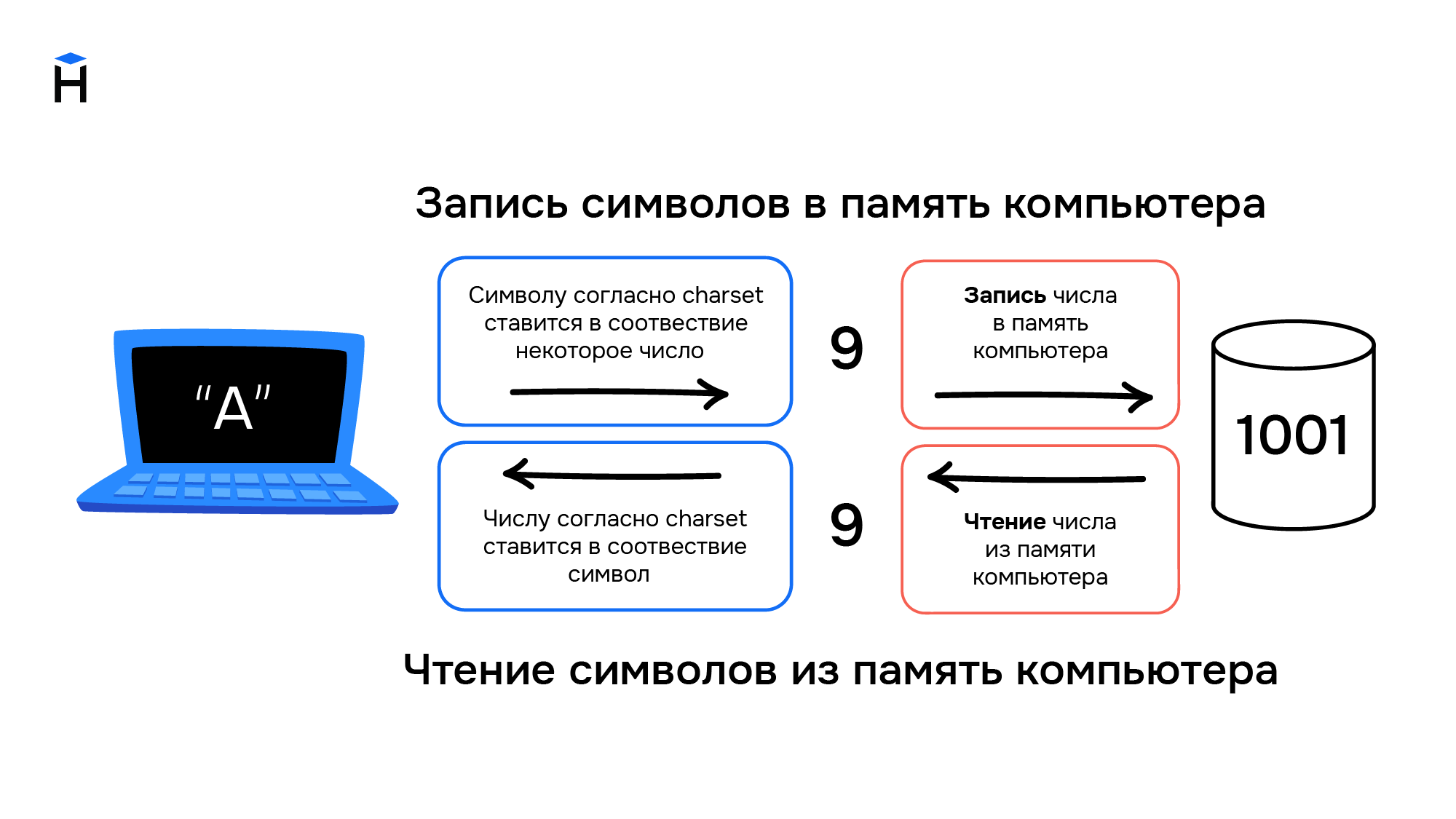
Постепенно компьютеры начинают применяться для решения не только вычислительных или математических задач. Возникает необходимость обработки текстовой информации, но с буквами и другими символами ситуация обстоит сложнее, чем с числами. Символы — это визуальный объект. Даже одна и та же буква «а» может быть представлена двумя различными символами «а» и «А» в зависимости от регистра.
