Кэш — память процессора.
Кэш – это часть памяти, которая обеспечивает максимальную скорость доступа и ускоряет скорость вычисления. Он хранит в себе части данных, которые процессор запрашивает наиболее часто, так что процессору нет необходимости постоянно за ними обращаться к памяти системы.
Как вы знаете, оперативная память – это часть оборудования компьютера, которая характеризуется наиболее медленными скоростями обмена данными. Если процессору понадобится какая-то информация, он отправляется за ней к оперативной памяти по одноимённой шине. Получив от процессора запрос, та начинает копаться в своих анналах в поисках нужных процессору данных. По получению ОЗУ пересылает их обратно в процессор по той же шине памяти. Такой круг для обмена данными всегда был длинноват. Потому производители и решили, что можно было бы позволить процессору хранить данные где-нибудь поблизости. Принцип работы кэша основан на простой идее.
Представьте, что память – это школьная библиотека. Ученик подходит к работнику за книжкой, та отправляется к полкам, ищет её, возвращается к студенту, должным образом оформляет и приступает к следующему ученику. В конце дня он повторяет ту же операцию, когда книги ей возвращают. Вот так работает процессор без кэша.
Функция кэш-памяти
В чем же состоит причина, которая побудила разработчиков компьютеров использовать специальную память для процессора? Разве возможностей ОЗУ для компьютера недостаточно?
Действительно, долгое время персональные компьютеры обходились без какой-либо кэш-памяти. Но, как известно, процессор – это самое быстродействующее устройство персонального компьютера и его скорость росла с каждым новым поколением CPU. В настоящее время его скорость измеряется миллиардами операций в секунду. В то же время стандартная оперативная память не столь значительно увеличила свое быстродействие за время своей эволюции.
Вообще говоря, существуют две основные технологии микросхем памяти – статическая память и динамическая память. Не углубляясь в подробности их устройства, скажем лишь, что статическая память, в отличие от динамической, не требует регенерации; кроме того, в статической памяти для одного бита информации используется 4-8 транзисторов, в то время как в динамической – 1-2 транзистора. Соответственно динамическая память гораздо дешевле статической, но в то же время и намного медленнее. В настоящее время микросхемы ОЗУ изготавливаются на основе динамической памяти.
Примерная эволюция соотношения скорости работы процессоров и ОЗУ:

Таким образом, если бы процессор брал все время информацию из оперативной памяти, то ему пришлось бы ждать медлительную динамическую память, и он все время бы простаивал. В том же случае, если бы в качестве ОЗУ использовалась статическая память, то стоимость компьютера возросла бы в несколько раз.
Именно поэтому был разработан разумный компромисс. Основная часть ОЗУ так и осталась динамической, в то время как у процессора появилась своя быстрая кэш-память, основанная на микросхемах статической памяти. Ее объем сравнительно невелик – например, объем кэш-памяти второго уровня составляет всего несколько мегабайт. Впрочем, тут стоить вспомнить о том, что вся оперативная память первых компьютеров IBM PC составляла меньше 1 МБ.
Кроме того, на целесообразность внедрения технологии кэширования влияет еще и тот фактор, что разные приложения, находящиеся в оперативной памяти, по-разному нагружают процессор, и, как следствие, существует немало данных, требующих приоритетной обработки по сравнению с остальными.
Организация кэша
Теперь рассмотрим, как структурно устроен кэш. Как мы уже знаем, размер кэша всегда намного меньше размера оперативной памяти, поэтому необходимо, чтобы вместе с каждым блоком информации, сохраняемым в кэше, сохранялся адрес этого блока данных в оперативной памяти.
Рассмотрим гипотетический пример. Пусть имеется система с 32-разрядной адресацией памяти, то есть для задания адреса каждого байта памяти требуется четырехбайтный адрес. Предположим, что наш гипотетический кэш работает на уровне отдельных байтов, то есть может сохранять в качестве элемента байт оперативной памяти. Тогда каждый структурный элемент кэшпамяти должен сохранять не только байт данных оперативной памяти, но еще и его четырехбайтный адрес в оперативной памяти. Получается уже некое подобие строки, которая называется кэшстрокой (cache-line).
