Перевод текста в цифровой код.
Давайте разберемся как же все таки переводить тексты в цифровой код? Кстати, на нашем сайте вы можете перевести любой текст в десятичный, шестнадцатеричный, двоичный код воспользовавшись Калькулятором кодов онлайн.
По теории ЭВМ любой текст состоит из отдельных символов. К этим символам относятся: буквы, цифры, строчные знаки препинания, специальные символы ( «»,№, (), и т.д.), к ним, так же, относятся пробелы между словами.
Необходимый багаж знаний. Множество символов, при помощи которых записываю текст, называется АЛФАВИТОМ.
Число взятых в алфавите символов, представляет его мощность.
Количество информации можно определить по формуле : N = 2b
- N – та самая мощность ( множество символов),
- b – Бит ( вес взятого символа).
Алфавит, в котором будет 256 может вместить в себя практически все нужные символы. Такие алфавиты называют ДОСТАТОЧНЫМИ.
Если взять алфавит мощностью 256, и иметь в виду что 256 = 28
- 8 бит всегда называют 1 байт:
- 1 байт = 8 бит.
Если перевести каждый символ в двоичный код, то этот код компьютерного текста будет занимать 1 байт.
Таблица кодирования ASCII.
А теперь «заглянем» в память компьютера и разберемся, как же представлена в нем текстовая информация.
Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и других. Мы уже говорили, что множество всех символов, с помощью которых записывается текст, называется алфавитом, а число символов в алфавите — его мощностью.
Для представления текстовой информации в компьютере используется алфавит мощностью 256 символов. Мы знаем, что один символ такого алфавита несет 8 битов информации: 2 в 8 степени равно 256. 8 битов = 1 байт, следовательно:
Один символ в компьютерном тексте занимает 1 байт памяти.
Как мы выяснили, традиционно для кодирования одного символа используется 8 бит. И, когда люди определились с количеством бит, им осталось договориться о том, каким кодом кодировать тот или иной символ, чтобы не получилось путаницы, т.е. необходимо было выработать стандарт – все коды символов сохранить в специальной таблице кодов. В первые годы развития вычислительной техники таких стандартов не существовало, а сейчас наоборот, их стало очень много, но они противоречивы. Первыми решили эти проблемы в США, в институте стандартизации. Этот институт ввел в действие таблицу кодов ASCII (AmericanStandardCodeforInformationInterchange – стандартный код информационного обмена США).
Рассмотрим таблицу кодов ASCII.
Пояснение: раздать учащимся распечатанную таблицу кодов ASCII.
Таблица ASCII разделена на две части. Первая – стандартная – содержит коды от 0 до 127. Вторая – расширенная – содержит символы с кодами от 128 до 255.
Первые 32 кода отданы производителям аппаратных средств и называются они управляющие, т.к. эти коды управляют выводом данных. Им не соответствуют никакие символы.
Коды с 32 по 127 соответствуют символам английского алфавита, знакам препинания, цифрам, арифметическим действиям и некоторым вспомогательным символам.
