Символ кириллицы как написать
Русскоязычную раскладку клавиатуры во всем мире называют кириллицей. Она популярна среди носителей языка и узнаваема даже теми, кто никогда не занимался изучением языков славянской группы. Разберемся, какие буквы называются кириллицей, а какие латиницей.
Первая клавиатура создавалась с латинскими символами. Но распространяясь, она обзавелась дополнительными символами других языков, от которых слабо отличалась (например, немецкий). А для других языков и вовсе поменяла свой внешний вид. Яркий тому пример кириллица.
Почему русская раскладка называется кириллицей
Как ни странно, символы на «русской» клавиатуре не являются самой кириллицей, а лишь созданы на основе ее. Кириллица — это старославянская письменность, которая в настоящее время в повседневном письме не используется. Так как кириллица была некогда создана апостолами Кириллом и Мефодием, она стала, по сути, первой письменностью на Руси. В честь нее решили назвать и русскоязычную раскладку на клавиатуре.
Как расположен русский алфавит на клавиатуре
Буквы кириллической раскладки, созданной уже после опытов с Qwerty, расположены не в алфавитном порядке, а в зависимости от частоты их использования. Так как российская раскладка создавалась несколько позднее латинской, то были учтены ошибки последнего опыта.
ВАЖНО! Российская раскладка является более эргономичной и удобной как для простой печати, так и для набора вслепую.

Буквы в ней расположены по следующему принципу:
- наиболее используемые буквы располагаются под указательными пальцами;
- редкие — под более слабыми безымянными и мизинцами;
- буква Ё в отдельном углу, так как при печати она используется в исключительных случаях.
СПРАВКА! Основным недостатком кириллической раскладки является расположение запятой, которой не досталось отдельной клавиши.
Чтобы ее поставить в тексте, необходимо использовать сразу две клавиши. Некоторые считают, что именно это послужило причиной частого опускания запятых при быстрой электронной переписке.
Исправляем иероглифы на текст
Вообще, раньше Internet Explorer часто выдавал подобные крякозабры, современные же браузеры (Chrome, Яндекс-браузер, Opera, Firefox) — довольно неплохо определяют кодировку, и ошибаются очень редко.
Скажу даже больше, в некоторых версиях браузера уже убрали выбор кодировки, и для «ручной» настройки этого параметра нужно скачивать дополнения, или лезть в дебри настроек за 10-ток галочек.
Итак, предположим браузер неправильно определили кодировку и вы увидели следующее (как на скрине ниже ).
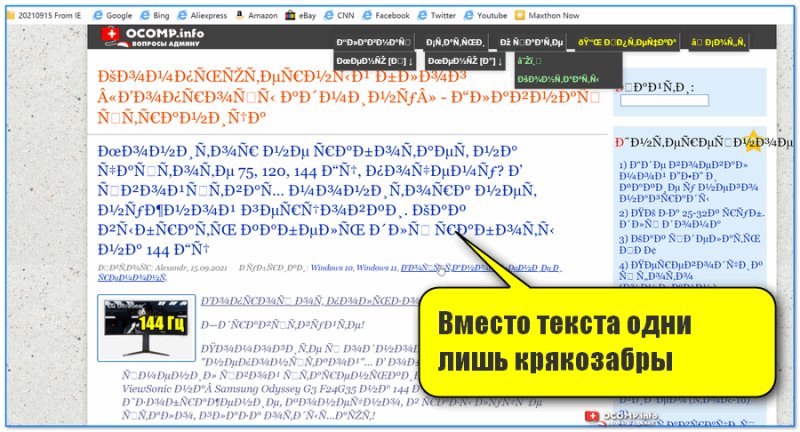
Вместо текста одни лишь крякозабры // Браузер выставил кодировку неверно!
Кстати!
Чаще всего путаница бывает между кодировками UTF (Юникод) и Windows-1251 (большинство русскоязычных сайтов выполнены в этих кодировках).
