Нейронные сети: распознавание образов и изображений c помощью ИИ
ИНС (искусственные нейросети) – это математическая модель функционирования традиционных для живых организмов нейросетей, которые представляют собой сети нервных клеток. Как и в биологическом аналоге, в искусственных сетях основным элементом выступают нейроны, соединенные между собой и образующие слои, число которых может быть разным в зависимости от сложности нейросети и ее назначения (решаемых задач).
Пожалуй, самая популярная задача нейросетей – распознавание визуальных образов. Сегодня создаются сети, в которых машины способны успешно распознавать символы на бумаге и банковских картах, подписи на официальных документах, детектировать объекты и т.д. Эти функции позволяют существенно облегчить труд человека, а также повысить надежность и точность различных рабочих процессов за счет отсутствия возможности допущения ошибки из-за человеческого фактора.
Нейросеть – это математическая модель в виде программного и аппаратного воплощения, строящаяся на принципах функционирования биологических нейросетей. Сегодня такие сети активно используют в практических целях за счет возможности не только разработки, но и обучения. Их применяют для прогнозирования, распознавания образов, машинного перевода, распознавания аудио и т.д.
Обычной зачастую называют полносвязную нейронную сеть. В ней каждый узел (кроме входного и выходного) выступает как входом, так и выходом, образуя скрытый слой нейронов, и каждый нейрон следующего слоя соединён со всеми нейронами предыдущего. Входы подаются с весами, которые в процессе обучения настраиваются и не меняются в последствии. При этом у каждого нейрона имеется порог активации, после прохождения которого он принимает одно из двух возможных значений: -1 или 1, либо 0 или 1.
Сверточная НС имеет специальную архитектуру, которая позволяет ей максимально эффективно распознавать образы. Сама идея СНС основывается на чередовании сверточных и субдискретизирующих слоев (pooling), а структура является однонаправленной. СНС получила свое название от операции свертки, которая предполагает, что каждый фрагмент изображения будет умножен на ядро свертки поэлементно, при этом полученный результат должен суммироваться и записаться в похожую позицию выходного изображения. Такая архитектура обеспечивает инвариантность распознавания относительно сдвига объекта, постепенно укрупняя «окно», на которое «смотрит» свёртка, выявляя всё более и более крупные структуры и паттерны в изображении.
Может ли обучить современный компьютер идентифицировать определенный объект на фотографии

Одно из важных современных направлений в программном обеспечении — программы, обладающие компьютерным зрением. Данная технология позволяет анализировать информацию в изображениях и видео-файлах. Например, читать текст или обнаруживать расположение определенных объектов.
Для практического изучения данной технологии мной была поставлена задача определения кружки на фотографии. Для реализации было решено использовать android + OpenCV (http://opencv.org/). OpenCV — это библиотека компьютерного зрения с открытым исходным кодом, разработанная для С++, python, java и многих других языков. Она имеет множество функций, но нас интересует возможность обрабатывать изображения и проводить на них поиск объектов с помощью каскадного алгоритма Виолы-Джонса.
Алгоритм Виолы-Джонса — это метод обнаружения объектов на изображениях, основанный на признаках Хаара. Основные его особенности — высокая скорость работы и низкая частота ложных срабатываний. Изначально алгоритм был разработан для обнаружения лиц на изображениях, но его можно натренировать на обнаружение других объектов. Для своей работы он использует разбиения (splitting) изображения на области, оценку яркости в этих областях и отсечения областей, где классифицируемый объект однозначно не находится. Данный алгоритм реализован в openCV отдельной функцией, которой на вход требуется файл-классификатор, определяющий веса для работы алгоритма и изображение, на котором будет проводиться поиск.
Для тренировки классификатора я использовал программу Cascade-Trainer-GUI (http://amin-ahmadi.com/cascade-trainer-gui/), которая предоставляет оконный интерфейс для стандартных программ из набора OpenCV — opencv_createsamples и opencv_traincascade.
