Сколько места в памяти компьютера занимает код одного символа
Вы не увидите простой ответ, потому что его нет.
Во-первых, Unicode не содержит «каждого символа с каждого языка», хотя он действительно пытается.
Юникод сам по себе является отображением, он определяет кодовые точки, а кодовой точкой является число, связанное обычно с символом. Обычно я говорю, потому что есть такие понятия, как объединение символов. Вы можете быть знакомы с такими вещами, как акценты или умлауты. Они могут использоваться с другим символом, например или для создания нового логического символа. Следовательно, персонаж может состоять из 1 или более кодовых точек.
Чтобы быть полезными в вычислительных системах, нам нужно выбрать представление для этой информации. Это различные кодировки unicode, такие как utf-8, utf-16le, utf-32 и т. Д. Они в значительной степени отличаются размером их кодовых элементов. UTF-32 — это простейшая кодировка, у нее есть код, 32 бита, что означает, что отдельный кодовый адрес удобно помещается в кодовую часть. Другие кодировки будут иметь ситуации, когда для кодовой точки потребуется несколько кодовых элементов, или что конкретный код не может быть вообще представлен в кодировке (это проблема, например, с UCS-2).
Из-за гибкости объединения символов даже в пределах данной кодировки количество байтов на символ может варьироваться в зависимости от характера и формы нормализации. Это протокол для работы с символами, которые имеют более одного представления (вы можете сказать который является 2 кодовыми точками, один из которых представляет собой комбинированный символ или который является одним кодовым ).
Проще говоря, — это стандарт, который присваивает один номер (называемый кодовой точкой) всем персонажам мира (его работа продолжается).
Теперь вам нужно представить эти кодовые точки, используя байты, которые называются . — это способы представления этих символов.
— многобайтовая кодировка символов. Символы могут иметь от 1 до 6 байтов (некоторые из них могут не потребоваться прямо сейчас).
каждый символ имеет 4 байта символов.
использует 16 бит для каждого символа и представляет только часть символов Юникода под названием BMP (для всех практических целей это достаточно). Java использует эту кодировку в своих строках.
В Unicode ответ нелегко дать. Проблема, как вы уже указывали, — это кодировки.
Учитывая любое английское предложение без диакритических символов, ответ для UTF-8 будет таким же количеством байтов, что и символы, а для UTF-16 это будет число символов раз два.
Единственная кодировка, где (на данный момент) мы можем сделать утверждение о размере UTF-32. Там он всегда 32 бит на персонажа, хотя я думаю, что кодовые точки подготовлены для будущего UTF-64
Что делает его настолько трудным, по крайней мере, две вещи:
- состоящие из символов, где вместо использования символьной сущности, которая уже подчеркнута / диакритическая (À), пользователь решил объединить акцент и базовый символ (`A).
- кодовые точки. Кодовые точки — это метод, с помощью которого кодировки UTF позволяют кодировать больше, чем количество бит, которое дает им свое имя, как правило, позволяют. Например, UTF-8 обозначает определенные байты, которые сами по себе недействительны, но если следовать за допустимым байтом продолжения, это позволит описать символ за пределами 8-битного диапазона 0..255. См. Examples и Overlong Encodings ниже в статье Википедии о UTF-8.
- Отличный пример что символ € (кодовая точка может быть представлен либо как трехбайтная последовательность либо четырехбайтная последовательность .
- Оба действительны, и это показывает, насколько сложным является ответ, говоря о «Юникоде», а не о конкретной кодировке Unicode, такой как UTF-8 или UTF-16.
Существует отличный инструмент для вычисления байтов любой строки в UTF-8: http://mothereff.in/byte-counter
Обновление: @mathias сделал код общедоступным: https://github.com/mathiasbynens/mothereff.in/blob/master/byte-counter/eff.js
Для UTF-16 персонаж нуждается в четырех байтах (два блока кода), если он начинается с 0xD800 или выше; такой символ называется «суррогатной парой». Более конкретно, суррогатная пара имеет форму:
где […] указывает двухбайтовый блок кода с заданным диапазоном. Anything = 0xE000 недействительно (кроме маркеров спецификации, возможно).
См. http://unicodebook.readthedocs.io/unicode_encodings.html , раздел 7.5.