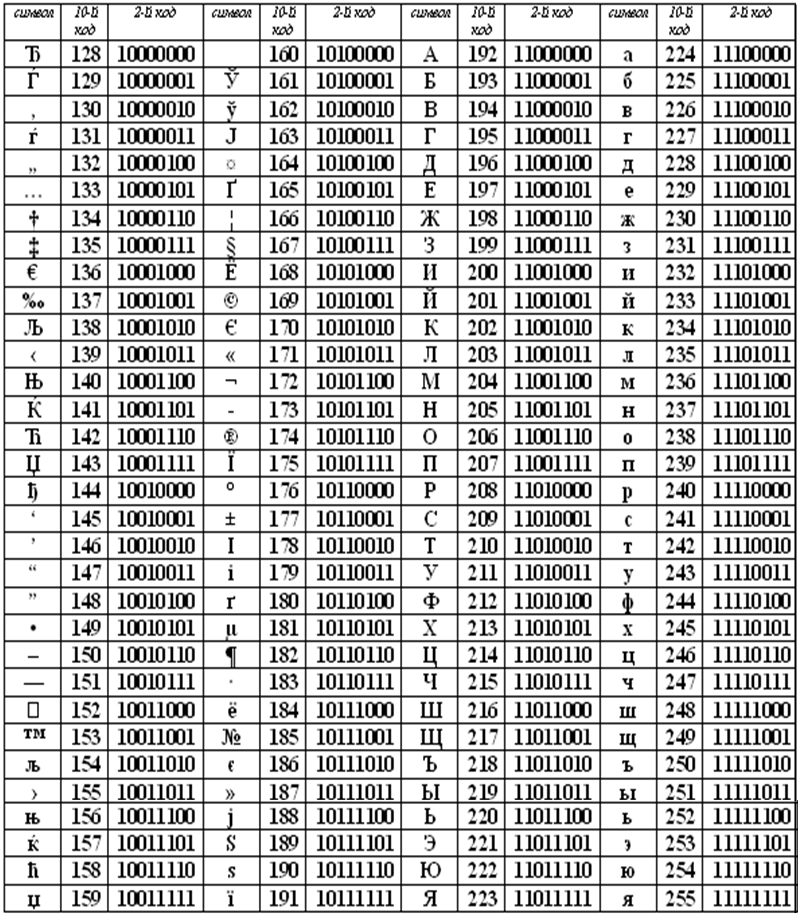
Коды расширенной части таблицы ASCII отданы под символы национальных алфавитов, символы псевдографики и научные символы.
Стандартная часть таблицы кодов ASCII
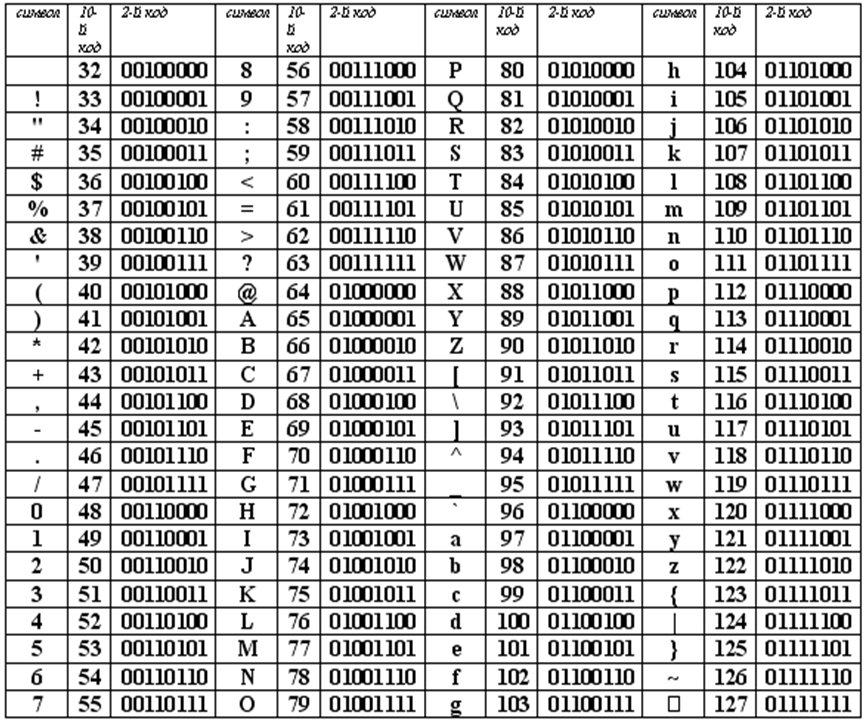
Если вы внимательно посмотрите на обе части таблицы, то увидите, что все буквы расположены в них по алфавиту, а цифры – по возрастанию. Этот принцип последовательного кодирования позволяет определить код символа, не заглядывая в таблицу.
