Сколько символов в компьютерном алфавите
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа «=», «(«, «&» и т.п. и даже (обратите особое внимание!) пробелы между словами. Да, не удивляйтесь: пустое место в тексте тоже должно иметь свое обозначение.
Вспомним некоторые известные нам факты:
Множество символов, с помощью которых записывается текст, называется алфавитом.
Число символов в алфавите – это его мощность.
Формула определения количества информации: N = 2 b ,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 2 8 , то вес 1 символа – 8 бит.
Единице измерения 8 бит присвоили название 1 байт:
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Каким же образом текстовая информация представлена в памяти компьютера?
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер – по их коду.
Удобство побайтового кодирования символов очевидно, поскольку байт – наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.
Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Алфавитный подход к измерению информации
А теперь обсудим вопрос о том, как можно измерять информацию. Существует несколько подходов к измерению информации. Здесь мы рассмотрим только один, который называется алфавитным подходом * .
Алфавитный подход позволяет измерять информационный объем текста на некотором языке (естественном или формальном), не связанный с содержанием этого текста.
Вам хорошо известно, что существуют единицы измерения таких величин, как, например, расстояние, масса, время. Для расстояния — это метр, для массы — грамм, для времени — секунда. Измерение происходит путем сопоставления измеряемой величины с единицей измерения.
* О другом подходе к измерению информации см. в разделе 1.1 материала для углубленного изучения «Дополнение к главе I».
Сколько раз единица измерения укладывается в измеряемой величине, таков и результат измерения. Следовательно, и для измерения информации должна быть введена своя единица измерения.
Кодирование символьной информации в компьютере

Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер — по их коду.
Поскольку байт — наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста.
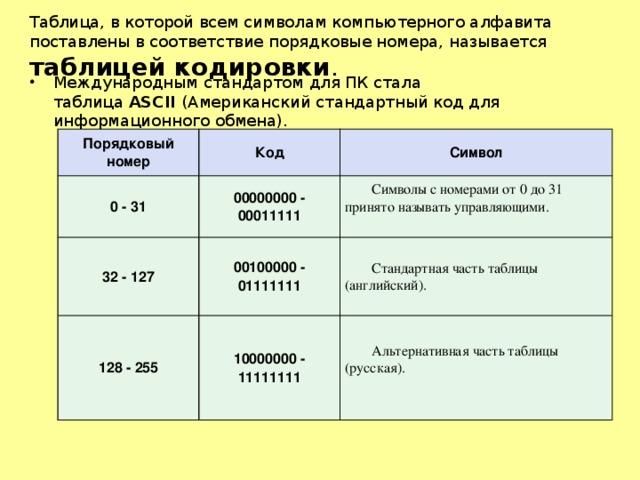
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки .
- Международным стандартом для ПК стала таблица ASCII (Американский стандартный код для информационного обмена).
Порядковый номер
00000000 — 00011111
00100000 — 01111111
Символы с номерами от 0 до 31 принято называть управляющими.
Стандартная часть таблицы (английский).
10000000 — 11111111
Альтернативная часть таблицы (русская).
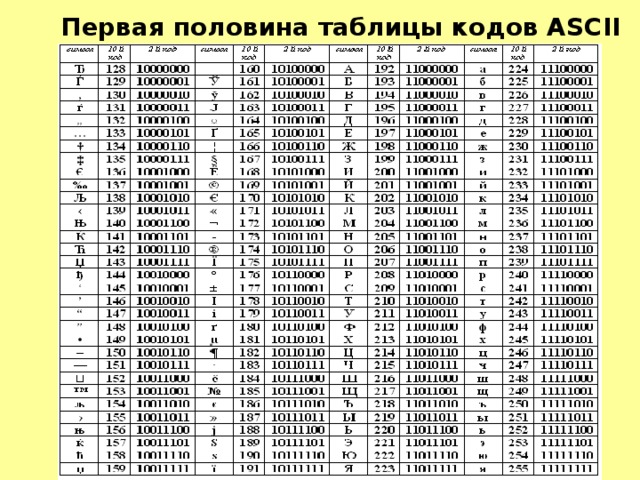
Первая половина таблицы кодов ASCII
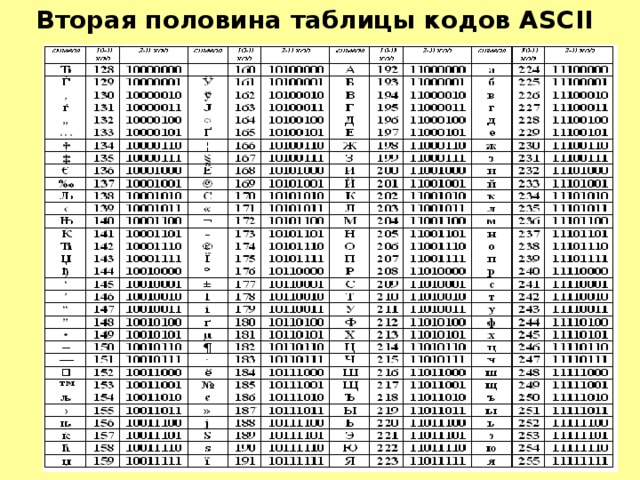
Вторая половина таблицы кодов ASCII

