Краткое объяснение кодирования текстовой информации. Информатика
Кодирование текстовой информации — очень распространенное явление. Один и тот же текст может быть закодирован в нескольких форматах. Принято считать, что кодирование текстовой информации появилось с приходом компьютеров. Это и так и не так одновременно. Кодировка в том виде, в котором мы ее знаем, действительно к нам пришла с приходом компьютеров. Но над самим процессом кодирования люди бьются уже много сотен лет. Ведь, по большому счету, сама письменность уже является способом закодировать человеческую речь, для ее дальнейшего использования. Вот и получается, что любая окружающая нас информация никогда не бывает представленной в чистом виде, потому что она уже каким-то образом закодирована. Но сейчас не об этом.
Самый распространенный способ кодирования текстовой информации — это ее двоичное представление, которое сплошь и рядом используется в каждом компьютере, роботе, станке и т. д. Все кодируется в виде слов в двоичном представлении.
Сама технология двоичного представления информации зародилась еще задолго до появления первых компьютеров. Среди первых устройств, которые использовали двоичный метод кодирования, был аппарат Бодо — телеграфный аппарат, который кодировал информацию в 5 битах в двоичном представлении. Суть кодировки заключалась в простой последовательности электрических импульсов:
- 0 — импульс отсутствует;
- 1 — импульс присутствует.
В компьютерный мир такая кодировка пришла вместе с персонализацией самих компьютеров. То есть в первых компьютерах не было такой кодировки. Но как только компьютеры стали уходить «в массы», то резко обнаружилась потребность обрабатывать компьютерами большое количество именно текстовой информации, которую нужно было как-то кодировать. Тенденция обрабатывать большое количество текстовой информации сохранилась и в современных устройствах.
Так получилось, что двоичное кодирование в компьютерах связано только с двумя символами «0» и «1», которые выстраиваются в определенной логической последовательности. А сам язык подобной кодировки стал называться машинным.
Таблица кодирования ASCII.
А теперь «заглянем» в память компьютера и разберемся, как же представлена в нем текстовая информация.
Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и других. Мы уже говорили, что множество всех символов, с помощью которых записывается текст, называется алфавитом, а число символов в алфавите — его мощностью.
Для представления текстовой информации в компьютере используется алфавит мощностью 256 символов. Мы знаем, что один символ такого алфавита несет 8 битов информации: 2 в 8 степени равно 256. 8 битов = 1 байт, следовательно:
Один символ в компьютерном тексте занимает 1 байт памяти.
Как мы выяснили, традиционно для кодирования одного символа используется 8 бит. И, когда люди определились с количеством бит, им осталось договориться о том, каким кодом кодировать тот или иной символ, чтобы не получилось путаницы, т.е. необходимо было выработать стандарт – все коды символов сохранить в специальной таблице кодов. В первые годы развития вычислительной техники таких стандартов не существовало, а сейчас наоборот, их стало очень много, но они противоречивы. Первыми решили эти проблемы в США, в институте стандартизации. Этот институт ввел в действие таблицу кодов ASCII (AmericanStandardCodeforInformationInterchange – стандартный код информационного обмена США).
Рассмотрим таблицу кодов ASCII.
Пояснение: раздать учащимся распечатанную таблицу кодов ASCII.
Таблица ASCII разделена на две части. Первая – стандартная – содержит коды от 0 до 127. Вторая – расширенная – содержит символы с кодами от 128 до 255.
Первые 32 кода отданы производителям аппаратных средств и называются они управляющие, т.к. эти коды управляют выводом данных. Им не соответствуют никакие символы.
Коды с 32 по 127 соответствуют символам английского алфавита, знакам препинания, цифрам, арифметическим действиям и некоторым вспомогательным символам.
Коды расширенной части таблицы ASCII отданы под символы национальных алфавитов, символы псевдографики и научные символы.