Также число «один» можно представить в виде различных символов. Это может быть арабская цифра 1 или римская цифра I. Значение числа не меняется, но символы используются разные.
Компьютеры создавались для работы с числами, они не могут хранить символы. При вводе информации в компьютер символы преобразуются в числа и хранятся в памяти компьютера как обычные числа, а при выводе информации происходит обратное преобразование из чисел в символы.
Правила преобразования символов и чисел хранились в виде таблицы символов (англ. charset). В соответствии с такой таблицей для каждого компьютера конструировали и своё уникальное устройство ввода/вывода информации (например, клавиатура и принтер).
Распространение компьютеров
В начале 1960-х годов компьютеры были несовместимы друг с другом даже в рамках одной компании-производителя. Например, в компании IBM насчитывалось около 20 конструкторских бюро, и каждое разрабатывало свою собственную модель. Такие компьютеры не были универсальными, они создавались для решения конкретных задач. Для каждой решаемой задачи формировалась необходимая таблица символов, и проектировались устройства ввода/вывода информации.
В этот период начинают формироваться сети, соединяющие в себе несколько компьютеров. Так, в 1958 году создали систему SAGE (Semi-Automatic Ground Environment), объединившую радарные станций США и Канады в первую крупномасштабную компьютерную сеть. При этом, чтобы результаты вычислений одних компьютеров можно было использовать на других компьютерах сети, они должны были обладать одинаковыми таблицами символов.
В 1962 году компания IBM формирует два главных принципа для развития собственной линейки компьютеров:
- Компьютеры должны стать универсальными. Это означало переход от производства узкоспециализированных компьютеров к машинам, которые могут решать разные задачи.
- Компьютеры должны стать совместимыми друг с другом, то есть должна быть возможность использовать данные с одного компьютера на другом.
Так в 1965 году появились компьютеры IBM System/360. Это была линейка из шести моделей, состоящих из совместимых модулей. Модели различались по производительности и стоимости, что позволило заказчикам гибко подходить к выбору компьютера. Модульность систем привела к появлению новой отрасли — производству совместимых с System/360 вычислительных модулей. У компаний не было необходимости производить компьютер целиком, они могли выходить на рынок с отдельными совместимыми модулями. Всё это привело к ещё большему распространению компьютеров.
Ответ: 2
В одной из кодировок Unicode каждый символ кодируется 16 битами. Определите размер следующего предложения в данной кодировке:
Вознёсся выше он главою непокорной Александрийского столпа.
1) 118 бит
2) 944 бит
3) 59 байт
4) 472 байт
Ответ напишите в комментариях этого поста
Данная задача была взята с открытого банка заданий ОГЭ по информатике.


ЕГЭ по информатике задание 2 Тема: «Построение и анализ таблиц истинности логических выражений» Логическая

Паскаль. Программа калькулятор. Пример работы оператора выбора case На данном уроке рассмотрим оператор выбора
Средства выразительности
Антитеза — противопоставление.
Гипербола — художественное преувеличение.
Градация — постепенное нагнетание или ослабление смысловой и эмоциональной значимости слов.
Ирония — иносказание, при котором за внешне положительной оценкой скрывается насмешка.
Литота — художественное преуменьшение.
Метафора — употребление слова или выражения в переносном значении, основанное на сходстве, сравнении, аналогии.
Олицетворение — приписывание человеческих свойств неодушевлённому предмету, явлению или понятию.
Сравнение — уподобление одного предмета или явления другому по какому-то общему для них признаку.
Эпитет — красочное определение.
Какие средства художественной выразительности и фигуры речи использованы в отрывках? Выбери один вариант в каждом посте.
