8 лучших программ и веб-сервисов для сканирования и распознавания текста
Наверное, каждому знакома ситуация, когда скан документа, например, страницы книги, необходимо преобразовать в печатный текст. Для этого существуют специальные программы, но основная их масса очень мало кому известна. На слуху у всех, пожалуй, только ABBYY FineReader. Действительно, FineReader вне конкуренции. Это лучшая программа для сканирования и распознавания текста на русском языке, однако выпускается она исключительно в платных версиях и стоит весьма недешево. Многие ли готовы выложить за самую бюджетную лицензию почти 7 000 рублей, если собираются обрабатывать одну-две книги в год?
Если вы считаете покупку дорогостоящего коммерческого продукта неоправданной, почему бы не воспользоваться аналогами, среди которых есть бесплатные? Да, они не так богаты функциями, но со многими задачами, которые, как считают многие, «по зубам» только FineReader, справляются вполне успешно. Так давайте познакомимся с несколькими доступными альтернативами. И заодно посмотрим, чем они отличаются от общепризнанного эталона.
NAPS2
NAPS2 — утилита для сканирования документов и распознавания текста. В приложении есть возможность пакетного сканирования и инструмент для печати документов. Отсканированные документы формата PDF можно отправить по электронной почте.
Чтобы выполнить сканирование документов с помощью утилиты NAPS2, необходимо выбрать инструмент «Сканировать».
.png)
Откроется окно создания нового профиля. Укажите отображаемое имя, выберите тип драйвера — WIA/TWAIN. Далее нужно выбрать устройство для сканирования, источник бумаги, размер страницы и разрешение. Установите глубину цвета отсканированного документа, настройте масштаб и яркость. После выполнения этих настроек профиля можно приступать к сканированию.
.png)
Выберите инструмент «Распознавание», чтобы начать процесс распознавания текста на отсканированном документе или графическом изображении. Откроется небольшое окно, в котором нужно выбрать язык текста для распознавания. Выберите один или несколько языков. Утилита автоматически загрузит языковые пакеты для приложения NAPS2.
.png)
Нажмите «Импорт» и выберите файл для распознавания текста. После загрузки документа нажмите «Распознавание». Утилита автоматически распознает текст, который присутствует на изображении или электронном документе.
Основные преимущества программы NAPS2:
- пакетное сканирование документов;
- распознавание текста на более чем на 100 языках;
- отправка полученных файлов формата PDF по электронной почте;
- возможность создания нескольких профилей для работы;
- печать документов через принтер.
- отсутствует инструмент для склейки нескольких электронных документов;
- нет возможности работы с веб-камерой;
- нет функции поиска по тексту.
NAPS2 можно загрузить и установить на компьютер бесплатно, интерфейс переведен на русский язык.
ТОП-9 функций, которые должна иметь хорошая программа
Каждая программа по-своему уникальна, но есть ряд функций, которые каждое хорошее приложение должно иметь, чтобы быть полезной большинству пользователей во многих ситуациях. Приведем вам перечень тех свойств, которые обязательно должны быть в выбранной вами программе:
- Возможность настроить разные цвета, разрешение документа и размер.
- Возможность вручную выбрать нужную область сканирования.
- Возможность сохранять документы в разных форматах.
- Опция для создания многостраничных документов (чтобы большой объем листов находился в одном документе).
- Программа должна позволять менять порядок страниц путем перетаскивания их мышкой.
- Возможность прямого копирования документов со сканера на принтер.
- Функция распознавания текста.
- Программа должна поддерживать разные языки (хотя бы базовые – английский, испанский, русский, итальянский, французский – чем больше языков, тем лучше).
- Возможность обработки изображения – настройка яркости, контраста и других важных характеристик.
Это основные функции, необходимые практически всегда при сканировании документов. Различные программы могут иметь и другие функции, такие как: галерея эффектов, подача документов, стирание границ и другие.
