Биты, байты, кодировки
Почти полтора месяца писала данную статью, но надеюсь оно того стоило. Данная статья может выглядеть холиварной, поэтому не спешите писать комментарии пока не прочитаете полностью. Статья главным образом о методологии.
Дело в том, что я твёрдо уверена, что в учебных заведениях по информационной специальности, школьникам и студентам забивают голову историей древнего мира вместо актуальных знаний. Все методички преподают дамы бальзаковского возраста, а пишут эти методички профессора возраста Карла Маркса. В результате от соискателей на работу, и от стажёров, я слышала такие забавные заблуждения, относительно фундаментальных основ, как:
- в байте 1024 бита
- в байте 8 бит потому что 8 — степень двойки
- бит принимает всякие разные значения от 0 до 1
В числе прочих забавных случаев: для выбора десяти случайных чисел из бд, соискатели десять раз делают запрос; для открытия файла на чтение используют в PHP флаг ‘a+’; не умеют работать со строками, кодировками и указателями. Написать функцию, которая возвращает строку задом наперёд, не используя переменную-буфер — вообще непосильная задача.
В этой статье, я хочу коснуться проблемы заблуждений с битами и байтами, и написать свою методику обучения этим фундаментальным знаниям.
Итак… сперва я хочу написать определения из википедии методичек, которые являются догмой в умах профессоров из мин.образования.
- Бит — это двоичный логарифм вероятности равновероятных событий или сумма произведений вероятности на двоичный логарифм вероятности при равновероятных событиях; (или другими словами) бит — это единица информации, равная результату эксперимента, имеющему два исхода
- Бит — минимальная единица информации.
- Байт — минимальная адресуемая единица информации.
Из-за этих определений, в умах будущих программистов ЭВМ, больше каши, чем из-за каких-либо других определений! Они совершенно истинны, но совершенно бесполезны для обучения. Я превращаюсь в Халка, когда слышу их.
Таблица кодирования ASCII.
А теперь «заглянем» в память компьютера и разберемся, как же представлена в нем текстовая информация.
Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и других. Мы уже говорили, что множество всех символов, с помощью которых записывается текст, называется алфавитом, а число символов в алфавите — его мощностью.
Для представления текстовой информации в компьютере используется алфавит мощностью 256 символов. Мы знаем, что один символ такого алфавита несет 8 битов информации: 2 в 8 степени равно 256. 8 битов = 1 байт, следовательно:
Один символ в компьютерном тексте занимает 1 байт памяти.
Как мы выяснили, традиционно для кодирования одного символа используется 8 бит. И, когда люди определились с количеством бит, им осталось договориться о том, каким кодом кодировать тот или иной символ, чтобы не получилось путаницы, т.е. необходимо было выработать стандарт – все коды символов сохранить в специальной таблице кодов. В первые годы развития вычислительной техники таких стандартов не существовало, а сейчас наоборот, их стало очень много, но они противоречивы. Первыми решили эти проблемы в США, в институте стандартизации. Этот институт ввел в действие таблицу кодов ASCII (AmericanStandardCodeforInformationInterchange – стандартный код информационного обмена США).
Рассмотрим таблицу кодов ASCII.
Пояснение: раздать учащимся распечатанную таблицу кодов ASCII.
Таблица ASCII разделена на две части. Первая – стандартная – содержит коды от 0 до 127. Вторая – расширенная – содержит символы с кодами от 128 до 255.
Первые 32 кода отданы производителям аппаратных средств и называются они управляющие, т.к. эти коды управляют выводом данных. Им не соответствуют никакие символы.
Коды с 32 по 127 соответствуют символам английского алфавита, знакам препинания, цифрам, арифметическим действиям и некоторым вспомогательным символам.
Коды расширенной части таблицы ASCII отданы под символы национальных алфавитов, символы псевдографики и научные символы.