Компьютеры фирмы Apple , работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251 .
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode . Это 16-разрядная кодировка , т.е. в ней на каждый символ отводится 2 байта памяти . Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов .
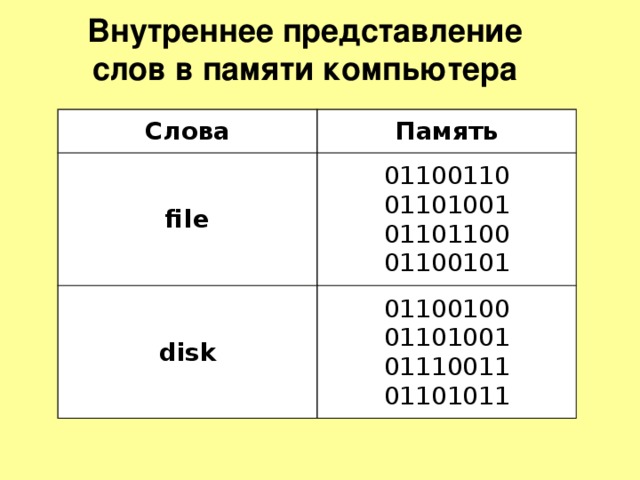
Внутреннее представление слов в памяти компьютера

Используя таблицу ASCII, закодируйте в двоичной форме свою фамилию.
Используя таблицу ASCII, закодируйте в двоичной форме слово byte.
Закодируйте короткую фразу на русском языке. Обменяйтесь полученными кодами с соседом и декодируйте тексты друг друга.
1.Какое количество символов содержит алфавит, используемый для представления текстовой информации в компьютере
5.В таблице кодировки ASCII стандартными(неизменными) являются только символы с номерами
2.Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует
- 256.1024.128
- 256.
- 1024.
- 128
- от 127 до 255.от 0 до 127.от 0 до 255.
- от 127 до 255.
- от 0 до 127.
- от 0 до 255.
- четырехразрядный двоичный код.восьмиразрядный двоичный код.шестнадцатиразрядный двоичный код.
- четырехразрядный двоичный код.
- восьмиразрядный двоичный код.
- шестнадцатиразрядный двоичный код.
6.Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется
3.Двоичный код каждого символа в компьютерном тексте занимает
- таблицей NTFS.таблицей FAT.таблицей кодировки.
- таблицей NTFS.
- таблицей FAT.
- таблицей кодировки.
- 1 байт памяти.1 бит памяти .8 байтов памяти.
- 1 байт памяти.
- 1 бит памяти .
- 8 байтов памяти.
7.С развитием персональных компьютеров типа IBM PC международным стандартом стала таблица кодировки символов
4.В русских национальных кодировках во второй части таблицы ASCII(от 128 до 255) размещаются
- Windows.NTFS.ASCII.
- Windows.
- NTFS.
- ASCII.
- символы русского языка.особые управляющие символы.символы латинского языка.
- символы русского языка.
- особые управляющие символы.
- символы латинского языка.
Как текстовая информация может выглядеть в памяти компьютера?
Любой текст набирают на клавиатуре, на клавишах клавиатуры, мы видим привычные для нас знаки (цифры, буквы и т.д.). В оперативную память компьютера они попадают только в виде двоичного кода. Двоичный код каждого символа, выглядит восьмизначным числом, например 00111111.
Поскольку, байт – это самая маленькая адресуемая частица памяти, и память обращена к каждому символу отдельно – удобство такого кодирование очевидно. Однако, 256 символов – это очень удобное количество для любой символьной информации.
Естественно, встал вопрос: Какой конкретно восьми разрядный код принадлежит каждому символу? И как осуществить перевод текста в цифровой код?
Этот процесс условный, и мы вправе придумать различные способы для кодировки символов. Каждый символ алфавита имеет свой номер от 0 до 255. И каждому номеру присвоен код от 00000000 до 11111111.
Таблица для кодировки – это «шпаргалка», в которой указаны символы алфавита в соответствии порядковому номеру. Для различных типов ЭВМ используют разные таблицы для кодировки.
ASCII(или Аски), стала международным стандартом для персональных компьютеров. Таблица имеет две части.
Самое главное.
При алфавитном подходе считается, что каждый символ некоторого сообщения имеет опредёленный информационный вес — несёт фиксированное количество информации.
1 бит — минимальная единица измерения информации.
Информационный вес символа алфавита i и мощность алфавита N связаны между собой соотношением: N = 2 i .
Информационный объём сообщения I равен произведению количества символов в сообщении К на информационный вес символа алфавита i: I = K•i.
1 байт = 8 битов.
Байт, килобайт, мегабайт, гигабайт, терабайт — единицы измерения информации. Каждая следующая единица больше предыдущей в 1024 (210) раза.
Принцип алфавитного подхода к оценке количества информации
Алфавитный подход строится на принципе, утверждающем, что любое сообщение можно представить в виде кодов с помощью конечной последовательности символов, содержащейся в любом алфавите. Носители информации содержат любые последовательности символов, которые могут храниться, передаваться и обрабатываться как с помощью человека, так и с помощью технических устройств, в частности компьютера. Этот подход описал А.Н. Колмогоров, согласно которому, информативность, заключающаяся в последовательности символов, не может зависеть от содержания самого сообщения, а может определяться лишь минимальным количеством символов, необходимых для ее кодирования. Подобный подход к оценке количества информации носит объективный характер, так как не зависит от получателя, принимающего сообщения. Смысл же сообщений может учитываться только на этапе выбора алфавита кодирования либо не учитываться совсем.
В основу принципа этого подхода лег подсчет числа символов в сообщении, таким образом, важна только длина сообщения и совсем не учитывается его содержание. Однако на длину сообщения может влиять мощность алфавита используемого языка.
Самый простой способ разобраться в этом — рассмотреть пример любого текста, написанного на каком-нибудь языке. Для нас, конечно же, удобным будет текст на русском языке.
4.2. Информационный вес символа произвольного алфавита
Ранее мы выяснили, что алфавит любого естественного или формального языка можно заменить двоичным алфавитом. При этом мощность исходного алфавита N связана с разрядностью двоичного кода i, требуемой для кодирования всех символов исходного алфавита, соотношением: N = 2 i .
Разрядность двоичного кода принято считать информационным весом символа алфавита. Информационный вес символа алфавита выражается в битах.
| Информационный вес i символа алфавита и мощность N алфавита связаны между собой соотношением: N = 2 i . |
Задача 1. Алфавит племени Пульти содержит 8 символов. Каков информационный вес символа этого алфавита?
Решение. Составим краткую запись условия задачи.