ШАГ 3: сканирование документа с принтера МФУ
Одна из распространенных офисных задач — это отсканировать лист А4 (документ) в формат изображения (скажем JPG или PDF). Несколько наиболее простых способов приведу ниже.
Способ 1
Нажать сочетание Win+R — в появившемся окне «Выполнить» ввести команду control printers и нажать Enter.
Появится окно «Устройства и принтеры» — в нем нужно кликнуть правой кнопкой мыши по своему принтеру и в меню выбрать «Начать сканирование» .
Примечание : разумеется, устройство должно быть включено! Иначе его не будет видно в этой вкладке.
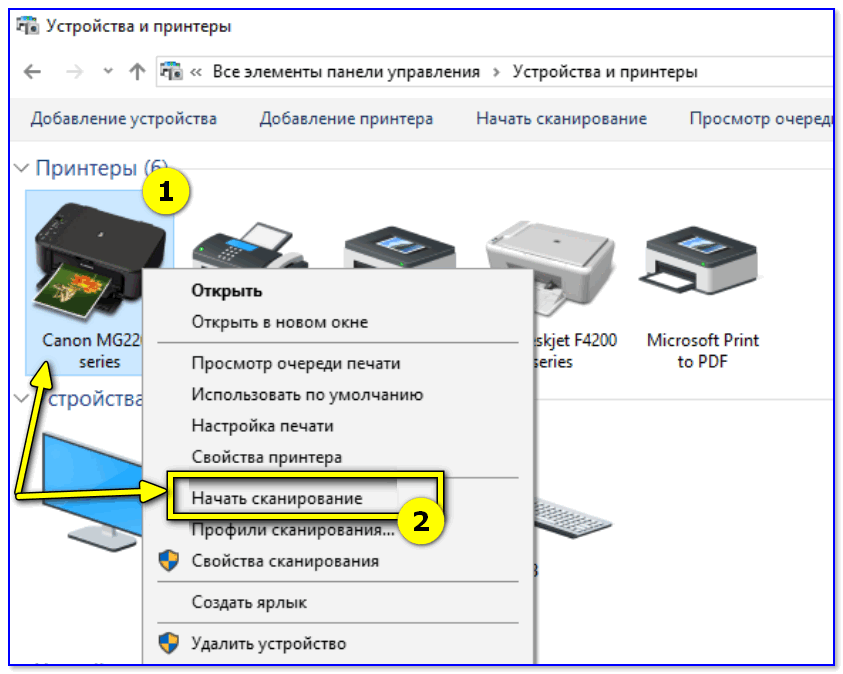
Устройства и принтеры — начать сканирование
Способ 2
Запускаем программу Paint (это программа для рисования, есть практически в каждой версии Windows). Для этого нажмите Win+R, в окно «Выполнить» введите команду mspaint и нажмите Enter.
После кликните по меню «Файл» и выберите вариант получения изображения со сканера или камеры .