Коды цифр берутся из этой таблицы только при вводе и выводе и если они используются в тексте. Если же они участвуют в вычислениях, то переводятся в двоичную систему счисления.
Коды национального (русского) алфавита расширенной частитаблицы ASCII
Какая бывает информация?

Итак, для восприятия информации компьютеру необходимо запустить процессы обработки. А какая вообще бывает информация? Темой этой статьи является кодирование текстовой информации. Мы уделим особенное внимание этой задаче, но разберемся и с другими микротемами.
Информация может быть текстовой, числовой, звуковой, графической. Компьютер должен запустить процессы, обеспечивающие кодирование текстовой информации, чтобы вывести на экран то, что мы, например, печатаем на клавиатуре. Мы будем видеть символы и буквы, это понятно. А что же видит машина? Она воспринимает абсолютно всю информацию – и речь сейчас идет не только о тексте – в качестве определенной последовательности нулей и единиц. Они составляют основу так называемого двоичного кода. Соответственно, процесс, который преобразует поступающую на устройство информацию в понятную ему, имеет название “двоичное кодирование текстовой информации”.
Стандарты кодирования звука
Звуки, которые слышит человек, представляют собой колебания воздуха. Звуковые колебания – это процесс распространения волн.
Звук имеет две основные характеристики:
- амплитуда колебаний – определяет громкость звука;
- частота колебания — определяет тональность звука.
Звук можно преобразовать в электрический сигнал, с помощью микрофона. Звук кодируется с определенным, заранее заданным интервалом времени. В этом случае измеряется размер электрического сигнала и присваивается бинарная величина. Чем чаще делают данные измерения, тем выше качество звука.

Компакт-диск объемом 700 Мб, вмещает порядка 80 минут звука CD-качества.
Кодирование текстовой информации и компьютеры
Если смотреть на текст глазами компьютера, то в тексте нет предложений, абзацев, заголовков и т. д., потому что весь текст просто состоит из отдельных символов. Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
Мы вводим текст в компьютер при помощи клавиатуры, символы которой мы прекрасно понимаем. Нажимая на какую-то букву, мы отправляем в оперативную память компьютера двоичное представление нажатых клавиш. Каждый отдельный символ будет представлен 8-битной кодировкой. Например буква «А» — это «11000000». Получается, что один символ — это 1 байт или 8 бит. При такой кодировке, путем нехитрых подсчетов можно посчитать, что мы можем зашифровать 256 символов. Для кодирования текстовой информации данного количества символов более чем предостаточно.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.

Предпосылки появления кодировок
Исторически компьютер создавался как машина для ускорения и автоматизации вычислений. Само слово computer с английского можно перевести как вычислитель, а в 20 веке в СССР, до распространения термина компьютер, использовалась аббревиатура ЭВМ — электронно вычислительная машина.
Всё, чем компьютеры оперировали — числа. Основным заказчиком и драйвером появления первых моделей были оборонные предприятия. На компьютерах проводили расчёты параметров полёта баллистических ракет, самолётов, спутников. В 1950-е годы вычислительные мощности компьютеров стали использовать для:
- прогноза погоды;
- вычислений экспериментальной и теоретической физики;
- расчета заработной платы сотрудников (например, компьютер LEO применялся для нужд компании, владеющей сетью чайных магазинов);
- прогнозирование результатов выборов президента США (1952 год, компьютер UNIVAC).
