Работа 10. Создаём многоуровневые списки
Представим перечень устройств современного компьютера в виде многоуровневого списка, имеющего четыре уровня вложенности:
-
1. Процессор
- Откройте файл Природа России.doc (Природа России.оdt) из папки Заготовки.
- Переструктурируйте информацию в виде многоуровневого списка. Один из возможных вариантов оформления представлен ниже:
- t(q,1)=k (нам поручено найти t(q,r)) => t(1,1) = q/k, почему? Потому что, если мы не предполагаем, что время зависит только от количества инструкций, а не от типа инструкций, мы в действительности находимся там, где эта задача неразрешима. В таком случае q не будет рассматриваться как число, и мы не можем предположить, что другой набор инструкций займет меньше или больше времени в зависимости от количества инструкций. В заключение, насколько я понимаю в этой задаче, они связывают время только с количеством инструкций.
- если программа является родной на одном уровне ‘r’, то для ее интерпретации (сделать ее родной) потребуется n инструкций другого уровня. В определении задачи (представленном здесь) нет ничего, что заставляло бы вас интерпретировать только инструкции уровня r+1. На самом деле, поскольку мы начинаем с первого уровня, «n инструкций уровня r требуется для интерпретации одной инструкции r+1» было бы довольно бесполезно, если бы мы не могли предположить, что я говорю выше.
- кроме того, инструкции уровня q X после интерпретации всегда должны преобразовываться в инструкции уровня q Y, иначе мы никогда не сможем узнать время выполнения другого уровня, потому что количество инструкций может сильно варьироваться (как в реальном мире)
2. Память
-
2.1. Оперативная память
2.2. Долговременная память
-
2.2.1. Жёсткий магнитный диск
2.2.2. Флеш-память
2.2.3. Лазерные диски
-
2.2.3.1. CD
2.2.3.2. DVD
-
3.1. Клавиатура
3.2. Мышь
3.3. Сканер
3.4. Графический планшет
3.5. Цифровая камера
3.6. Микрофон
3.7. Джойстик
-
4.1. Монитор
-
4.1.1. Жидкокристаллический монитор
4.1.2. Монитор на электронно-лучевой трубке
-
4.2.1. Матричный принтер
4.2.2. Струйный принтер
4.2.3. Лазерный принтер
1) (для Windows) выделите все оставшиеся строки;
2) (для Windows) на вкладке Главная в группе Абзац щёлкните на стрелке рядом с командой Многоуровневый список.
2) (для Linux) отдайте команду Формат — Маркеры и нумерация. В диалоговом окне Маркеры и нумерация перейдите на вкладку Структура;
-
Откройте файл Водные системы.doc (Водные системы.оdt) из папки Заготовки:
Урок 16
Математические модели. Многоуровневые списки
Практическая работа №10
«Создаём многоуровневые списки»

1. Откройте файл Устройства.doc для или Устройства.odt для из папки Заготовки.
2. Задайте для первой строки полужирное начертание.
3. Преобразуйте оставшиеся строки в многоуровневый список. Для этого:
1) выделите все оставшиеся строки;
 |
2) на вкладке Главная в группе Абзац щёлкните на стрелке рядом с командой Многоуровневый список  ; ; |
 |
2) отдайте команду Формат — Маркеры и нумерация. В диалоговом окне Маркеры и нумерация перейдите на вкладку Структура; |
3) открывшемся диалоговом окне выберите список типа, изображённого справа.
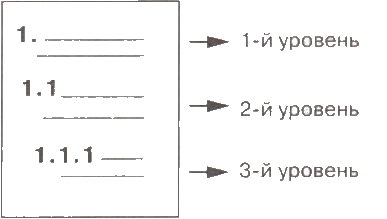
4. Исходный текст приобрёл вид нумерованного списка. Все его пункты получили самый высокий 1-й уровень. Но такой уровень могут занимать только пункты «Процессор», «Память», «Устройства ввода» и «Устройства вывода». Уровень остальных пунктов следует понизить (создать вложение пунктов). Для этого воспользуйтесь кнопкой:
|
Увеличить отступ  на вкладке Главная в группе Абзац на вкладке Главная в группе Абзац |
|
Понизить на один уровень  на панели инструментов Маркеры и нумерация на панели инструментов Маркеры и нумерация |
5. Выделите пункты 3-9 и понизьте их уровень.
6. Выделите пункты 2.3-2.7 и понизьте их уровень.
7. Выделите пункты 2.2.4-2.2.5 и понизьте их уровень.
8. Повторите аналогичные операции для других пунктов списка.
9. Сохраните документ в личной папке под именем Устройства1.