5 и 6 классы
1 — Бурсаки вдруг преобразились: на них явились… шаровары шириною в Чёрное море, с тысячью складок и со сборами… H.В. Гоголь, «Тарас Бульба»
Ответ: гипербола
2 — Она и в пятьдесят лет была замечательная красавица. Но в молодости, восемнадцати лет, была прелестна: высокая, стройная, грациозная и величественная, именно величественная. Л.Н. Толстой, «После бала»
Ответ: эпитет
3 — Налево, как будто кто чиркнул по небу спичкой, мелькнула бледная, фосфористическая полоска и потухла. А.П. Чехов, «Степь»
Ответ: сравнение
4 — Что ищет он в стране далёкой? Что кинул он в краю родном?… Играют волны — ветер свищет, И мачта гнётся и скрыпит… М.Ю. Лермонтов, «Парус»
Ответ: антитеза
7 класс (из предыдущих взяли Л.Н. Толстой, «После бала», остальные новые)
5 — Приводили обыкновенно новичка к дверям этой комнаты, нечаянно вталкивали его к медведю, двери запирались, и несчастную жертву оставляли наедине с косматым пустынником. Таковы были благородные увеселения русского барина! A.С. Пушкин, «Дубровский»
Ответ: ирония
6 — Тот имеет отличного повара, но, к сожалению, такой маленький рот, что больше двух кусочков никак не может пропустить… Н.В. Гоголь, «Невский проспект»
Ответ: литота
7 — Толстый только что пообедал на вокзале, и губы его, подёрнутые маслом, лоснились, как спелые вишни. A. П. Чехов, «Толстый и тонкий»
Ответ: сравнение
8 — Не жаль мне лет, растраченных напрасно, Не жаль души сиреневую цветь. В саду горит костёр рябины красной, Но никого не может он согреть. C. Есенин, «Отговорила роща золотая…»
Ответ: метафора
8 класс (из предыдущих взяли А.П. Чехов, «Степь» и М.Ю. Лермонтов, «Парус», A.С. Пушкин, «Дубровский» добавили два новых)
9 — Произошла такая бестолковщина: донос сел верхом на доносе, и пошли открываться такие дела, которых и солнце не видало, и даже такие, которых и не было. H.В. Гоголь, «Мертвые души»
Ответ: гипербола
10 — Не жаль мне лет, растраченных напрасно, Не жаль души сиреневую цветь. В саду горит костёр рябины красной, Но никого не может он согреть. C. Есенин, «Отговорила роща залотая…»
Ответ: метафора
9 класс (из предыдущих взяли A.С. Пушкин, «Дубровский», H.В. Гоголь, «Мертвые души», А.П. Чехов, «Степь», Л.Н. Толстой, «После бала», C. Есенин, «Отговорила роща залотая…»)
Как готовиться
На сайте ФИПИ есть открытый банк заданий с аудиозаписями, которые будут на экзамене. Открывайте материалы и тренируйтесь писать изложения. Возможно, один из этих текстов попадётся вам на ОГЭ.
Например, возьмём этот текст. Внимательно прослушайте его два раза и выпишите микротемы и ключевые слова. Затем сверьтесь с этой таблицей:
микротемы
1. Доброта — основа душевной красоты человека, и её не надо стесняться.
2. Добрые чувства должны воспитываться с детства вместе с познанием ценности жизни.
3. Добрые чувства, эмоциональная культура — это средоточие человечности. Путь добра — единственно верный жизненный путь человека.
Ключевые слова
1. Вопрос — ответы, добрый, душевная красота.
2. Забота, воспитываться в детстве, ценность жизни, поступки во имя добра.
3. Путь добра. В мире, где много зла. Полезен человеку и обществу
Напишите изложение и проверьте его два раза. Отметьте, всем ли критериям оно соответствует:
- переданы все три микротемы;
- все три микротемы сжаты;
- текст чётко разделён на три абзаца;
- нет логических ошибок.
Чем больше изложений вы напишете и проверите, тем комфортнее будете чувствовать себя на экзамене.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter
Окна в различных приложениях Windows
Бывает такое, что какое-нибудь окно или меню в программе показывается с иероглифами (разумеется, прочитать что-то или разобрать — нереально).
Могу дать несколько рекомендаций:
- Русификатор. Довольно часто официальной поддержки русского языка в программе нет, но многие умельцы делают русификаторы. Скорее всего, на вашей системе — данный русификатор работать отказался. Поэтому, совет простой: попробовать поставить другой;
- Переключение языка. Многие программы можно использовать и без русского, переключив в настройках язык на английский. Ну в самом деле: зачем вам в какой-то утилите, вместо кнопки «Start» перевод «начать» ?