Адрес сохраняемого байта принято именовать тегом (tag).
При чтении данных из кэша процессор формирует адрес, который сравнивается с тегом кэшстроки. В случае совпадения кэш выдает требуемый байт данных, если же совпадения адреса с тегом нет (кэшпромах) — производится обращение к оперативной памяти. Понятно, что для реализации данного механизма необходимо дополнить каждую строку кэша еще и устройством сравнения адреса с тегом (рис. 2).
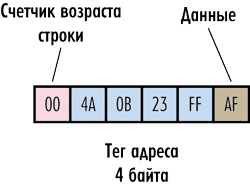
Рис. 2. Структура гипотетического кэша
Но и это еще не всё. Как мы уже отмечали, для реализации политики замещения на основе алгоритма FIFO или LRU, необходимо, чтобы каждая строка кэша была дополнена счетчикам возраста. Причем сколько именно байт отводится под счетчик, зависит от того, каков размер кэша. Если, к примеру, описанный нами кэш имеет размер 64 Кбайт, то в нем должно быть 65 536 строк. Тогда необходимо к каждой строке кэша добавить еще двухбайтовое поле (2 16 = 65 536), чтобы реализовать счетчик возраста строк.
Строка, к которой обращались в последнюю очередь, имеет возраст 0, а строка с самым поздним обращением — возраст 65 535.
В описанном выше гипотетическом кэше объем полезной сохраняемой информации в шесть раз меньше полного объема кэша, поскольку на каждый байт хранимых данных приходится еще шесть служебных байт. Понятно, что такая структура кэша абсолютно нецелесообразна.
Для того чтобы повысить объем полезной информации и одновременно уменьшить объем служебных данных, достаточно сохранять информацию в кэше не в виде отдельных байтов, а в виде блоков данных. То есть в каждой строке кэша будем сохранять не один байт данных, а блок данных фиксированного размера, идущих подряд в оперативной памяти, — он называется размером кэшстроки. Тегом строки будет адрес в оперативной памяти первого содержащегося в ней байта. Отметим, что блок сохраняемых данных в кэшстроке (то есть по сути сама кэшстрока) имеет строго фиксированный размер и является минимальной единицей информации, которая может быть считана из кэша или загружена в кэш. Размер кэшстроки может быть равен только степени двойки (2, 4, 8, 16 и т.д.) — рис. 3. Как мы помним, чтение из оперативной памяти (равно как и запись в нее) происходит пакетом данных, а кэш работает только с кэшстроками. Поэтому адрес первого байта кэшстроки всегда кратен размеру пакета данных, то есть начало кэшстроки всегда совпадает с началом пакета данных.
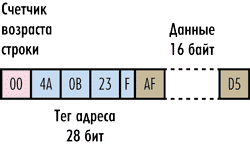
Рис. 3. Пример кэш-строки размером 16 байт
Теперь посмотрим, насколько эффективнее сохранять в кэшстроке не один байт, а фиксированный блок данных. Предположим, что размер кэшстроки составляет 32 байта. Возникает вопрос, какова должна быть при этом разрядность поля адреса тега? Если, как и ранее, рассматривается 32-разрядная адресация оперативной памяти, а тег, как мы отмечали, должен сохранять адрес первого байта кэшстроки, то, казалось бы, нужно четырехбайтовое поле адреса. Однако следует учесть, что данные в кэшстроках не могут перекрываться, а значит, теги всех строк должны быть кратны 32. Именно поэтому необходимая для адресации разрядность тега будет ниже. Предположим, к примеру, что в кэше сохраняется последовательная цепочка данных и адрес первого байта в оперативной памяти равен 0000 (в шестнадцатеричной системе). Тогда тег первой строки будет равен 0000, тег второй строки (адрес 32-го байта) — 0020, тег третьей строки — 0040 и т.д. То есть теги будут образовывать последовательность 0000, 0020, 0040, 0060, 0080, 00A0 и т.д. Если записать эту последовательность в двоичном виде, то можно заметить, что последние пять цифр в каждом теге всегда будут равны нулю. Эти пять нулей можно смело откинуть — тогда поле тега будет уже не 32-, а 27-битным.