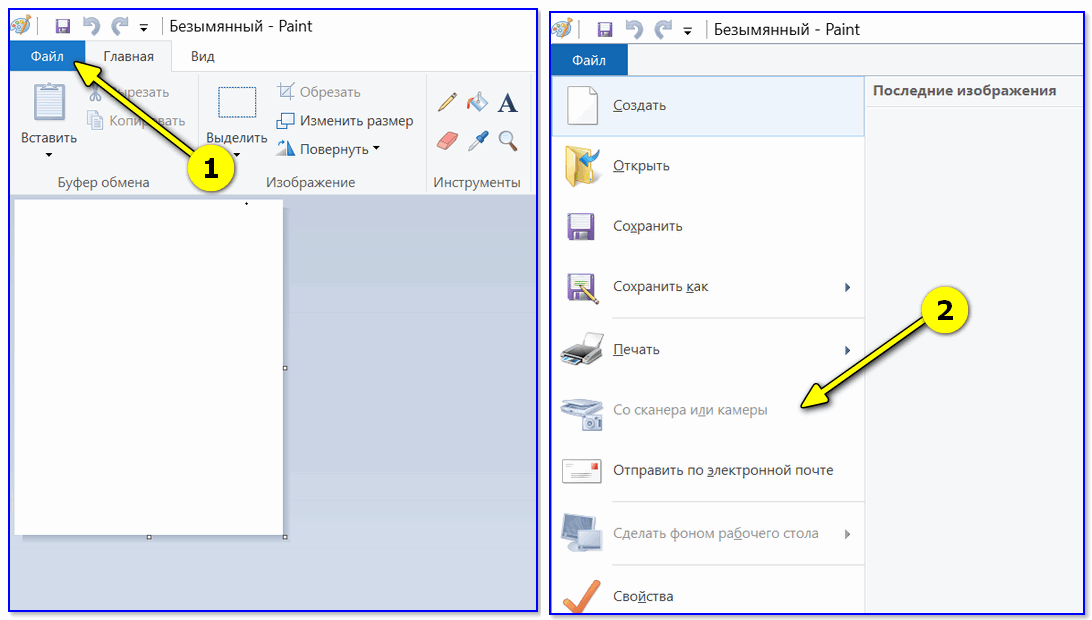
Paint // Со сканера или камеры
Способ 3
Конечно, больше всего опций и возможностей по сканированию предоставляют спец. программы. Одна из таких — Fine Reader (благо, что демо-версия позволяет 30 дней работать с ней бесплатно).
После запуска программы, выберите в меню вариант «Сканировать и сохранить изображения» (подобное окно всегда появляется при первом запуске программы).
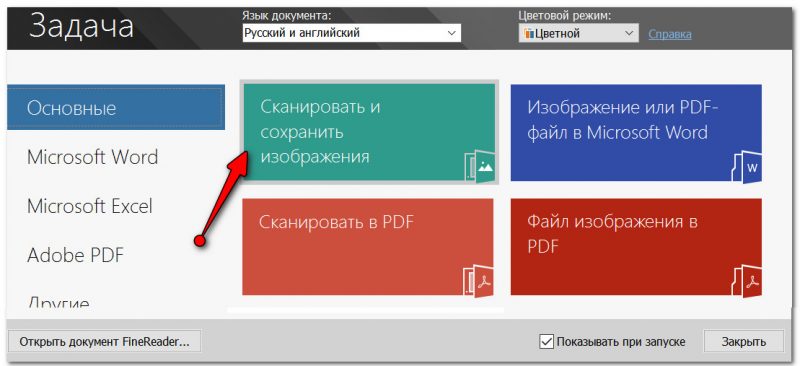
Окно при запуске Fine Reader (кликабельно)
Далее появится окно с настройками сканирования. Здесь важно обратить на несколько параметров:
- разрешение : рекомендую сканировать с разрешением не менее 300 DPI (чем выше количество точек — тем лучше качество получаемой картинки, правда, тем больше ее размер).
- режим сканирования : если отбросить различные «производные», то всего есть 3 режима — серый, черно-белый и цветной. Обычно, документы сканируют в сером, либо цветном режиме;
- яркость : часто нужно «поиграться» с этим параметром, прежде чем будет найдено оптимальное значение (для каждого оборудования, и документа — оно будет своим).