Поэтому, я рекомендую в ручном режиме попробовать их обе. Для этого нам понадобиться браузер MX5 (ссылка на офиц. сайт). Он один из немногих позволяет в ручном режиме выбирать кодировку (при необходимости):
- необходимо открыть нужный сайт;
- далее зайти в меню «Инструменты / кодировка» ;
- выбрать вручную UTF 8 или «Авто-определение» ;
- перезагрузить страницу. И, ву-а-ля, — иероглифы на страничке сразу же стали обычным текстом (скрин ниже ) !
В помощь!
Если у вас иероглифы в браузере Chrome — ознакомьтесь с этим
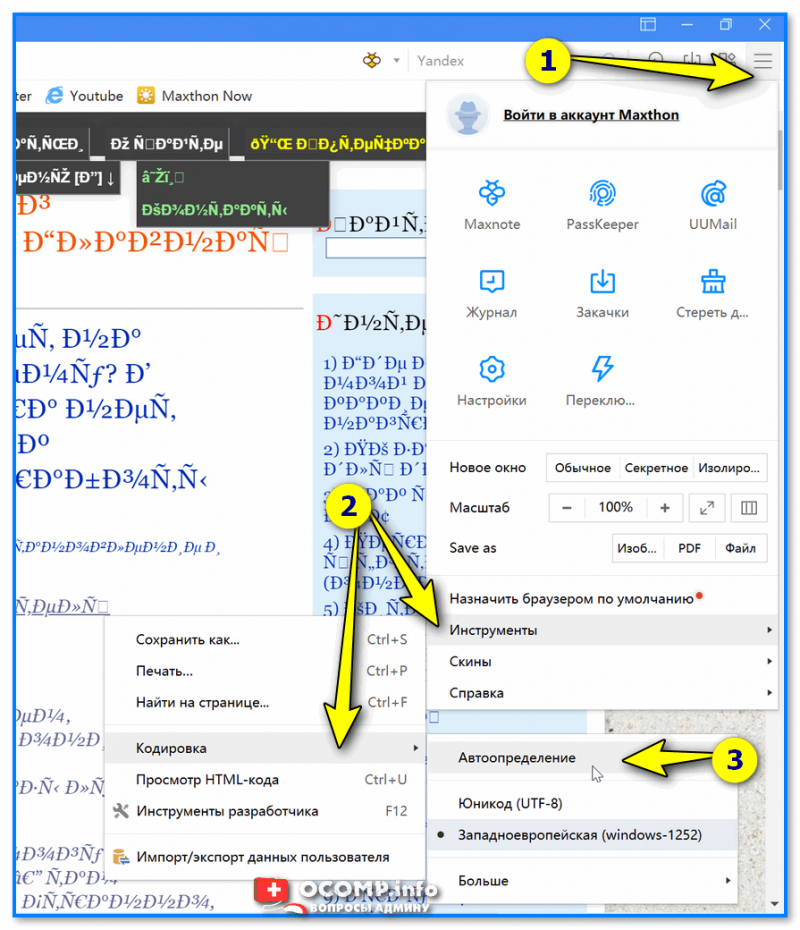
Браузер MX5 — выбор кодировки UTF8 или авто-определение
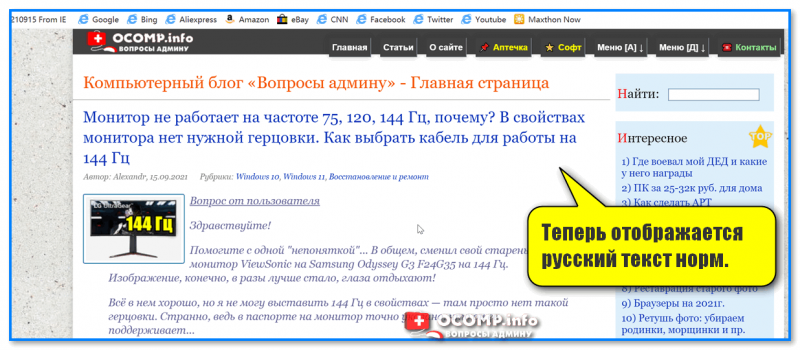
Теперь отображается русский текст норм.
Еще один совет : если вы в своем браузере не можете найти, как сменить кодировку (а дать инструкцию для каждого браузера — вообще нереально!), я рекомендую попробовать открыть страничку в другом браузере (например, в MX5). Очень часто другая программа открывает страницу так, как нужно!