Известно соотношение, связывающее величины i и N: N = 2 i .
С учетом исходных данных: 8 = 2 i . Отсюда: i = 3.
Полная запись решения в тетради может выглядеть так:

Несколько советов программистам
Допустим, программист решил реализовать текстовый редактор, поддерживающий алфавит языка Бопомофо. Символы данного языка располагаются в таблице Юникод в диапазоне 12549-12589 и, следовательно, программисту необходимо выбрать стандарт UTF-16 для кодирования. Предположим, что для ввода символов решено использовать программную клавиатуру, состоящую из кнопок, каждая из которых соответствует букве алфавита языка. Кнопки – объекты класса button. Нажатие пользователем на какую-либо из кнопок порождает событие, в результате которого приложению становится известен номер ячейки таблицы Юникод. Программисту рекомендуется:
1.Хранить в памяти приложения символы таблицы Юникод и номера ячеек, соответствующие только языкам, поддержка которых планируется в текстовом редакторе. Это уменьшит объем памяти, занимаемой приложением, а также повысит скорость его работы, сузив область поиска номера ячейки.
2. При реализации приложения заранее выполнить преобразование всех номеров ячеек в их бинарные коды. Результат преобразования сохранить в файле, в формализованном виде. При загрузке приложения выполнить считывание в память номеров ячеек и их бинарных кодов UTF-16. Это позволит снизить вычислительную нагрузку приложения в ходе его работы.
3. Для хранения номеров ячеек и их бинарных кодов использовать объект класса, позволяющего осуществить это в виде ключ-значение, где ключ – номер ячейки, а значение – бинарный код. Классы, реализующие в языках программирования данный функционал, организуют работу таким образом, чтобы минимизировать время поиска ключа, используя сортировку ключей или хеширование.
Отметим проблему кодирования составных символов, которая является важным техническим аспектом. Например, символ ü может быть интерпретирован, как самостоятельный символ, которому соответствует номер ячейки 252 или может быть скомпонован из двух символов: u, которому соответствует номер ячейки 117 и символа ¨, которому соответствует номер ячейки 776. Программист должен строго придерживаться одного из вариантов представления таких символов иначе побайтовое сравнение строк будет невозможно. Рекомендуется использование второго варианта, который может облегчить поиск составных символов в тексте. Например, если пользователь осуществляет поиск символа u, то ему может быть выведен в качестве результата, как составной символ ü, так и самостоятельный u.