Теоретически давно существует решение этих проблем. Оно называется Unicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодировано N=2 16 =65 536 символов.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Для символов кириллицы в Юникоде выделено два диапазона кодов:
Cyrillic (#0400 — #04FF)
Cyrillic Supplement (#0500 — #052F).
Но внедрение таблицы Unicode в чистом виде сдерживается по той причине, что если код одного символа будет занимать не один байт, а два байта, что для хранения текста понадобится вдвое больше дискового пространства, а для его передачи по каналам связи – вдвое больше времени.
Поэтому сейчас на практике больше распространено представление Юникода UTF-8 (Unicode Transformation Format). UTF-8 обеспечивает наилучшую совместимость с системами, использующими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байтов. В целом, так как самые распространенные в мире символы – символы латинского алфавита — в UTF-8 по-прежнему занимают 1 байт, такое кодирование экономичнее, чем чистый Юникод.
Задачи
1. В кодируемом английском тексте используется только 26 букв латинского алфавита и еще 6 знаков пунктуации. В этом случае текст, содержащий 1000 символов можно гарантированно сжать без потерь информации до размера:
Словарь Эллочки – «людоедки» (персонаж романа «Двенадцать стульев») составляет 30 слов. Сколько бит достаточно, чтобы закодировать весь словарный запас Эллочки? Варианты: 8, 5, 3, 1.
4.4. Единицы измерения объема данных и ёмкости памяти: килобайты, мегабайты, гигабайты…
Итак, в мы выяснили, что в большинстве современных кодировок под хранение на электронных носителях информации одного символа текста отводится 1 байт. Т.е. в байтах измеряется объем (V), занимаемый данными при их хранении и передаче (файлы, сообщения).
Объем данных (V) – количество байт, которое требуется для их хранения в памяти электронного носителя информации.
Память носителей в свою очередь имеет ограниченную ёмкость, т.е. способность вместить в себе определенный объем. Ёмкость памяти электронных носителей информации, естественно, также измеряется в байтах.
Однако байт – мелкая единица измерения объема данных, более крупными являются килобайт, мегабайт, гигабайт, терабайт…
Следует запомнить, что приставки “кило”, “мега”, “гига”… не являются в данном случае десятичными. Так “кило” в слове “килобайт” не означает “тысяча”, т.е. не означает “10 3 ”. Бит – двоичная единица, и по этой причине в информатике удобно пользоваться единицами измерения кратными числу “2”, а не числу “10”.
1 байт = 2 3 =8 бит, 1 килобайт = 2 10 = 1024 байта. В двоичном виде 1 килобайт = &10000000000 байт.
Т.е. “кило” здесь обозначает ближайшее к тысяче число, являющееся при этом степенью числа 2, т.е. являющееся “круглым” числом в двоичной системе счисления.
| Именование | Обозначение | Значение в байтах | |
| килобайт | 1 Кb | 2 10 b | 1 024 b |
| мегабайт | 1 Mb | 2 10 Kb = 2 20 b | 1 048 576 b |
| гигабайт | 1 Gb | 2 10 Mb = 2 30 b | 1 073 741 824 b |
| терабайт | 1 Tb | 2 10 Gb = 2 40 b | 1 099 511 627 776 b |
В связи, с тем, что единицы измерения объема и ёмкости носителей информации кратны 2 и не кратны 10, большинство задач по этой теме проще решается тогда, когда фигурирующие в них значения представляются степенями числа 2. Рассмотрим пример подобной задачи и ее решение:
В текстовом файле хранится текст объемом в 400 страниц. Каждая страница содержит 3200 символов. Если используется кодировка KOI-8 (8 бит на один символ), то размер файла составит:
1) Определяем общее количество символов в текстовом файле. При этом мы представляем числа, кратные степени числа 2 в виде степени числа 2, т.е. вместо 4, записываем 2 2 и т.п. Для определения степени можно использовать Таблицу 7.
2) По условию задачи 1 символ занимает 8 бит, т.е. 1 байт => файл занимает 2 7 *10000 байт.
3) 1 килобайт = 2 10 байт => объем файла в килобайтах равен:
Задачи
1. Сколько бит в одном килобайте?
2. Чему равен 1 Мбайт?
3. Сколько бит в сообщении объемом четверть килобайта? Варианты: 250, 512, 2000, 2048.