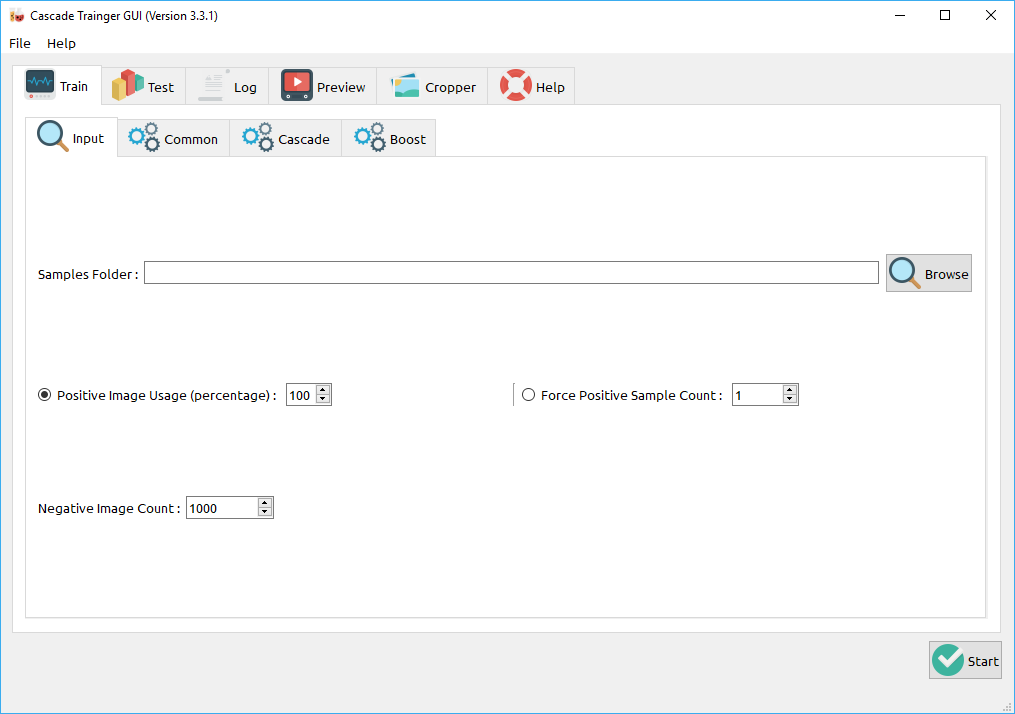
Процесс тренировки начинается с подготовки исходных данных. В качестве исходных данных выступают изображения, содержащие и не содержащие исходный объект. Изображения с объектом считаются позитивными и отправляются в папку p, а те, на которых объект отсутствует — негативными и помещаются в папку n. Стоит заметить, что позитивные изображения должны содержать только распознаваемый объект и ничего больше. Иначе придётся создать файл, который будет содержать координаты объекта на изображении.
opencv_createsamples — это программа, которая генерирует исходные файлы для opencv_traincascade. Негативы формируются по принципу нарезки: из негативной фотографии вырезается случайная область. Позитивы создаются путем помещения какого-нибудь позитивного изображения объекта на негативное, незначительных изменений яркости, поворота и перспективы
После создания этих изображений используется opencv_traincascade, которая принимает полученные образцы и на их основе определяет веса и пропускные пороги для каскадного классификатора. Веса должны быть подобраны так, чтобы сеть отвергала все негативные изображения и принимала все позитивные.
Но это только теория. На практике эти процессы осуществляет Cascade-Trainer-GUI, которому для начала работы требуется только две папки с фотографиями, одна из которых называется p, а другая n. В них хранятся позитивные и негативные образцы соответственно. Для того, чтобы натренировать сеть, мне потребовалось 47 фотографий моего объекта с разным углом камеры, углом падения света, наклоном и яркостью. После этого я удвоил данное число путем зеркального отражения. Негативных фотографий было только 42, но с помощью нарезки изображений было создано 1000 негативных образцов. Часть негативных изображений для разнообразия была взята из интернета.


После подготовки данных настраиваем инструмент для тренировки. По большому счёту, большинство настроек не требуется менять, они уже установлены в оптимальные значения, но мне потребовалось изменить пару опций во вкладке train-cascade, а именно sample width и sample height. Эти опции задают пропорции для образцов, для области, которую классификатор будет впоследствии обнаруживать. И если оставить их как есть (обе равны 24 по умолчанию), то обнаруживаемая область будет квадратной. Так как кружка плохо вписывается в квадратную область, то я задал эти параметры равными 30 и 40 соответственно, что исходило из пропорций моих позитивных образцов.
Что такое OpenCV?
В области искусственного интеллекта задачи компьютерного зрения — одни из самых интересных и сложных.
Компьютерное зрение работает как мост между компьютерным программным обеспечением и визуальной картиной вокруг нас. Оно дает ПО возможность понимать и изучать все видимое в окружающей среде.
Например, на основе цвета, размера и формы плода мы определяем разновидность определенного фрукта. Эта задача может быть очень проста для человеческого разума, однако в контексте компьютерного зрения все выглядит иначе.
Сначала мы собираем данные, затем выполняем определенные действия по их обработке, а потом многократно обучаем модель, как ей распознавать сорт фрукта по размеру, форме и цвету его плода.
В настоящее время существуют различные пакеты для выполнения задач машинного обучения, глубокого обучения и компьютерного зрения. И безусловно, модуль, отвечающий за компьютерное зрение, проработан лучше других.
OpenCV — это библиотека с открытым программным кодом. Она поддерживает различные языки программирования, например R и Python. Работать она может на многих платформах, в частности — на Windows, Linux и MacOS.