Но в этом случае возникает вопрос: если процессору нужно получить доступ к отдельному байту, то как выделить его из кэшстроки? Всё очень просто. Процессор формирует именно 32-битный адрес, который делится на старшие 27 бит и младшие 5 бит. Старшие 27 бит используются для поиска нужной кэшстроки, а младшие 5 бит (смещение адреса) определяют конкретное положение нужного байта в строке, то есть по сути задают смещение данных относительно первого байта в кэшстроке. Этих пяти бит как раз достаточно для задания любого из 32 байт в строке кэша (2 5 =32).
Вообще, правило в данном случае работает такое. Как уже отмечалось, размер кэшстроки всегда равен степени двойки. Тогда размер смещения адреса равен log2 S, где S — размер кэшстроки в байтах. Соответственно размер тега (в битах) равен 32 –log2 S.
Так, если размер кэшстроки равен 16 байт, то размер смещения адреса — 4 битам, а размер тега адреса — 28 битам (рис. 3). Если размер кэшстроки равен 64 байтам, то размер смещения адреса — 6 битам, а размер тега адреса — 26 битам.
Понятно, что описанная нами структура кэшпамяти имеет куда лучшее соотношение полезного и полного размеров. Попутно отметим, что под указываемым в документации размером кэшпамяти всегда подразумевается полезный размер.
Рассмотрим конкретный пример. Пусть имеется кэш размером 32 Кбайт и длина строки составляет 128 байт. Исходя из предположения, что кэш имеет структуру, описанную выше, определим полный размер кэша.
Прежде всего, такой кэш будет содержать 256 строк (32 Кбайт/128 байт). Каждая строка имеет тег размером 25 бит (32 – log2 128). Кроме того, нужно добавить еще счетчик старения, содержащий 8 бит (log2 256). То есть к каждой строке добавляется еще 33 служебных бита. А всего таких служебных бит будет 8448 или 1056 байт. Соответственно полный объем кэша составит чуть более 33 Кбайт. То есть полный объем кэша лишь немного превосходит его полезный объем.
В рассмотренном нами кэше мы не учитывали так называемые биты модификации, которые также добавляются в каждой строке кэша и необходимы для поддержания когерентности, о которой мы расскажем далее. Однако наличие этих дополнительных служебных бит принципиально не меняет соотношение между полным и полезным размерами кэшпамяти.
Что такое кэш-память
Кэш-память представляет собой интегрированный в устройство выделенный раздел памяти для сохранения в нем временных рабочих данных и быстрого их извлечения. Она имеется в процессорах и иных устройствах (оперативной памяти, жестком диске) и обеспечивает существенный рост производительности и скорости обработки информации за счет оперативного доступа к нужным файлам. На флеш-накопителях (SSD) ее размер составляет до 4 Гб, на хард-дисках (HHD) – до 256 Мб.

При аппаратном кэшировании временные файлы удаляются, как правило, автоматически, участия пользователя в этом процессе не требуется. Часто он даже не знает о существовании такой системной функции.
Как узнать количество уровней и размер кэша на своем процессоре?
Начнем с того, что сделать это можно 3 способами:
- через командную строку (только кэш L2 и L3);
- путем поиска спецификаций в интернете;
- с помощью сторонних утилит.
Если взять за основу тот факт, что у большинства процессоров L1 составляет 32 КБ, а L2 и L3 могут колебаться в широких пределах, последние 2 значения нам и нужны. Для их поиска открываем командную строку через «Пуск» (вводим значение «cmd» через строку поиска).
Далее необходимо прописать значение «wmic cpu get L2CacheSize, L3CacheSize».
Система покажет подозрительно большое значение для L2. Необходимо поделить его на количество ядер процессора и узнать итоговый результат.