Компьютеры и числа
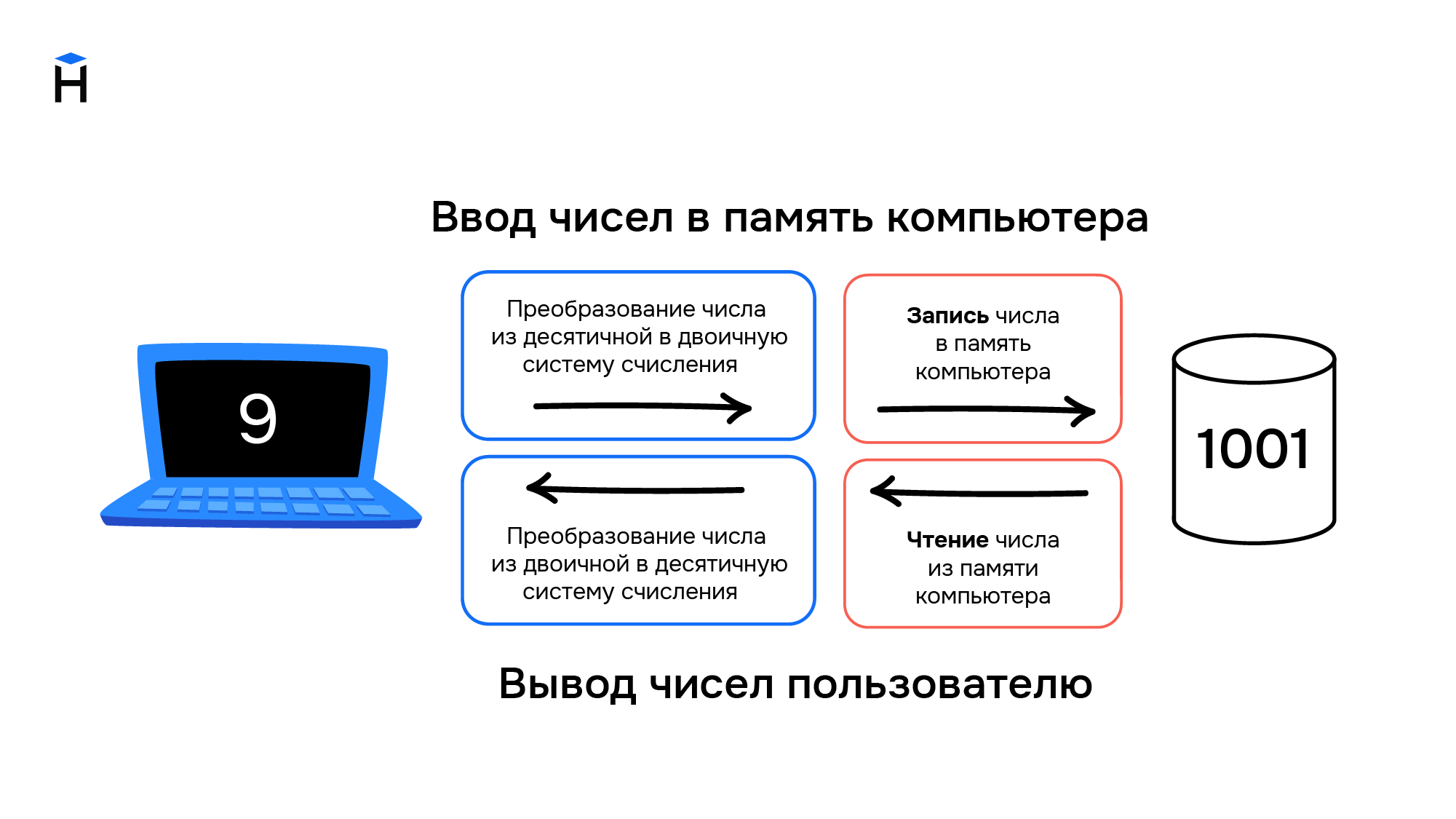
Цели, для которых разрабатывались компьютеры, привели к появлению архитектуры, предназначенной для работы с числами. Они хранятся в компьютере следующим образом:
- Число из десятичной системы счисления переводится в двоичную, т.е. набор нулей и единиц. Например, 3 в двоичной системе счисления можно записать в виде 11, а 9 как 1001. Подробнее о системах счисления читайте в соответствующем гайде.
- Полученный набор нулей и единиц хранится в ячейках памяти компьютера. Например, наличие тока на элементе памяти означает единицу, его отсутствие — ноль.