Стандартная часть таблицы кодов ASCII
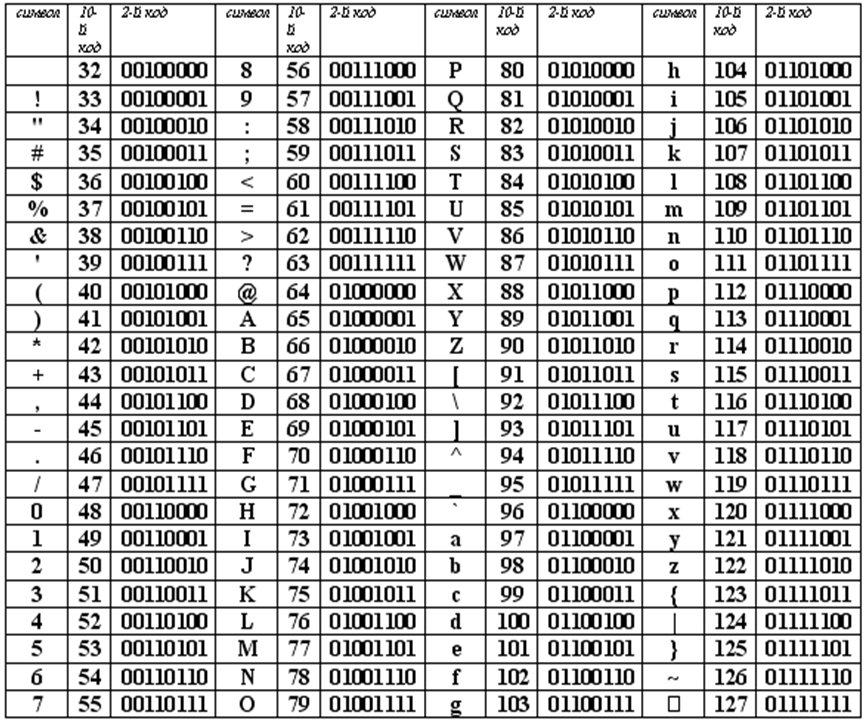
Если вы внимательно посмотрите на обе части таблицы, то увидите, что все буквы расположены в них по алфавиту, а цифры – по возрастанию. Этот принцип последовательного кодирования позволяет определить код символа, не заглядывая в таблицу.
Коды цифр берутся из этой таблицы только при вводе и выводе и если они используются в тексте. Если же они участвуют в вычислениях, то переводятся в двоичную систему счисления.
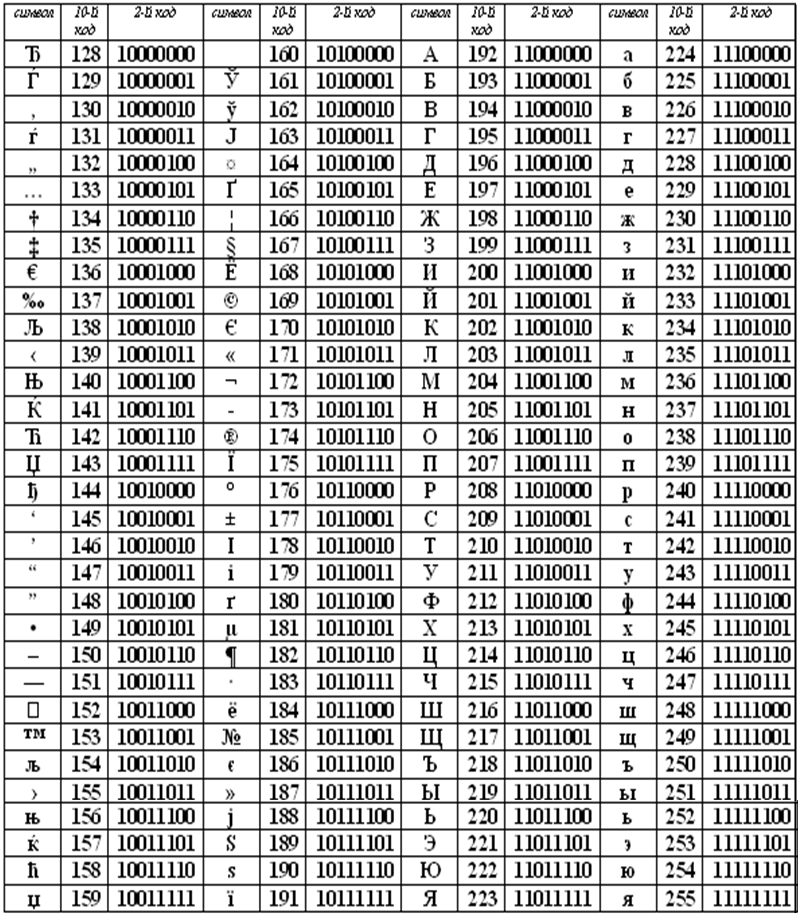
Коды национального (русского) алфавита расширенной частитаблицы ASCII
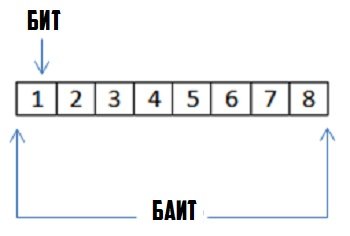
Сколько битов в Байте
Как Вы уже поняли выше, сам по себе, бит — это самая маленькая единица в системе измерения информации. Оттого и пользоваться ею совсем неудобно. В итоге, в 1956 году Владимир Бухгольц ввёл ещё одну единицу измерения — Байт, как пучок из 8 бит. Вот наглядный пример байта в двоичной системе:
Таким образом, вот эти 8 бит и есть Байт. Он представляет собой комбинацию из 8 цифр, каждая из которых может быть либо единицей, либо нулем. Всего получается 256 комбинаций. Вот как то так.