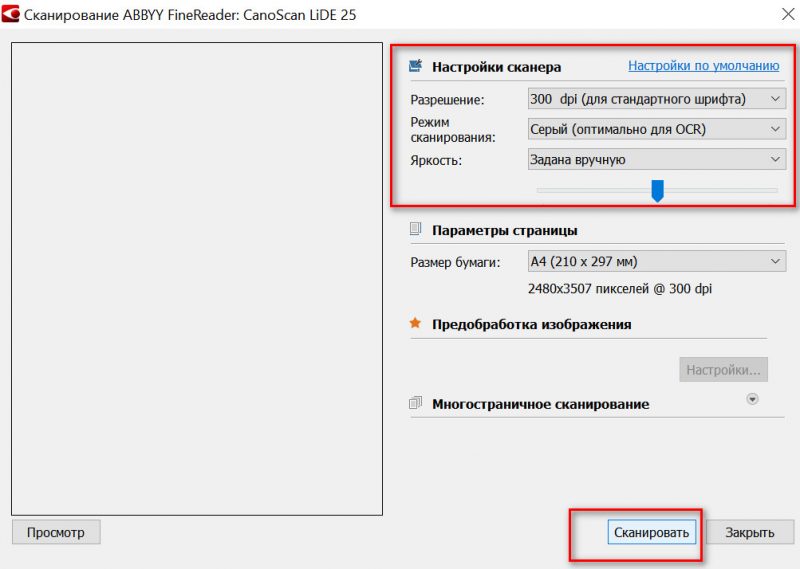
Настройки сканирования (кликабельно)
После того, как лист будет отсканирован, он появится в меню страничек, слева.
Для его сохранения, просто щелкните по нему правой кнопкой мышки и в появившемся контекстном меню выберите вариант «Сохранить выбранные страницы как изображения» (обратите внимание, что также есть варианты сохранения в PDF, WORD, которые также популярны в офисной работе).
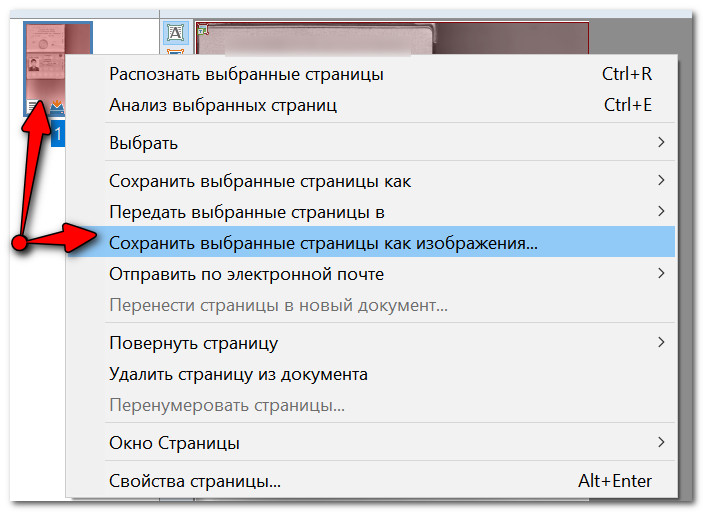
Сохранение выбранных страниц в картинки JPG/PDF/WORD и пр.
Программа для сканирования документов
Самая известная программа для сканирования документов, она очень проста в использовании и проста в понимании.

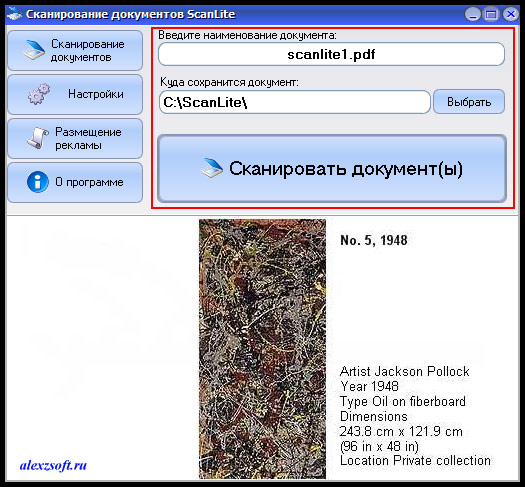
Что имеется в программе:
- Первое это имя документа, который будет отсканирован.
- Второе это путь куда будет отсканирован файл.
- Третье это сама кнопка сканирования.
Внимание! Минус этой программы в том, что приходится каждый раз переименовывать файл (в пункте один), иначе программа перезапишет предыдущий.