Основные преимущества OpenCV :
- имеет открытый программный код и абсолютно бесплатна
- написана на C/C++ и в сравнении с другими библиотеками работает быстрее
- не требует много памяти и хорошо работает при небольшом объеме RAM
- поддерживает большинство операционных систем, в том числе Windows, Linux и MacOS.
Установка
Здесь мы будем рассматривать установку OpenCV только для Python. Мы можем установить ее при помощи менеджеров pip или conda (в случае, если у нас установлен пакет Anaconda).
1. При помощи pip
При помощи pip процесс установки может быть выполнен с использованием следующей команды:
2. Anaconda
Если вы используете Anaconda, то выполните следующую команду в окружении Anaconda:
Что предлагают ИТ-гиганты
Ведущие технокомпании уже достаточно давно предлагают использовать свои сервисы распознавания изображений. Так, у Amazon есть Rekognition (с 2016), у Google есть Lens и Cloud Vision (с 2017).
Amazon Rekognition
Amazon Rekognition — SaaS-система распознавания изображений, позволяющая добавить в приложение функцию автоматического анализа и распознавания фото/видео. Работает на основе глубокого обучения, которое проводится двумя методами: на предварительных данных, собранных Amazon или его партнёрами; на данных, настраиваемых пользователем.
Amazon Rekognition распознаёт объекты, людей, действия, сцены, текст на фото/видео, а также определяет нежелательный контент. После распознавания изображения лица, оно анализируется с высокой точностью, что позволяет искать лица, которые можно применять для обнаружения, анализа и сравнения в тех случаях, когда необходима проверка или подсчёт людей. Система даже умеет определять эмоциональное состояние лица по внешним признакам.
Бизнесу Amazon Rekognition предлагает дополнительный сервис Custom Labels, с помощью которого можно идентифицировать объекты и сцены, соответствующие сфере деятельности. Например, можно создать модель для классификации деталей оборудования или для выявления нездоровых животных. Custom Labels сами построят модель, так что пользователям не надо проводить машинное обучение. Им нужно только загрузить фотографии объектов или сцен, а всё остальное сделает сервис.
Google Lens и Cloud Vision
Google Lens — приложение распознавания изображений, предназначенное для получения информации об идентифицируемых объектах. Работает на основе визуального анализа, который проводится нейронной сетью. Благодаря глубокому обучению она улучшает методы распознавания изображений и расширяет возможности приложения.
Сначала это было отдельное приложение, потом его интегрировали в стандартное приложение камеры на Android. Если направите камеру смартфона на объект, Google Lens попытается идентифицировать объект, считать штрихкод или QR-код, метки или текст, затем отобразит результаты поиска, веб-страницы, дополнительную информацию. Lens также внедрён в приложения Google Фото и Google Assistant. Сегодня приложение умеет по фотографии переводить текст, звонить по номеру, искать вещи или мебель в интернет-магазинах, распознавать меню и рекомендовать блюда из него. Не говоря уже об идентификации достопримечательностей, животных, растений.
Бизнесменам и разработчикам Google предлагает Cloud Vision API, который позволяет легко интегрировать функции распознавания изображений в собственные приложения, чтобы они тоже могли идентифицировать объекты на фотографиях. API-сервис умеет распознавать лица, логотипы брендов, тексты — всё, что можно использовать в бизнесе. Благодаря этому Google API для распознавания изображений работает приложение Lens.
Обнаружение объекта
По сути, обнаружение объектов – это современная компьютерная технология, которая связана с обработкой изображений, глубоким обучением и компьютерным зрением для обнаружения объектов, присутствующих в файле изображения. Все технологии, используемые в методе обнаружения объектов (как мы упоминали ранее), связаны с обнаружением экземпляров объекта на изображении или видео.
В этом разделе мы узнаем, как мы можем выполнять обнаружение объектов в изображении или видео с помощью библиотеки OpenCV. Сначала мы импортируем библиотеку OpenCV в программу Python, а затем будем использовать функции для обнаружения объектов в предоставленном нам файле изображения. Но, прежде чем использовать и импортировать библиотечные функции, давайте сначала установим требования для использования техники обнаружения объектов.
В этом уроке мы будем использовать каскадную технику Хаара для обнаружения объектов. Давайте сначала узнаем вкратце о каскадной технике Хаара.
Каскад Хаара
По сути, каскадная техника Хаара – это подход, основанный на машинном обучении, при котором мы используем множество положительных и отрицательных изображений, чтобы научиться классифицировать изображения. Каскадные классификаторы Хаара считаются эффективным способом обнаружения объектов с помощью библиотеки OpenCV. Теперь давайте разберемся с концепцией положительных и отрицательных изображений, которую мы обсуждали ранее:
- Положительные изображения: это изображения, которые содержат объекты, которые мы хотим идентифицировать с помощью классификатора.