Если вы собрались искать данные в сети, то для начала узнайте точное имя ЦП. Нажмите правой кнопкой по иконке «Мой компьютер» и выберите пункт «Свойства». В графе «Система» будет пункт «Процессор», который нам, собственно, нужен. Переписываете его название в тот же Google или Yandex и смотрите значение на сайтах. Для достоверной информации лучше выбирать официальные порталы производителя (Intel или AMD).Третий способ также не вызывает проблем, но требует установки дополнительного софта вроде GPU-Z, AIDA64 и прочих утилит для изучения спецификаций камня. Вариант для любителей разгона и копошения в деталях.
Краткое резюме
- Существует аппаратный и программный кэш.
- Аппаратный кэш использует собственную память с быстрым доступом. Программный кэш – хранит данные в папке на диске.
- Аппаратный кэш способствует увеличению производительности компьютера, за счет уменьшения обращений к оперативной и дисковой памяти. Программный кэш ускоряет загрузку ранее просмотренной информации.
- Аппаратное увеличение кэш-памяти недоступно. Объем программной кэш-памяти ограничено свободным пространством на диске.
- Для освобождения памяти и увеличения быстродействия системы, программный кэш рекомендуется периодически очищать.
- Кэширование — процесс создания и сохранение в памяти копий файлов.
- Кэшированные данные — сохраненные копии файлов программ, приложений, страниц и др.
В статье мы детально описали, что такое кэш. В чем различия, а так же как устроена работа кэш-памяти. Промежуточный буфер обмена информацией способствует повышению быстродействия и производительности. При этом программный кэш лучше очищать несколько раз в год, что бы исключить переполнения и замедления работы компьютера или телефона.
Какие у вас есть вопросы? Задавайте интересующий вас вопрос в комментариях.
Для чего нужен кэш в процессоре?
Пришло время ответить на главный вопрос этой статьи, на что влияет кэш процессора? Данные поступают из ОЗУ в кэш L3, затем в L2, а потом в L1. Когда процессору нужны данные для выполнения операции, он пытается их найти в кэше L1 и если находит, то такая ситуация называется попаданием в кэш. В противном случае поиск продолжается в кэше L2 и L3. Если и теперь данные найти не удалось, выполняется запрос к оперативной памяти.
Теперь мы знаем, что кэш разработан для ускорения передачи информации между оперативной памятью и процессором. Время, необходимое для того чтобы получить данные из памяти называется задержкой (Latency). Кэш L1 имеет самую низкую задержку, поэтому он самый быстрый, кэш L3 — самую высокую. Когда данных в кэше нет, мы сталкиваемся с еще более высокой задержкой, так как процессору надо обращаться к памяти.
Раньше, в конструкции процессоров кєши L2 и L3 были были вынесены за пределы процессора, что приводило к высоким задержкам. Однако уменьшение техпроцесса, по которому изготавливаются процессоры позволяет разместить миллиарды транизисторов в пространстве, намного меньшем, чем раньше. Как результат, освободилось место, чтобы разместить кэш как можно ближе к ядрам, что ещё больше уменьшает задержку.
Сводка кеша
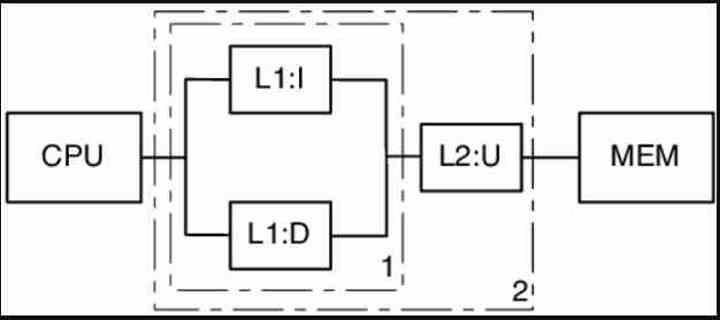
Прежде всего мы должны иметь в виду, что кеш не является пространством, адресуемым ЦП или графическим процессором, когда мы говорим об адресуемом пространстве, мы имеем в виду, что ЦП или графический процессор могут указывать на конкретный адрес памяти, где следующие данные или инструкция обрабатывать. Таким образом, ЦП не может указывать на кеш и, следовательно, не может им управлять.