- Если у вас раньше текст отображался нормально, а сейчас нет — попробуйте восстановить Windows, если, конечно, у вас есть точки восстановления;
- Проверить настройки языков и региональных стандартов в Windows, часто причина кроется именно в них ( ).
Языки и региональные стандарты в Windows
Чтобы открыть меню настроек:
- нажмите Win+R ;
- введите intl.cpl , нажмите Enter.
intl.cpl — язык и регион. стандарты
Проверьте чтобы во вкладке «Форматы» стояло «Русский (Россия) / Использовать язык интерфейса Windows (рекомендуется)» (пример на скрине ниже ).
Формат — русский / Россия
Во вкладке «Местоположение» — укажите «Россия» .
И во вкладке «Дополнительно» установите язык системы «Русский (Россия)» .
После этого сохраните настройки и перезагрузите ПК. Затем вновь проверьте, нормально ли отображается интерфейс нужной программы.
Текущий язык программ
PS
И напоследок, наверное, для многих это очевидно, и все же некоторые открывают определенные файлы в программах, которые не предназначены для этого: к примеру в обычном блокноте пытаются прочитать файл DOCX или PDF.
Естественно, в этом случае вы вместо текста будут наблюдать за крякозабрами, используйте те программы, которые предназначены для данного типа файла (WORD 2016+ и Adobe Reader для примера выше).
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
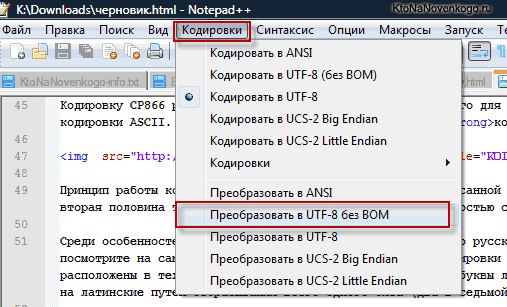
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
![]()
Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
По идее, элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов.
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Комментарии и отзывы (38)
Спасибо за интересную статью. Вот про БОМ не знал. В php от крокозябр всегда избавлялся командой: @mysql_query («SET NAMES ‘cp1251’»);
Да, и ноутпад++ поистине очень удобный инструмент.
Довольно интересная статья. Здорово, что описываете все так подробно, читая ваши материалы есть ощущение, что попадаешь на лекцию в университет.
Спасибо Вам большое.
Благодаря Вашей статье решила проблему с арабской кодировкой.
Статья — интересная, познавательная. Я попыталась вставить тизерную рекламу в сидебар, так вот тексты у тизеров появляются даже не кракозябрами, а какими-то квадратиками в которых 4 латинские буквы в два ряда по 2 шт в каждом.
В других частях блога таких проявлений замечено не было.
Как посоветуете изменить ситуацию. Кодировка файла sidebar после включения рекламного блока — правильная. Помогите, пожалуйста разобраться.
я получила сообщение по почте с приложением Сохранила в компьютере файл ТЕКСТ документа не читается Как раскодировать
Допустим, если символы закодированные с помощью CP866 попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор символов) и вылезут, полностью заменив собой текст сообщения.
А что значит закодированые??
спасибо большое, просто сказка:) книга писателям есть чему у тебя поучиться. Да действительно как я до сих пор без notepad++ обходился, правда есть такой инструмент на все случаи жизни slickedit: платная; но есть возможность пробную лицензию взять.
Простите, что не в тему немного, но всё-таки хотелось бы разобраться. Может это у меня с виндой косяк, но файлы, созданные с помощью Codelobster, в которых есть русский текст, даже просто txt, когда открываешь их браузером или редактором wordpad, вместо кириллицы отображаются не читаемые символы. В Notepad++ и в блокноте все текст нормально отображается, но в правом углу окна Notepad++ вижу надпись «ANSI as UTF-8», а в документах, содержащих только английский текст (независимо от расширения файла) — «ANSI»! В то время, как файл я сохраняю как UTF-8, оно же стоит по умолчанию и радиокнопку «windows» нажимаю. В чём может быть проблема?