Виды кодировок текста
А их, в общем-то, хватает.
Одной из самых “древних” считается американская кодировочная таблица (ASCII, читается как “аски”), принятая национальным институтом стандартов. Для кодировки она использовала 7 битов, в первых 128 значениях размещался английский алфавит (в нижнем и верхнем регистрах), а также знаки, цифры и символы. Она больше подходила для англоязычных пользователей и не была универсальной.
- Кириллица
Отечественный вариант кодировки, для которого стали использовать вторую часть кодовой таблицы – символы с 129 по 256. Заточена под русскоязычную аудиторию.
- Кодировки семейства MS Windows: Windows 1250-1258.
8-битные кодировки, появились как следствие разработки самой популярной операционной системы, Windows. Номера с 1250 по 1258 указывают на язык, под который они заточены, например, 1250 – для языков центральной Европы; 1251 – кириллический алфавит.
- Код обмена информацией 8 бит – КОИ8
KOI8-R, KOI8-U, KOI-7 – стандарт для русской кириллицы в юникс-подобных операционных системах.
Универсальный стандарт кодирования символов, позволяющий описать знаки практически всех письменных языков. Обозначение “U+xxxx” (хххх – 16-ричные цифры). Самые распространенные семейства кодировок UTF (Unicode Transformation Format): UTF-8, 16, 32.
В настоящее время, как говорится, “рулит” UTF-8 – именно она обеспечивают наилучшую совместимость со старыми ОС, которые использовали 8-битные символы. В UTF-8 кодировке находятся большинство сайтов в сети Интернет и именно этот стандарт является универсальным (поддержка кириллицы и латиницы).
Разумеется, я привел не все виды кодировок, а только наиболее ходовые. Если же Вы хотите для общего развития знать их все, то полный список можно отыскать в самом браузере. Для этого достаточно пройти в нем на вкладку “Вид-Кодировка-Выбрать список” и ознакомиться со всевозможными их вариантами (см. изображение).

Думаю возник резонный вопрос: “Какого лешего столько кодировок?”. Их изобилие и причины возникновения можно сравнить с таким явлением, как кроссбраузерность/кроссплатформенность. Это когда один и тот же сайт сайт отображается по-разному в различных интернет-обозревателях и на различных гаджет-устройствах. Кстати у сайта «Заметки Сис.Админа» с этим, как Вы заметили всё в порядке :).
Все эти кодировки – рабочие варианты, созданные разработчиками “под себя” и решение своих задач. Когда же их количество перевалило за все разумные пределы, а в поисковиках стали плодиться запросы типа: “Как убрать кракозябры в браузере?” — разработчики стали ломать голову над приведением всей этой каши к единому стандарту, чтобы, так сказать, всем было хорошо. И кодировка Unicode, в общем-то, это “хорошо” и сделала. Теперь если такие проблемы и возникают, то они носят локальный характер, и не знают как их исправить только совсем непросвещенные пользователи (впрочем, часто беда с кодировкой и отображением сайтов появляется из-за того, что веб-мастер указал на стороне сервера некорректный формат, и приходится переключать кодировку в браузере).
Ну вот, собственно, пока вся «базово необходимая» теория, которая позволит Вам “не плавать” в кодировочных вопросах, теперь переходим к практической части статьи.
«Неправильный пароль»
Подобное системное сообщение возникает в случае его ошибочности. К примеру, пользователь случайно ввел не тот символ и не обратил на это внимания. Но порой, казалось бы, все верно, многократно проверено, но войти под своей учетной записью все не выходит. Одна из возможных причин ошибки – это то, что человек забыл сменить раскладку клавиатуры или же использовал в нем кириллический символ. Обычно для удобства пользователей сайт или приложение может об этом предупредить, выдав подсказку, что в кодовой фразе есть буква русского алфавита. Но подобная функциональность встречается не во всех сервисах. Так что мы разобрались с тем, что такое кириллица в пароле.
Для исправления такой ошибки нужно просто быть внимательнее, – проверить, на каком языке вводится информация, и не включена ли клавиша Caps Lock. Ведь к примеру, Planeta и PlAnEtA – совершенно разные пароли, и об этом стоит помнить. Но почему использование наших «родных» букв запрещено?