Можно сказать, что механизмы кеширования работают автоматически, и когда ядро ЦП выполняет поиск, что оно делает, это просматривает различные кеши, чтобы найти конкретные данные. Когда ядро вносит изменения, все копии этих данных в остальных кэшах также автоматически обновляются. Точно так же механизмы кэширования сами решают, какие копии содержимого ОЗУ хранятся в кеше, а какие нет.
Кэш хранит копии памяти, наиболее близкие к строкам кода, которые выполняются в данный момент. Это связано с тем, что код в основном является последовательным, поэтому в большинстве случаев следующая строка программы для обработки будет следующей.
Не только числа
Кэш повышает производительность, ускоряя передачу данных в логические блоки и храня поблизости копию часто используемых инструкций и данных. Хранящаяся в кэше информация разделена на две части: сами данные и место, где они изначально располагаются в системной памяти/накопителе — такой адрес называется тег кэша (cache tag).
Когда процессор выполняет операцию, которой нужно считать или записать данные из/в память, то он начинает с проверки тегов в кэше Level 1. Если нужные данные там есть (произошло кэш-попадание (cache hit)), то доступ к этим данным выполняется почти сразу же. Промах кэша (cache miss) возникает, если требуемый тег не найден на самом нижнем уровне кэша.
В кэше L1 создаётся новый тег, а за дело берётся остальная часть архитектуры процессора выполняющая поиск в других уровнях кэша (при необходимости вплоть до основного накопителя) данных для этого тега. Но чтобы освободить пространство в кэше L1 под этот новый тег, что-то обязательно нужно перебросить в L2.
Это приводит к почти постоянному перемешиванию данных, выполняемому всего за несколько тактовых циклов. Единственный способ добиться этого — создание сложной структуры вокруг SRAM для обработки управления данными. Иными словами, если бы ядро процессора состояло всего из одного ALU, то кэш L1 был бы гораздо проще, но поскольку их десятки (и многие из них жонглируют двумя потоками инструкций), то для перемещения данных кэшу требуется множество соединений.
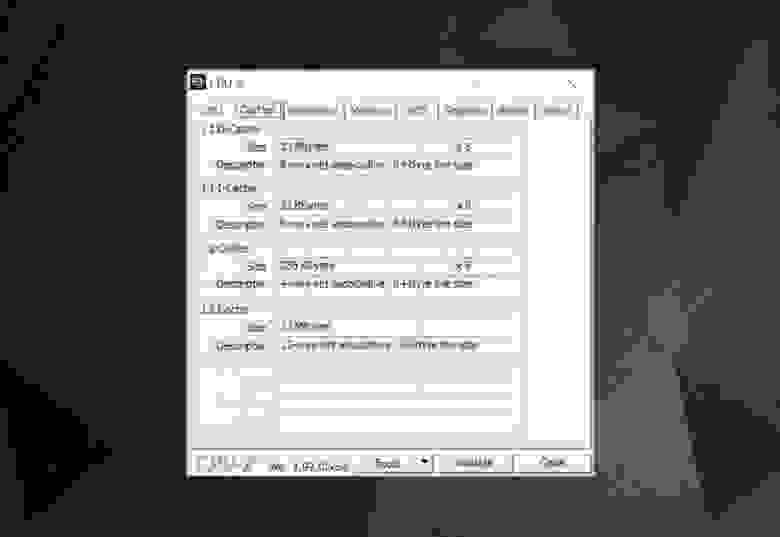
Для изучения информации кэша в процессоре вашего компьютера можно использовать бесплатные программы, например CPU-Z. Но что означает вся эта информация? Важным элементом является метка set associative (множественно-ассоциативный) — она указывает на правила, применяемые для копирования блоков данных из системной памяти в кэш.