4. Объем текстового файла 640 Kb. Файл содержит книгу, которая набрана в среднем по 32 строки на странице и по 64 символа в строке.
14.1. Кодировка ASCII и её расширения
Основой для компьютерных стандартов кодирования символов послужил код ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в 1960-х годах в США и применявшийся для любых, в том числе и некомпьютерных, способов передачи информации (телеграф, факсимильная связь и т. д.). Этот код 7-битовый: общее количество символов составляет 2 7 = 128, из них первые 32 символа — управляющие, а остальные — изображаемые, т. е. имеющие графическое изображение. К изображаемым символам в ASCII относятся буквы латинского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Кодировка ASCII приведена в табл. 3.8.
Таблица 3.8
Кодировка ASCII

Хотя для кодирования символов в ASCII достаточно 7 битов, в памяти компьютера под каждый символ отводится ровно 1 байт (8 битов), при этом код символа помещается в младшие биты, а в старший бит заносится 0.
Например, 01000001 — код прописной латинской буквы «А»; с помощью шестнадцатеричных цифр его можно записать как 41.
Стандарт ASCII рассчитан на передачу только английского текста. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII -кодировки, в которых применялись однобайтовые коды символов. При этом первые 128 символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со 128-го по 255-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано несколько вариантов кодовых таблиц (например, для русского языка их было создано около десятка!).
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Для русского языка наиболее распространёнными стали однобайтовые кодовые таблицы CP-866, Windows-1251 (табл. 3.9) и КОИ-8 (табл. 3.10). В них первые 128 символов совпадают с ASCII-кодировкой, а русские буквы размещены во второй части таблицы. Обратите внимание на то, что коды русских букв в этих кодировках различны.
Таблица 3.9
Кодировка Windows-1251

Таблица 3.10
Кодировка КОИ-8

Мы выяснили, что при нажатии на алфавитно-цифровую клавишу в компьютер посылается некоторая цепочка нулей и единиц. В текстовых файлах хранятся не изображения символов, а их коды.
При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст, причём изображения эти могут быть разнообразны и достаточно причудливы. Внешний вид выводимых на экран символов кодируется и хранится в специальных шрифтовых файлах. Современные текстовые процессоры умеют внедрять шрифты в файл. В этом случае файл содержит не только коды символов, но и описание используемых в этом документе шрифтов. Кроме того, файлы, создаваемые с помощью текстовых процессоров, включают в себя и такие данные о форматировании текста, как его размер, начертание, размеры полей, отступов, межстрочных интервалов и другую дополнительную информацию.
Что такое гипертекст
Наиболее существенное отличие компьютерного текста от бумажного вы почувствуете, если встретитесь с текстом, информация в котором организована по принципу гипертекста.

Гипертекст — это текст, организованный так, что его можно просматривать в последовательности смысловых связей между его отдельными фрагментами. Такие связи называются гиперсвязями (гиперссылками).
Чаще всего по принципу гипертекста организованы компьютерные справочники, энциклопедии, учебники. Такую «книгу» можно читать не только в обычном порядке, «листая страницы» на экране, но и перемещаясь по смысловым связям в произвольном порядке. Например, при изучении на уроке физики темы «Второй закон Ньютона» с помощью компьютерного учебника ученик прочитал определение закона «Сила равна произведению массы на ускорение». Ему захотелось вспомнить определение массы. Указав в тексте на слово «масса» (связанные понятия обычно выделяются цветом или подчеркиванием, а указывать на них удобно с помощью мыши), он быстро перейдет к разделу учебника, где рассказывается о массе тел. Прочитав определение «Масса — мера инертности тела», ученик может пожелать уточнить, что такое инертность. По гиперссылке он быстро выйдет на нужный раздел.
После такой экскурсии вглубь материала ученик может вернуться в исходную точку, щелкнув мышью на кнопке «Назад», так как система запоминает весь маршрут продвижения по гиперссылкам.
Юникод — появление универсальной кодировки текста (UTF 32, UTF 16 и UTF 8)
Эти тысячи символов языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных кодировках ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой кодировкой текста, вышедшей под эгидой консорциума Юникод, была кодировка UTF 32 . Цифра в названии кодировки UTF 32 означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного символа в новой универсальной кодировке UTF 32.