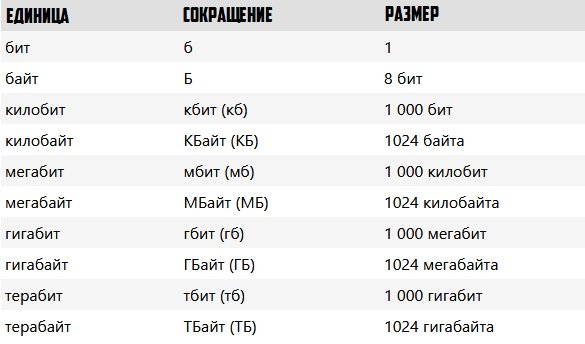
Килобайт, Мегабайт, Гигабайт
Со временем, объёмы информации росли, причём в последние годы в геометрической прогрессии. Поэтому, решено было использовать приставки метрической системы СИ: Кило, Мега, Гига, Тера и т.п.
Приставка «кило» означает 1000, приставка «мега» подразумевает миллион, «гига» — миллиард и т.д. При этом нельзя проводить аналогии между обычным килобитом и килобайтом. Дело в том, что килобайт — это отнюдь не тысяча байт, а 2 в 10-й степени, то есть 1024 байт.
Соответственно, мегабайт — это 1024 килобайт или 1048576 байт.
Гигабайт получается равен 1024 мегабайт или 1048576 килобайт или 1073741824 байт.
Для простоты можно использовать такую таблицу:
Для примера хочу привести вот такие цифры:
Стандартный лист А4 с печатным текстом занимает в средем около 100 килобайт
Обычная фотография на простой цифровой фотоаппарат — 5-8 мегабайт
Фотографии, сделанные на профессиональный фотоаппарат — 12-18 мегабайт
Музыкальный трек формата mp3 среднего качества на 5 минут — около 10 мегабайт.
Обычный фильм на 90 минут, сжатый в обычном качестве — 1,5-2 гигабайта
Тот же фильм в HD-качестве — от 20 до 40 гигабайт.
P.S.:
Теперь отвечу на вопросы, которые мне наиболее часто задают новички.
1. Сколько Килобит в Мегабите? Ответ — 1000 килобит (по системе СИ)
2. Сколько Килобайт в Мегабайте? Ответ — 1024 Килобайта
3. Сколько Килобит в Мегабайте? Ответ — 8192 килобита
4. Сколько Килобайт в Гигабайте? Ответ — 1 048 576 Килобайт.
В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобретя в каталоге.



Информационный объём мультимедийной информации
Гораздо больше информации включают в себя файлы графических изображений, а ещё больше — видеофайлы.
Мультимедийной информацией называют данные, которые содержат рисунки, фотографии, звук и видео.

К примеру, растровый рисунок, состоит из 1000 на 1000 пикселей.
Каждый пиксель может быть закодирован 24 битами или 3 байтами (так как 24/8=3) и занимает информационный объём равный 1000⋅1000⋅3=3 000 000 байт.
В килобайтах это уже будет 3 000 000 байт/1024= 2929,69 Кбайт. А в мегабайтах — 2929,69 Кбайт /1024=2,86 Мбайт.
В связи с этим, промышленность выпускает большие по объему носители цифровых данных.