В конце 1950-х годов происходит замена ламп накаливания на полупроводниковые элементы (транзисторы и диоды). Внедрение новой технологии позволило уменьшить размеры компьютеров, увеличить скорость работы и надёжность вычислений, а также повлияло на конечную стоимость. Если первые компьютеры были дорогостоящими штучными проектами, которые могли себе позволить только государства или крупные компании, то с применением полупроводников начали появляться серийные компьютеры, пусть даже и не персональные.
Компьютеры и символы
Постепенно компьютеры начинают применяться для решения не только вычислительных или математических задач. Возникает необходимость обработки текстовой информации, но с буквами и другими символами ситуация обстоит сложнее, чем с числами. Символы — это визуальный объект. Даже одна и та же буква «а» может быть представлена двумя различными символами «а» и «А» в зависимости от регистра.
Также число «один» можно представить в виде различных символов. Это может быть арабская цифра 1 или римская цифра I. Значение числа не меняется, но символы используются разные.
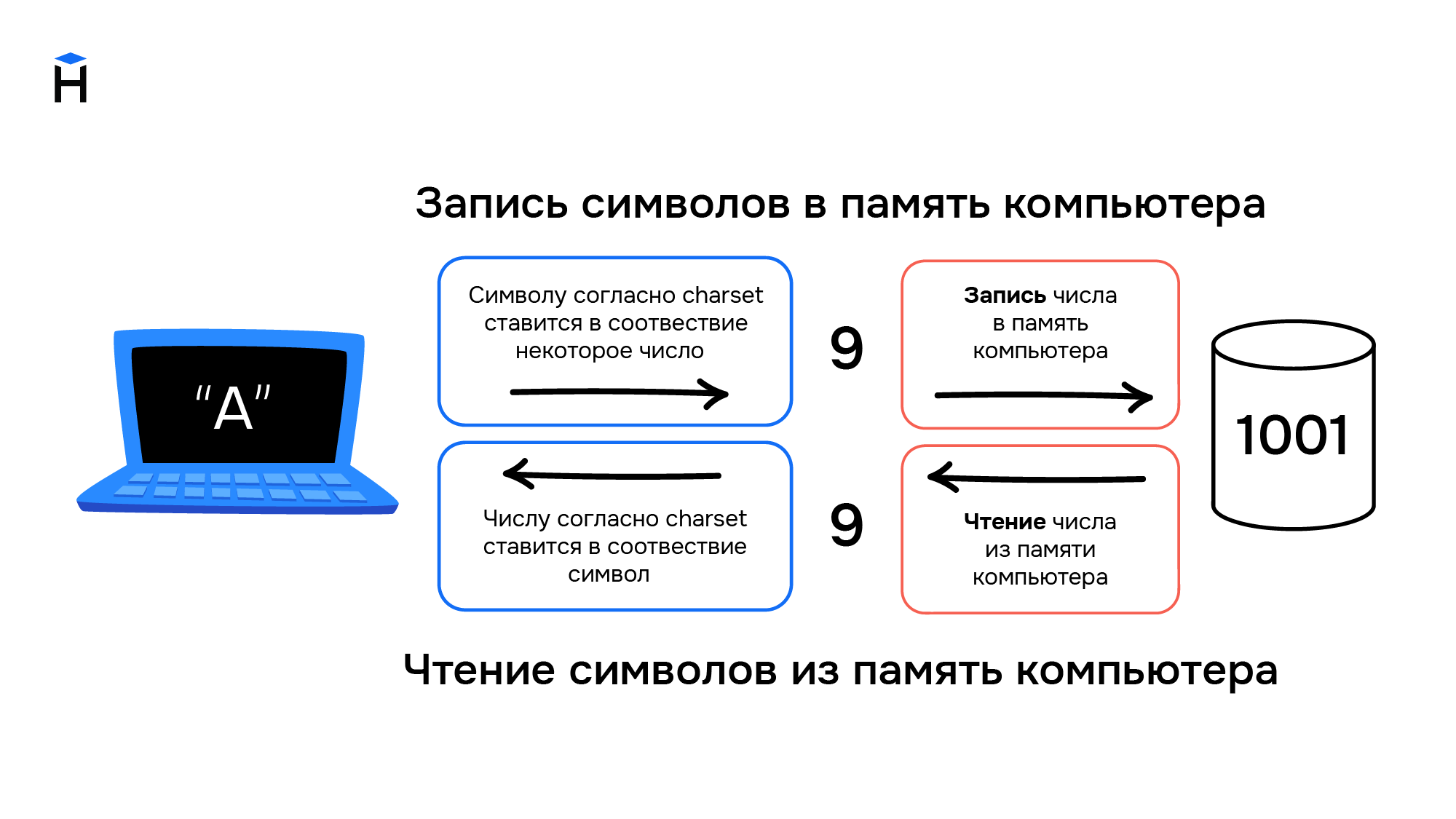
Компьютеры создавались для работы с числами, они не могут хранить символы. При вводе информации в компьютер символы преобразуются в числа и хранятся в памяти компьютера как обычные числа, а при выводе информации происходит обратное преобразование из чисел в символы.
Правила преобразования символов и чисел хранились в виде таблицы символов (англ. charset). В соответствии с такой таблицей для каждого компьютера конструировали и своё уникальное устройство ввода/вывода информации (например, клавиатура и принтер).
Распространение компьютеров
В начале 1960-х годов компьютеры были несовместимы друг с другом даже в рамках одной компании-производителя. Например, в компании IBM насчитывалось около 20 конструкторских бюро, и каждое разрабатывало свою собственную модель. Такие компьютеры не были универсальными, они создавались для решения конкретных задач. Для каждой решаемой задачи формировалась необходимая таблица символов, и проектировались устройства ввода/вывода информации.