В результате чего один и то же файл с текстом, закодированный в расширенной кодировке ASCII и в кодировке UTF 32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью UTF 32 число символов равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество символов использовать в кодировке вовсе и не было необходимости, однако при использовании UTF 32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много и такое расточительство себе никто не мог позволить.
В результате развития универсальной кодировки Юникод появилась UTF 16 , которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. UTF 16 использует два байта для кодирования одного символа. Например, в операционной системе Windows вы можете пройти по пути Пуск — Программы — Стандартные — Служебные — Таблица символов.
В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберите в Дополнительных параметрах набор символов Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из этих символов вы сможете увидеть его двухбайтовый код в кодировке UTF 16, состоящий из четырех шестнадцатеричных цифр:
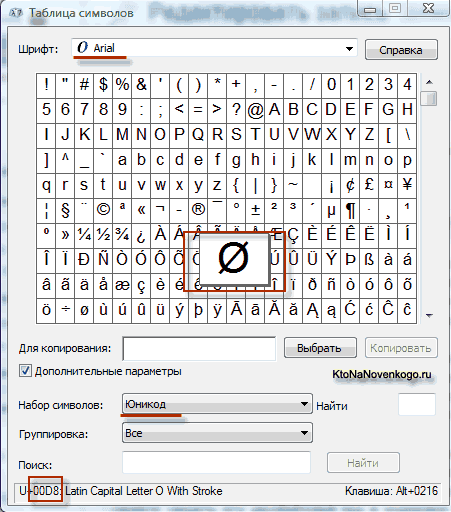
Сколько символов можно закодировать в UTF 16 с помощью 16 бит? 65 536 символов (два в степени шестнадцать) было принято за базовое пространство в Юникод. Помимо этого существуют способы закодировать с помощью UTF 16 около двух миллионов символов, но ограничились расширенным пространством в миллион символов текста.
Но даже удачная версия кодировки Юникод под названием UTF 16 не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них после перехода от расширенной версии кодировки ASCII к UTF 16 вес документов увеличивался в два раза (один байт на один символ в ASCII и два байта на тот же самый символ в кодировке UTF 16). Вот именно для удовлетворения всех и вся в консорциуме Юникод было решено придумать кодировку текста переменной длины .
Такую кодировку в Юникод назвали UTF 8 . Несмотря на восьмерку в названии UTF 8 является полноценной кодировкой переменной длины, т.е. каждый символ текста может быть закодирован в последовательность длинной от одного до шести байт. На практике же в UTF 8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить.
В UTF 8 все латинские символы кодируются в один байт, так же как и в старой кодировке ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в UTF 8. Т.е. базовая часть кодировки ASCII перешла в UTF 8.
Кириллические же символы в UTF 8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания кодировок UTF 16 и UTF 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. Производителям шрифтов остается только исходя из своих сил и возможностей заполнять это кодовое пространство векторными формами символов текста.
Теоретически давно существует решение этих проблем. Оно называетсяUnicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодированоN=2 16 =65 536 символов.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Для символов кириллицы в Юникоде выделено два диапазона кодов:
Cyrillic (#0400 — #04FF)
Cyrillic Supplement (#0500 — #052F).
Но внедрение таблицы Unicode в чистом виде сдерживается по той причине, что если код одного символа будет занимать не один байт, а два байта, что для хранения текста понадобится вдвое больше дискового пространства, а для его передачи по каналам связи – вдвое больше времени.
Поэтому сейчас на практике больше распространено представление Юникода UTF-8 (Unicode Transformation Format). UTF-8 обеспечивает наилучшую совместимость с системами, использующими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байтов. В целом, так как самые распространенные в мире символы – символы латинского алфавита — в UTF-8 по-прежнему занимают 1 байт, такое кодирование экономичнее, чем чистый Юникод.
В кодируемом английском тексте используется только 26 букв латинского алфавита и еще 6 знаков пунктуации. В этом случае текст, содержащий 1000 символов можно гарантированно сжать без потерь информации до размера:
Словарь Эллочки – «людоедки» (персонаж романа «Двенадцать стульев») составляет 30 слов. Сколько бит достаточно, чтобы закодировать весь словарный запас Эллочки? Варианты: 8, 5, 3, 1.