Представленная выше информация кэша относится к Intel Core i7-9700K. Каждый из его кэшей Level 1 разделён на 64 небольших блока, называемые sets, и каждый из этих блоков ещё разбит на строки кэша (cache lines) (размером 64 байта). «Set associative» означает, что блок данных из системы привязывается к строкам кэша в одном конкретном сете, и не может свободно привязываться к какому-то другому месту.
«8-way» означает, что один блок может быть связан с 8 строками кэша в сете. Чем выше уровень ассоциативности (т.е. чем больше «way»), тем больше шансов на кэш-попадание во время поиска процессором данных и тем меньше потери, вызываемые промахами кэша. Недостатки такой системы заключаются в повышении сложности и энергопотребления, а также понижении производительности, потому что для каждого блока данных нужно обрабатывать больше строк кэша.

Инклюзивный кэш L1+L2, victim cache L3, политики write-back, есть даже ECC. Источник: Fritzchens Fritz
Ещё один аспект сложности кэша связан с тем, как хранятся данные между разными уровнями. Правила задаются в inclusion policy (политике инклюзивности). Например, процессоры Intel Core имеют полностью инклюзивные кэши L1+L3. Это означает, что одни данные в Level 1, например, могут присутствовать в Level 3. Может показаться, что это пустая трата ценного пространства кэша, однако преимущество заключается в том, что если процессор совершает промах при поиске тега в нижнем уровне, ему не потребуется обыскивать верхний уровень для нахождения данных.
В тех же самых процессорах кэш L2 неинклюзивен: все хранящиеся там данные не копируются ни на какой другой уровень. Это экономит место, но приводит к тому, что системе памяти чипа нужно искать ненайденный тег в L3 (который всегда намного больше). Victim caches (кэши-жертвы) имеют похожий принцип, но они используются для хранения информации, переносимой с более низких уровней. Например, процессоры AMD Zen 2 используют victim cache L3, который просто хранит данные из L2.
Существуют и другие политики для кэша, например, при которых данные записываются и в кэш, и основную системную память. Они называются политиками записи (write policies); большинство современных процессоров использует кэши write-back — это означает, что когда данные записываются на уровень кэшей, происходит задержка перед записью их копии в системную память. Чаще всего эта пауза длится в течение того времени, пока данные остаются в кэше — ОЗУ получает эту информацию только при «выталкивании» из кэша.

Графический процессор Nvidia GA100, имеющий 20 МБ кэша L1 и 40 МБ кэша L2
Для проектировщиков процессоров выбор объёма, типа и политики кэшей является вопросом уравновешивания стремления к повышению мощности процессора с увеличением его сложности и занимаемым чипом пространством. Если бы можно было создать 1000-канальные ассоциативные кэши Level 1 на 20 МБ такими, чтобы они при этом не занимали площадь Манхэттена (и не потребляли столько же энергии), то у нас у всех бы были компьютеры с такими чипами!
Самый нижний уровень кэшей в современных процессорах за последнее десятилетие практически не изменился. Однако кэш Level 3 продолжает расти в размерах. Если бы десять лет назад у вас было 999 долларов на Intel i7-980X, то вы могли бы получить кэш размером 12 МБ. Сегодня за половину этой суммы можно приобрести 64 МБ.
Подведём итог: кэш — это абсолютно необходимое и потрясающее устройство. Мы не рассматривали другие типы кэшей в CPU и GPU (например, буферы ассоциативной трансляции или кэши текстур), но поскольку все они имеют такую же простую структуру и расположение уровней, разобраться в них будет несложно.
Был ли у вас компьютер с кэшем L2 на материнской плате? Как насчёт слотовых Pentium II и Celeron (например, 300a) на дочерних платах? Помните свой первый процессор с общим L3?
На правах рекламы
Наша компания предлагает в аренду серверы с процессорами от Intel и AMD. В последнем случае — это эпичные серверы! VDS с AMD EPYC, частота ядра CPU до 3.4 GHz. Максимальная конфигурация — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe.