у меня возникла такая проблема, когда я открываю в интернете документы допустим «Региональные экзамены и тд» то у меня появляется табличка «Параметры фильтра ASCII» и там нужно указать кодировку, стандартный шрифт, язык и разрыв текста((и когда я указываю, как я думаю, то у меня открывается документ со всякой кракозяброй( Помогите плииз.
Создал блог, все «сохранял в утф-8 без бом».
Залил скрипт find_bom.php, проверил — все чисто, бома нет.
Вроде все нормально, но в одном браузере (мозила) — крякозябры.
Уже и в БД зашел, поменял 1251 на утф, без изменений.
Нет сейчас возможности проверить, как вокруг воспринимается.
Что надо еще сделать?
здравствуйте все здесь есть понимающие html коды, юникод, помогите новичку пожалуйста одним вопросом замучился а то, есть один сайт туда я должен писать и отправлять греческие символы, но этот сайт вместо того чтобы отобразить символ показывает его html код, вероятно сайт нормально показывает только русские и английские буквы. Скажите есть ли варианты закодировать символы эти, чтобы их читал сайт, он по моему на UTF-8. буду очень благодарен!
Статья очень познавательная. Жаль только что проблемы она не решает.
Я делаю форму в html. action:mailto. Но при загрузке обработчика вылезают кракозябры. Я перепробовал все кодировки и атрибуты. пробовал сделать форму отдельно от файла. Не помогает ничего. Подскажите, пожалуйста, что делать!?
Здравствуйте Дмитрий, пожалуйста помогите разобраться с проблемой. Возможно это связано с кодировкой. У меня комментарии на русском, на блоге, выводятся кубиками и знаками вопросов. Английский же нормально публикуется. В чем может быть проблема? Нигде не могу найти ответ.
0_о@. +w:(”#@=’,.;;. помогите пожалуйста это прочитать, очень надо , с помощью чего написано не знаю!
У меня на сайте появилась проблема. На главной при выводе части поста в конце появляется вопросительный знак в черном ромбе. Нигде больше проблем с кодировками больше нет.
Появилось где-то месяц назад. Плагинов никаких не ставил. Прошу помочь.
Разобрался, а то не мог понять в чём ошибка.
Благодарю создателя сайта, и автора статьи)
Спасибо за статью! Продолжайте в том же духе!
У меня вопрос насчет BOM. Когда я сохраняю без БУМ, получается я сохраняю на utf 8? А когда с БУМ то utf 16? Без БУМ у меня выходит крякозябры. Хотелось бы больше узнать про этот бум. Если файл сохранить с бум ничего фатального в этом нет? С ним объем кодировки увеличивается или что? Что с ним не так? Почему надо без него сохранять?
Спасибо за статью. Наверное как и многие попал сюда чтоб разобраться — что за зверь эта — utf8 и с чем её едят. Думаю, что разобрался. Мне кажется наглядно было бы привести пример: в Нотепаде написать слово «1234андр» и сохранить в Анси файле и в ЮТФ8 файле. Первый файл будет весить 8 байт, второй 15. Потом второй файл открыть Нотепадом++ и перекодировать в ЮТФ8 без БОМ. После сохранения он будет весить 12 байт. Вот тут-то, опираясь на статью, всё в голове и стает на свои места. Еще раз спасибо.
Наконец нашла статью объясняющую по какому поводу мучения с непонятными абдакадабрами. Спасибо автору — в голове более менее появился порядок. Все проблемы были в использовании частом блокнота.
Статья полезная для общего развития, но практически преобразовать следующую строку
во что-то удобочитаемое я так и не смог (это название темы Е-письма, пришедшего от loopy.ru, текст письма нормальный). Пользоавлся и Word, и TextViewer, и Hieroglyph и еще 5-6 «крутыми» текстовыми редакторами — везде преобразуется во всё, что угодно, но только не в то, что можно прочитать.
Спасибо! Отличная статья. Очень доступно. Только в СР866 9C соответствует не ‘М’, а ‘Ь’. Если я не ошибаюсь.
звучит как «ваши правки одобрены (ерика)».
Преобразовано из 20866 (русская — КОИ8) в 65001 (UTF-8)
с помощью AkelPad 4.8.4.
Имхо, произошло ЭТО из-за того,
что почтовик отправителя настроен на КОИ8 (текст),
а Ваш (Mashinist) почтовик настроен на UTF-8 (html).