Объём современных цифровых носителей (жёстких или твердотельных дисков), уже достигает объёма нескольких терабайт.
© 2013-2020 Информатика. Полезные материалы по информационным технологиям. Использование материалов без активной ссылки на сайт запрещено! Публикация в печати только с письменного разрешения администрации.
Кодирование текстовой информации и компьютеры
Если смотреть на текст глазами компьютера, то в тексте нет предложений, абзацев, заголовков и т. д., потому что весь текст просто состоит из отдельных символов. Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
Мы вводим текст в компьютер при помощи клавиатуры, символы которой мы прекрасно понимаем. Нажимая на какую-то букву, мы отправляем в оперативную память компьютера двоичное представление нажатых клавиш. Каждый отдельный символ будет представлен 8-битной кодировкой. Например буква «А» — это «11000000». Получается, что один символ — это 1 байт или 8 бит. При такой кодировке, путем нехитрых подсчетов можно посчитать, что мы можем зашифровать 256 символов. Для кодирования текстовой информации данного количества символов более чем предостаточно.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.

Текстовая информация
Принципиально важно, что текстовая информация уже дискретна — состоит из отдельных знаков. Поэтому возникает лишь технический вопрос — как разместить ее в памяти компьютера.
Напомним о байтовом принципе организации памяти компьютеров, обсуждавшемся в курсе информатики основной школы. Вернемся к рис. 1.5. Каждая клеточка на нем обозначает бит памяти. Восемь подряд расположенных битов образуют байт памяти. Байты пронумерованы. Порядковый номер байта определяет его адрес в памяти компьютера. Именно по адресам процессор обращается к данным, читая или записывая их в память (рис. 1.10).

Рис. 1.10. Байтовая организация памяти
Модель представления текста в памяти весьма проста. За каждой буквой алфавита, цифрой, знаком препинания и иным общепринятым при записи текста символом закрепляется определенный двоичный код, длина которого фиксирована. В популярных системах кодировки (Windows-1251, КОI8 и др.) каждый символ заменяется на 8-разрядное целое положительное двоичное число; оно хранится в одном байте памяти. Это число является порядковым номером символа в кодовой таблице. Согласно главной формуле информатики, определяем, что размер алфавита, который можно закодировать, равен: 2 8 = 256. Этого количества вполне достаточно для размещения двух алфавитов естественных языков (английского и русского) и всех необходимых дополнительных символов.
Поскольку в мире много языков и много алфавитов, постепенно совершается переход на международную систему кодировки Unicode, в которой используются многобайтовые коды. Например, если код символа занимает 2 байта, то с его помощью можно закодировать 2 16 = 65 536 различных символов.
При работе с электронной почтой почтовая программа иногда нас спрашивает, не хотим ли мы прибегнуть к кодировке Unicode для пересылаемых сообщений. Таким способом можно избежать проблемы несоответствия кодировок, из-за которой иногда не удается прочитать русский текст.
Текстовый документ, хранящийся в памяти компьютера, состоит не только из кодов символьного алфавита. В нем также содержатся коды, управляющие форматами текста при его отображении на мониторе или на печати: тип и размер шрифта, положение строк, поля и отступы и пр. Кроме того, текстовые процессоры (например, Microsoft Word) позволяют включать в документ и редактировать такие «нелинейные» объекты, как таблицы, оглавления, ссылки и гиперссылки, историю вносимых изменений и т. д. Всё это также представляется в виде последовательности байтовых кодов.
Кодирование текстовой информации и таблицы кодировок
Таблица кодировки — это место, где прописано какому символу какой код относится. Все таблицы кодировки являются согласованными — это нужно, чтобы не возникало путаницы между документами, закодированными по одной таблице, но на разных устройствах.
На сегодняшний день существует множество таблиц кодировок. Из-за этого часто возникают проблемы с переносом текстовых документов между устройствами. Так получается, что если текстовая информация была закодирована по одной какой-то таблице, то и раскодирована она может быть только по этой таблице. Если попытаться раскодировать другой таблицей, то в результате получим только набор непонятных символов, но никак не читабельный текст.
Наиболее популярные таблицы кодировки:
- ASCII,
- MS-DOS,
- ISO,
- Windows,
- КОИ8,
- CP866,
- Mac,
- CP 1251,
- Unicode,
- и др.