В этот период начинают формироваться сети, соединяющие в себе несколько компьютеров. Так, в 1958 году создали систему SAGE (Semi-Automatic Ground Environment), объединившую радарные станций США и Канады в первую крупномасштабную компьютерную сеть. При этом, чтобы результаты вычислений одних компьютеров можно было использовать на других компьютерах сети, они должны были обладать одинаковыми таблицами символов.
В 1962 году компания IBM формирует два главных принципа для развития собственной линейки компьютеров:
- Компьютеры должны стать универсальными. Это означало переход от производства узкоспециализированных компьютеров к машинам, которые могут решать разные задачи.
- Компьютеры должны стать совместимыми друг с другом, то есть должна быть возможность использовать данные с одного компьютера на другом.
Так в 1965 году появились компьютеры IBM System/360. Это была линейка из шести моделей, состоящих из совместимых модулей. Модели различались по производительности и стоимости, что позволило заказчикам гибко подходить к выбору компьютера. Модульность систем привела к появлению новой отрасли — производству совместимых с System/360 вычислительных модулей. У компаний не было необходимости производить компьютер целиком, они могли выходить на рынок с отдельными совместимыми модулями. Всё это привело к ещё большему распространению компьютеров.
14.1. Кодировка ASCII и её расширения
Основой для компьютерных стандартов кодирования символов послужил код ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в 1960-х годах в США и применявшийся для любых, в том числе и некомпьютерных, способов передачи информации (телеграф, факсимильная связь и т. д.). Этот код 7-битовый: общее количество символов составляет 2 7 = 128, из них первые 32 символа — управляющие, а остальные — изображаемые, т. е. имеющие графическое изображение. К изображаемым символам в ASCII относятся буквы латинского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Кодировка ASCII приведена в табл. 3.8.
Таблица 3.8
Кодировка ASCII

Хотя для кодирования символов в ASCII достаточно 7 битов, в памяти компьютера под каждый символ отводится ровно 1 байт (8 битов), при этом код символа помещается в младшие биты, а в старший бит заносится 0.