Поэтому ТЕЛО письма читалось хорошо,
а ТЕМА письма это только текст в соответствующей кодировке.
У меня с Codelobster тот же косяк что и у Степана.
Все настройки перепробовал, всё равно просто utf-8 и ни каким «без BOM» и не пахнет.
Нажимаешь файл->изменить кодировку — меняет, закрываешь-открываешь нету «BOM» он его опять сам как то по своему перекодирует.
Вот зараза. Пришлось такие файлы только в notepad++ редактировать.
1. Чтобы новый файл создавался в кодировке утф 8 (это мы увидим в notepad++) в настройках по умолчанию выбираем не With BOM — а просто UTF-8 .
2. Возможно, помогло ещё в настройках->форматирование выбрать Drupal (я с ним работаю)
Теперь при создании и редактирования файла кодировка сохраняется — «ANSI as UTF-8», но показывается просто как утф-8. Только изменить любую другую кодировку на «ANSI as UTF-8» в Codelobstere по прежнему не работает, это можно сделать например в notepad++.
Метод научного тыка рулит!
скажите , есть ли плагин создающий на блоге такое как конвертор ASCII, например создал страницу , пользователь на нее зашел , в одно окно вбил текст на русском , а в другом получил цифровое значение этого текста . спасибо
использую WinSyntax 2.0 как и нотпад подсвечивает код,
в XPюше стандартный блокнот на SP2 поддерживает сохранение в UTF-8 без BOM, почему-то в новых таковую функцию убрали.
zee, вот тебе http://2cyr.com/decode/?lang=ru, делай парсер
А у меня в реестре винды есть строка в Юникоде. Удалить невозможно. Это из-за того, что нечитаемо? Служба BonanzaDealsLive (bonanzadealslive)
Спасибо, буду бороться со своей бедой
Спасибо большое, решила проблему с выводом русских букв в меню на сайте на WordPress
Спасибо, решен вопрос с кодировкой формы обратной связи.
Давно уже пора признать что это доселе неизвестный вирус! Как вы объясните кракозябры в отдельных файлах word и блокноте windows ? После замены файлов с кракозябрами на нормальные, с архивного диска, на следующий день они опять стали с кракозябрами. Вирус пометил почему то именно эти файлы.
Спасибо за Ваш труд. Все ясно и легко изложено. Долгое время не мог решить свою проблему отображения текста в письмах, но благодаря Вашей статье — все решил, а более того приобрёл опыт. Занес Вас в закладки! Спасибо!
Ребята, а какая версия Юникода в виндоусе стоит? ведь Unicode постоянно развивается, сейчас уже 9 версию. У меня например стоит windows 8.1 и он ни разу не принимал обновления. Какая в нем версию Юникод ?
А как же иНЖАЛИД ДЕЖИЦЕ?
Видать не всегда АСКИ
Ребята, кто-то помогите раскодировать текст с «Кириллица (DOS/OS2-866/русский)» или с —
Кириллица (Apple Macintosh)
Ничего не помогает, у меня при незначительном сбое в системе, пропало 45 страниц текста нового романа, что я пишу, превратившись в бесконечный повтор одного символа (как чаще всего) — #######################################. и так на все сорок пять страниц текста.
Я работал в текстовом редакторе OpenOffice.org 4.1.3 (последняя версия) и перепробовал все вышеуказанные кодировки, бесполезно. оригинальный текст был на шрифте Constansia (русский)
Пробовал через сайт OpenOffice просить помощь, там все на энглиш и на десятке языков кроме русского (видать санкции или хрен знает что) пробовал писать через е-мейл — ответ на английском — гугловские переводчики переводят на русский — плакать хочется.
Очень классная статья
Предлагаю чуть улучшить и заодно прояснить для меня один момент.
В разделе «ASCII — базовая кодировка текста для латиницы», где мы получили число 233, дальше перевели его в шестнадцатеричное, получив E9.
Как его использовать в таблицах различных кодировок? Первый символ «Е» смотреть по вертикали или по горизонтали?
Примеры с различными кодировками (какие символы соответствуют Е9), как по мне, были бы нелишними.