Стандартная часть таблицы кодов ASCII
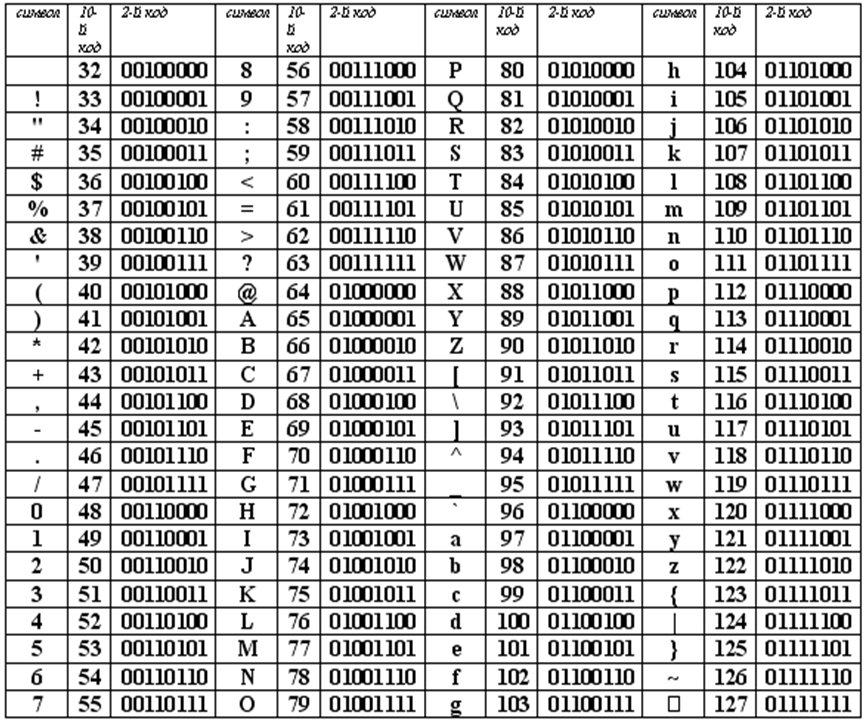
Если вы внимательно посмотрите на обе части таблицы, то увидите, что все буквы расположены в них по алфавиту, а цифры – по возрастанию. Этот принцип последовательного кодирования позволяет определить код символа, не заглядывая в таблицу.
Коды цифр берутся из этой таблицы только при вводе и выводе и если они используются в тексте. Если же они участвуют в вычислениях, то переводятся в двоичную систему счисления.
Коды национального (русского) алфавита расширенной частитаблицы ASCII
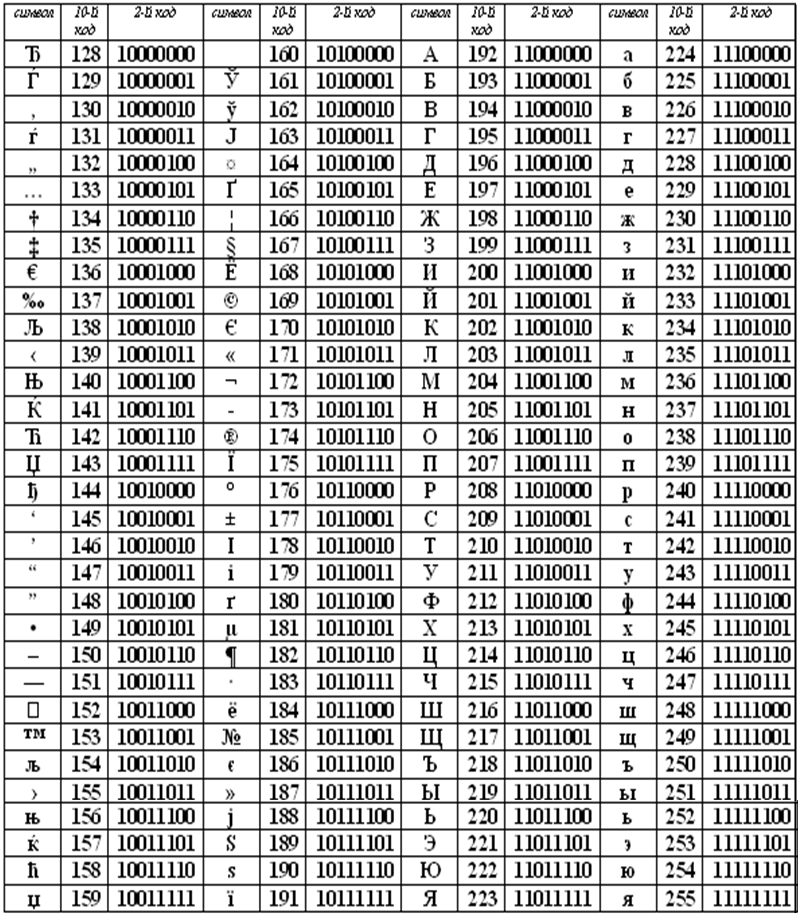
Текстовые документы
Любой текст, созданный с помощью текстового редактора, вместе с включёнными в него нетекстовыми материалами называют документом.