Следующая страница Компьютерный практикум. Работа 10 «Создаём многоуровневые списки». Задание 2

Cкачать материалы урока
Учитель информатики
Почему в современных компьютерах используются устройства памяти нескольких уровней, различающиеся по времени доступа, сложности, объёму и стоимости?
На данный момент самыми быстрыми считаются SSD накопители формата M.2, естественно и стоят они дороже. Обычно накопители SSD используются для операционной системы, в то время как менее быстрые и дорогие HDD диски используются для хранения файлов и тд.
4 ответа
Я нашел этот документ на официальной странице ORACLE, когда искал информацию о колонках Computed/Automatic/Virtual: http://www.oracle.com/technetwork/БД/БДР/автоматическая-столбцы-132042.pdf (название: руководство по использованию SQL: компьютерная и механическая колонны. Особенность Oracle Rdb).
Я не специалист по базам данных. Мое понимание моделирования данных не очень обширно. Исходя из этого ограниченного понимания, логическая модель данных является абстракцией физической модели данных, не содержащей ничего специфичного для конкретного хранилища product/medium. логическое.
Я думаю, вы все это слишком усложняете. Другими словами, в постановке задачи говорится, что каждый слой работает в m раз быстрее, чем слой выше. Следовательно, слой 2 завершает программы за 1/м времени, слой 3 — за 1/м * 1/м и так далее. Таким образом, окончательное уравнение просто:
Это просто рекурсивная функция:
Я не уверен, что определение задачи завершено, потому что, если это так, я не вижу другого разумного способа ее решения, кроме упрощения.
Итак, вот несколько вещей, которые я бы предположил:
Итак, вот ответ с этими предварительными условиями:
Если какое-либо из 3 предположений неверно, вам нужно ввести новые неизвестные функции, чтобы ответ стал просто уравнением неизвестных функций, которое было бы бесполезным, но гораздо более бесполезным, чем это. Этот просто красивее 🙂
Кстати, вам нужно посмотреть на свои упражнения в университете, чтобы увидеть, как были решены аналогичные задачи, чтобы убедиться, что подход к проблеме правильный.
Я думал, что это просто, но все же это дает мне нежелательный результат (логическая ошибка). Я запрашиваю записи сотрудников, каждая из которых имеет свои связанные кредитные записи (отношение one-to-many). Моя проблема заключается в том, что когда у сотрудника есть 2 кредита, чем возвращенные.
Я использую приведенный ниже код для сортировки списка. sortOptions: [‘amount:desc’,’place’] Ember.computed.sort(‘model’,sortOptions) Ключ amount-это в основном число, но в JSON model оно приходит как строка. Итак, когда я запускал этот код, он не сортировался по сумме, но когда я изменил JSON.
Проблема просто гласит, что если на уровне 1 требуется k единиц времени, то k/m единиц он будет принимать на втором уровне, как и так далее.
Работа 5. Многоуровневые списки
Представим перечень устройств современного компьютера в виде многоуровневого списка, имеющего четыре уровня вложенности:

1. Откройте файл Устройства.doc.
2. Придайте первой строке стиль форматирования Заголовок 1.
3. Преобразуйте оставшиеся строки в многоуровневый список. Для этого:
1) выделите все оставшиеся строки;
2) отдайте команду [Формат-Список]. В диалоговом окне Список перейдите на вкладку Многоуровневый и выберите там список типа:
4. Исходный текст приобрел вид нумерованного списка.
Все его пункты получили самый высокий 1-й уровень. Но такой уровень могут занимать только пункты «Процессор», «Память», «Устройства ввода» и «Устройства вывода». Уровень остальных пунктов следует понизить ( создать вложение пунктов ). Для
этого воспользуемся кнопкой Увеличить отступ на панели инструментов Главная .
Выделите пункты 3-10 и понизьте их уровень.
Выделите пункты 2.3-2.8 и понизьте их уровень.
Выделите пункты 2.2.5-2.2.6 и понизьте их уровень.
5. Повторите аналогичные операции для других пунктов списка.
6. Сохраните документ в собственной папке под именем Устройства.
Задание 2. Природа России
1. Откройте файл Природа России.doc из папки Заготовки.
2. Переструктурируйте информацию в виде многоуровневого списка. Один из возможных вариантов оформления представлен ниже:

3. Сохраните многоуровневый список в собственной папке под именем Млекопитающие.
Задание 3. Водные системы
1. Откройте файл Водные системы.dос.
2. Переструктурируйте информацию в виде многоуровневого списка. Вариант оформления придумайте сами.
3. Сохраните многоуровневый список в собственной папке под именем Водные системы 1.
Задание 4. Творческое задание
Придумайте сами пример объектов, информацию о которых удобно представить в виде многоуровневого списка. Создайте соответствующий многоуровневый список. Сохраните его в собственной папке под именем Идея1.