Исправление отображения кириллицы с помощью настроек языка и региональных стандартов Windows 10
Самый простой и чаще всего работающий способ убрать кракозябры и вернуть русские буквы в Windows 10 — исправить некоторые неправильные настройки в параметрах системы.
Для этого потребуется выполнить следующие шаги (примечание: привожу также названия нужных пунктов на английском, так как иногда необходимость исправить кириллицу возникает в англоязычных версиях системы без нужды менять язык интерфейса).
- Откройте панель управления (для этого можно начать набирать «Панель управления» или «Control Panel» в поиске на панели задач.
- Убедитесь, что в поле «Просмотр» (View by) установлено «Значки» (Icons) и выберите пункт «Региональные стандарты» (Region).
- На вкладке «Дополнительно» (Administrative) в разделе «Язык программ, не поддерживающих Юникод» (Language for non-Unicode programs) нажмите по кнопке «Изменить язык системы» (Change system locale).
- Выберите русский язык, нажмите «Ок» и подтвердите перезагрузку компьютера.
После перезагрузки проверьте, была ли решена проблема с отображением русских букв в интерфейсе программ и (или) документах — обычно, кракозябры бывают исправлены после этих простых действий.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
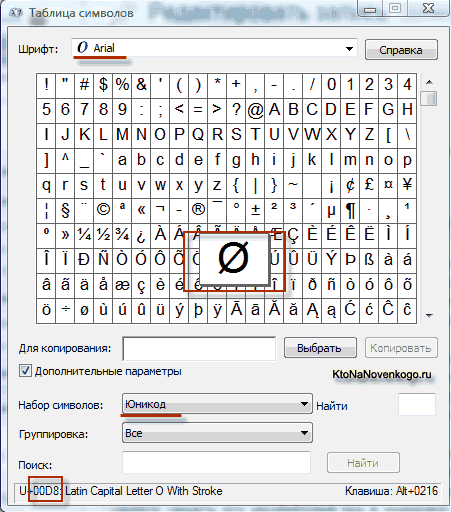
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. Сейчас в наборы даже эмодзи смайлики добавляют.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Но как тогда можно разнообразить пароль и при этом сохранить его основу?

Добавляйте в пароль адрес страницы, на которой вам нужен пароль, используя например первую и третью букву от названия страницы, и первую букву после «точки».
Например «фишки.нет» и Вариант №5
ЯспНнсМ781501Фшн
или «майл.ру» и Вариант №5
ЯспНнсМ781501Мйр
Основа пароля сохранена, а пароль не будет повторятся на других страницах.
Что дает кодовое слово
На самом деле, много чего. Оно позволит получить доступ к такой информации, как:
- Размер имеющейся задолженности.
- Баланс счета или наличие собственных средств.
- Дату проведения очередного ежемесячного платежа и т.д.
То есть, речь идет обо всех видах конфиденциальной информации. Конечно, по возможности есть вариант воспользоваться паспортными данными, однако, не все банки согласны на это, да и на это требуется довольно много времени.
Кстати, без кодового слова нельзя заблокировать карту дистанционно (во время звонка. Через приложение можно). Придется обращаться в ближайшее отделение «Почта банка» и писать соответствующее заявление. Если карта попала в руки к третьим лицам, то выполнить данную процедуру нужно, как можно скорее.

Как же выбрать необходимые символы? Примеры

Все просто: можно, как самостоятельно заменить русские буквы на соответствующие им символы. Например, «яблоко» будет прописано, как «jabloko» или «стол» будет указываться, как «stol».
Если не хочется самостоятельно подбирать буквы или есть боязнь допустить ошибку, то всегда можно воспользоваться специальными сервисами по подбору букв. Программ много и они бесплатные. При этом у некоторых есть специальный функционал, который поможет подобрать и идеальное кодовое слово.
Многим людям это существенно облегчает задачу, потому что они не могут самостоятельно подобрать идеальный вариант, который было бы несложно запомнить, но при этом, чтобы он был достаточно сложный для того, чтобы мошенники могли его разгадать.