Например, 01000001 — код прописной латинской буквы «А»; с помощью шестнадцатеричных цифр его можно записать как 41.
Стандарт ASCII рассчитан на передачу только английского текста. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII -кодировки, в которых применялись однобайтовые коды символов. При этом первые 128 символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со 128-го по 255-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано несколько вариантов кодовых таблиц (например, для русского языка их было создано около десятка!).
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Для русского языка наиболее распространёнными стали однобайтовые кодовые таблицы CP-866, Windows-1251 (табл. 3.9) и КОИ-8 (табл. 3.10). В них первые 128 символов совпадают с ASCII-кодировкой, а русские буквы размещены во второй части таблицы. Обратите внимание на то, что коды русских букв в этих кодировках различны.
Таблица 3.9
Кодировка Windows-1251

Таблица 3.10
Кодировка КОИ-8

Мы выяснили, что при нажатии на алфавитно-цифровую клавишу в компьютер посылается некоторая цепочка нулей и единиц. В текстовых файлах хранятся не изображения символов, а их коды.
При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст, причём изображения эти могут быть разнообразны и достаточно причудливы. Внешний вид выводимых на экран символов кодируется и хранится в специальных шрифтовых файлах. Современные текстовые процессоры умеют внедрять шрифты в файл. В этом случае файл содержит не только коды символов, но и описание используемых в этом документе шрифтов. Кроме того, файлы, создаваемые с помощью текстовых процессоров, включают в себя и такие данные о форматировании текста, как его размер, начертание, размеры полей, отступов, межстрочных интервалов и другую дополнительную информацию.
Несколько советов программистам
Допустим, программист решил реализовать текстовый редактор, поддерживающий алфавит языка Бопомофо. Символы данного языка располагаются в таблице Юникод в диапазоне 12549-12589 и, следовательно, программисту необходимо выбрать стандарт UTF-16 для кодирования. Предположим, что для ввода символов решено использовать программную клавиатуру, состоящую из кнопок, каждая из которых соответствует букве алфавита языка. Кнопки – объекты класса button. Нажатие пользователем на какую-либо из кнопок порождает событие, в результате которого приложению становится известен номер ячейки таблицы Юникод. Программисту рекомендуется:
1.Хранить в памяти приложения символы таблицы Юникод и номера ячеек, соответствующие только языкам, поддержка которых планируется в текстовом редакторе. Это уменьшит объем памяти, занимаемой приложением, а также повысит скорость его работы, сузив область поиска номера ячейки.
2. При реализации приложения заранее выполнить преобразование всех номеров ячеек в их бинарные коды. Результат преобразования сохранить в файле, в формализованном виде. При загрузке приложения выполнить считывание в память номеров ячеек и их бинарных кодов UTF-16. Это позволит снизить вычислительную нагрузку приложения в ходе его работы.
3. Для хранения номеров ячеек и их бинарных кодов использовать объект класса, позволяющего осуществить это в виде ключ-значение, где ключ – номер ячейки, а значение – бинарный код. Классы, реализующие в языках программирования данный функционал, организуют работу таким образом, чтобы минимизировать время поиска ключа, используя сортировку ключей или хеширование.
Отметим проблему кодирования составных символов, которая является важным техническим аспектом. Например, символ ü может быть интерпретирован, как самостоятельный символ, которому соответствует номер ячейки 252 или может быть скомпонован из двух символов: u, которому соответствует номер ячейки 117 и символа ¨, которому соответствует номер ячейки 776. Программист должен строго придерживаться одного из вариантов представления таких символов иначе побайтовое сравнение строк будет невозможно. Рекомендуется использование второго варианта, который может облегчить поиск составных символов в тексте. Например, если пользователь осуществляет поиск символа u, то ему может быть выведен в качестве результата, как составной символ ü, так и самостоятельный u.