Текстовый документ может быть статьёй, докладом, рассказом, стихотворением, приглашением, объявлением, поздравительной открыткой. При работе в сети части одного сложного документа могут храниться на разных компьютерах, расположенных далеко друг от друга.
Гипертекст — это способ организации документа, позволяющий быстро находить нужную информацию. Он часто используется при построении систем оперативной подсказки и компьютерных версий больших справочников и энциклопедий. Переход с одного места в гипертексте на другое осуществляется с помощью ссылок. Например, пусть вы читаете энциклопедию о животных, и вас особенно интересует информация о собаках. Предположим, что слово «бульдог» подчёркнуто — это обозначает ссылку внутри гипертекста. Если вы щёлкнете на этом слове мышью, то попадёте в другую статью энциклопедии, которая рассказывает про эту породу собак.
Основными объектами текстового документа являются: символ, слово, строка, абзац, страница, фрагмент.
Символ — цифра, буква, знак препинания и т. д.
Слово — произвольная последовательность символов (букв, цифр и др.), ограниченная с двух сторон служебными символами (такими как пробел, запятая, скобки и др.).
Строка — произвольная последовательность символов между левой и правой границами документа.
Абзац — произвольная последовательность символов, ограниченная специальными символами конца абзаца. Допускаются пустые абзацы.
Фрагмент — произвольная последовательность символов. Фрагментом может быть отдельное слово, строка, абзац, страница и даже весь вводимый текст.
Представление графических типов информации в ПК
Сейчас существует два способа представления графических данных в машинном коде.
Растровый
Суть этого способа заключается в том, что графическое изображение делится на маленькие фрагменты, которые называются пиксели. Каждый пиксель содержит в себе информацию о своем цвете. Данный способ называется растровым кодированием.

Так в черно-белой графической картинке цвет точки описывается одним битом. Если пиксель черный, то 1, если белый, то 0. Для того, чтобы представить цветную картинку используют палитру цветов RGB. Каждый оттенок получается с помощью смешивания красного, зеленого и синего цвета. В этом случае один фрагмент кодируется 24 битами, а пиксель может содержать один из шестнадцати миллионов оттенков. Данный способ имеет большой недостаток — при изменении масштаба документа теряется его качество.
Векторный
В отличие от растрового кодирования, в данном способе представление графики описывается с помощью векторов. Каждому вектору задают координаты начала и конца, толщину и цвет. Например, для отрисовки окружности надо будет задать координаты её центра и радиус, цвет заполнения (если он есть), а также цвет и толщину контура.

Преимущества такого представления в том, что при изменении размера изображения его качество остается неизменным. Однако есть один существенный недостаток — при обработке сложного фотографического изображения необходимо большое количество фигур для его описания. Этот тип графики применяется для работы с чертежами и разработки рекламных баннеров.