- Отрицательные изображения: это изображения, которые не содержат никаких объектов, которые мы хотим обнаружить классификатором, и это могут быть изображения всего остального.
Требования для обнаружения объектов с помощью Python OpenCV
Мы должны сначала установить некоторые важные библиотеки в нашу систему, поскольку это важное требование для выполнения задач обнаружения объектов. Мы должны установить следующие библиотеки в нашу систему в качестве требования для выполнения обнаружения объектов:
- библиотека OpenCV
Прежде всего, требование для выполнения обнаружения объектов с использованием библиотеки OpenCV состоит в том, что библиотека OpenCV должна присутствовать на нашем устройстве, чтобы мы могли импортировать ее в программу Python и использовать ее функции обнаружения объектов. Если этой библиотеки нет в нашей системе, мы можем использовать следующую команду в нашем терминале командной строки для ее установки:

Когда мы нажимаем клавишу ввода после написания этой команды в терминале, установщик pip в командной строке начнет установку библиотеки OpenCV в нашу систему.

Как мы видим, библиотека OpenCV успешно установлена в нашей системе, и теперь мы можем импортировать ее в программу Python, чтобы использовать ее функции.
- библиотека matplotlib
Matplotlib очень полезна при открытии, закрытии, чтении изображений в программе Python, и поэтому установка этой библиотеки для обнаружения объектов становится важным требованием. Если библиотека matplotlib отсутствует в нашей системе, мы должны использовать следующую команду в нашем терминале командной строки, чтобы установить ее:

Когда мы нажимаем клавишу ввода после написания этой команды в терминале, установщик pip в командной строке начнет установку его в нашу систему.

Как мы видим, библиотека matplotlib успешно установлена в нашей системе, и теперь мы можем импортировать ее в программу Python, чтобы использовать ее функции для открытия, чтения и т. д. изображений.
Мы установили все необходимые библиотеки для выполнения обнаружения объектов, и теперь мы можем перейти к реализации части этой задачи.
Объяснение логики машинного обучения
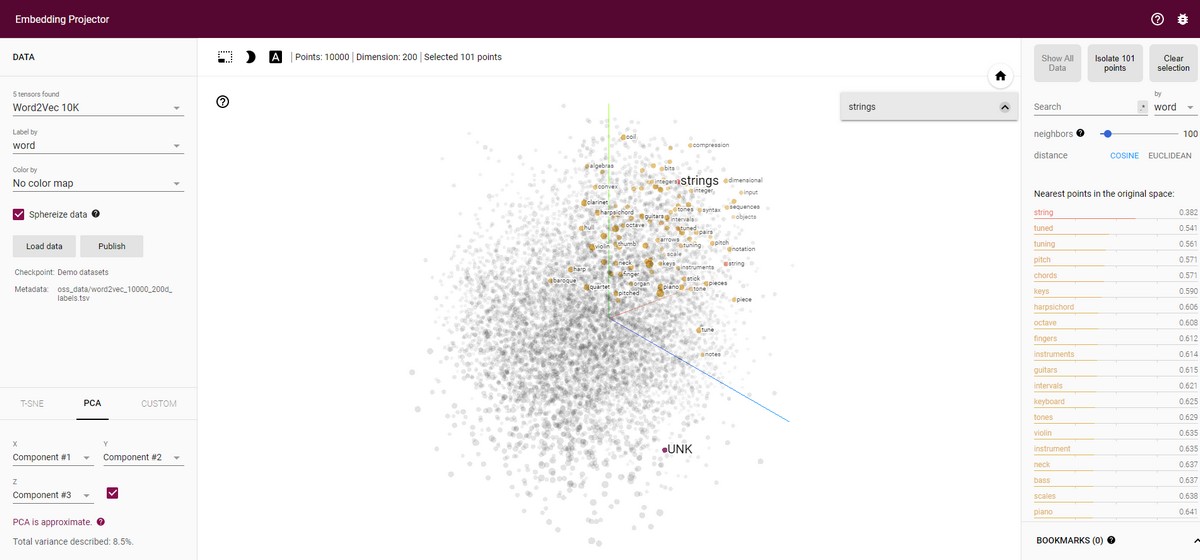
Проект Visualizing High-Dimensional Space (“Визуализация многомерного пространства”) создавался для того, чтобы объяснить простым людям и начинающим разработчикам, как работают нейросети. Когда ИИ, оперируя большими базами данных, получает информацию (например, вашу фотографию, введенную фразу или только что нарисованное изображение), он сравнивает входящие данные с теми, что у него уже есть. VHDS наглядно демонстрирует корреляцию одного лишь выбранного вами слова с миллионами аналогичных понятий.