Если есть сигнал — единичка, если нет — нолик
В статье «Пять поколений ЭВМ» перечисляется элементная база компьютеров разных поколений: электронные лампы, транзисторы, микросхемы. До сих пор ничего принципиально нового не появилось.
Перечисленные элементы четко распознают только два состояния: включено или выключено, есть сигнал или нет сигнала. Для того чтобы закодировать эти два состояния, достаточно двух цифр: 0 (нет сигнала) и 1 (есть сигнал).
Таким образом, с помощью комбинации 0 и 1 компьютер (с первого поколения и по сей день) способен воспринимать любую информацию: тексты, формулы, звуки и графику.
Иными словами, компьютеры обычно работают в двоичной системе счисления, состоящей из двух цифр 0 и 1. Все необходимые преобразования (в привычную для нас форму или, наоборот, в двоичную систему счисления) могут выполнить программы, работающие на компьютере.
Обычная для нас десятичная форма счисления состоит из десяти цифр: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. Кстати, числа 10 в этом списке нет: оно состоит из 0 и 1 — чисел, входящих в десятичную систему счисления.
В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобретя в каталоге.



Текстовая информация
Принципиально важно, что текстовая информация уже дискретна — состоит из отдельных знаков. Поэтому возникает лишь технический вопрос — как разместить ее в памяти компьютера.
Напомним о байтовом принципе организации памяти компьютеров, обсуждавшемся в курсе информатики основной школы. Вернемся к рис. 1.5. Каждая клеточка на нем обозначает бит памяти. Восемь подряд расположенных битов образуют байт памяти. Байты пронумерованы. Порядковый номер байта определяет его адрес в памяти компьютера. Именно по адресам процессор обращается к данным, читая или записывая их в память (рис. 1.10).

Рис. 1.10. Байтовая организация памяти
Модель представления текста в памяти весьма проста. За каждой буквой алфавита, цифрой, знаком препинания и иным общепринятым при записи текста символом закрепляется определенный двоичный код, длина которого фиксирована. В популярных системах кодировки (Windows-1251, КОI8 и др.) каждый символ заменяется на 8-разрядное целое положительное двоичное число; оно хранится в одном байте памяти. Это число является порядковым номером символа в кодовой таблице. Согласно главной формуле информатики, определяем, что размер алфавита, который можно закодировать, равен: 2 8 = 256. Этого количества вполне достаточно для размещения двух алфавитов естественных языков (английского и русского) и всех необходимых дополнительных символов.
Поскольку в мире много языков и много алфавитов, постепенно совершается переход на международную систему кодировки Unicode, в которой используются многобайтовые коды. Например, если код символа занимает 2 байта, то с его помощью можно закодировать 2 16 = 65 536 различных символов.
При работе с электронной почтой почтовая программа иногда нас спрашивает, не хотим ли мы прибегнуть к кодировке Unicode для пересылаемых сообщений. Таким способом можно избежать проблемы несоответствия кодировок, из-за которой иногда не удается прочитать русский текст.
Текстовый документ, хранящийся в памяти компьютера, состоит не только из кодов символьного алфавита. В нем также содержатся коды, управляющие форматами текста при его отображении на мониторе или на печати: тип и размер шрифта, положение строк, поля и отступы и пр. Кроме того, текстовые процессоры (например, Microsoft Word) позволяют включать в документ и редактировать такие «нелинейные» объекты, как таблицы, оглавления, ссылки и гиперссылки, историю вносимых изменений и т. д. Всё это также представляется в виде последовательности байтовых кодов.
Задание 8
Используя метод сжатия Хаффмена, закодируйте следующие слова:
а) administrator
б) revolution
в) economy
г) department
Используя дерево Хаффмена, декодируйте следующие слова:
а) 01110011 11001001 10010110 10010111 100000
б) 00010110 01010110 10011001 01101101 01000100 000