Далее идем в настройки:
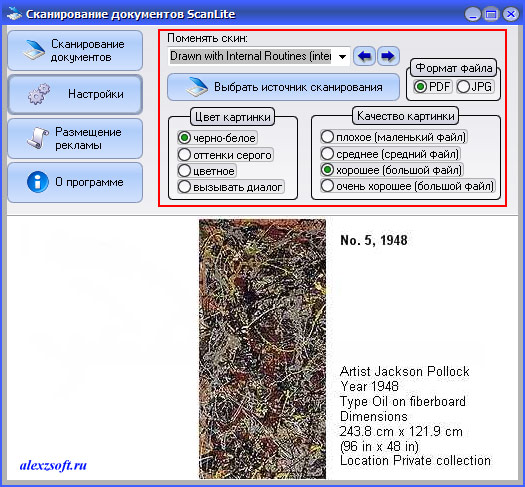
Здесь можно выбрать скин программы, формат pdf (документ) или jpg (картинка), цветное или черно-белое изображение и качество. Думаю тут все понятно.
Распознавание текста
Вершиной «эволюции» программ для сканирования являются программы для распознавания текста. Общий принцип их работы таков. Имеется некая база данных с примерами начертания различных печатных (а иногда даже рукописных!) символов на определённом языке. Программа, получив изображение со сканера или графического файла сравнивает каждый найденный в нём символ с символами в базе данных и при их совпадении сохраняет результат в виде редактируемого текста.
Теоретически нет никакой проблемы, но на практике программы для распознавания текста должны иметь не только базу с десятками вариантов начертаний символов разными шрифтами, но и очень развитые эвристические модули, позволяющие правильно определить наличие текста, а также словари для более корректного определения языка распознавания и конкретных часто употребляемых слов.
Эталоном в данной области фактически является программа компании ABBYY FineReader. На сегодняшний день – это единственный пакет оптического распознавания символов (от сокр. англ. «OCR» – «Optical Character Recognition»), способный качественно распознавать тексты со сложной вёрсткой и различными языками. Правда стоит он немалых денег, поэтому предлагаю рассмотреть несколько менее функциональных, но бесплатных аналогов.
CuneiForm
Ближайшим бесплатным аналогом FineReader обычно называют отечественную программу CuneiForm (читается «кьюнифом» – с англ. «клинопись»):

К сожалению программа с 2007 года не развивается. хотя её исходные коды были выложены во всеобщий доступ. Однако, и в таком виде, в каком она есть, CuneiForm может обеспечить распознавание документов с не особо сложным форматированием.
Интерфейс программы напоминает ранние версии ФайнРидера и реализует те же принципы «всё-в-одном». То есть, с её помощью мы можем получить изображение со сканера, предварительно обработать его и распознать, передав результаты в текстовый редактор или сохранив в файл. Правда, здесь не без оговорок. CuneiForm не всегда корректно работает со сканером, поэтому может потребоваться сначала отсканировать нужные материалы, а затем загрузить их из файла.
Качество распознавания, увы, тоже не на высоте. Если сплошной русский текст программа распознаёт ещё более или менее сносно, то, например, украинский уже гораздо хуже (не говоря об остальных заявленных). Однако, CuneiForm – единственная из бесплатных программ, которые могут распознавать смешанный англо-русский текст, поэтому может быть единственным легальным способом обработки международных документов.
FreeOCR
Гораздо более перспективной в плане качества распознавания моноязыковых текстов можно назвать бесплатную программу FreeOCR:

Программа полностью на английском и в стандартной поставке позволяет распознавать лишь английский, немецкий и ещё некоторые европейские языки (всего 11 штук), однако, благодаря тому, что работает она на базе движка Tesseract (по сути, это GUI к данной OCR-системе), мы можем добавить довольно качественную поддержку практически любых языков. Рассмотрим как это сделать на примере русского.
Первым делом нам нужно зайти на ГитХаб проекта Tesseract в раздел языковых библиотек и скачать оттуда файл нужного языка в формате .traineddata (для русского – rus.traineddata). Этот файл нужно поместить в папку с языками программы, которую проще всего открыть из меню «Settings» – «Open Language Folder».
Следующим шагом будет ручное обновление самого движка Tesseract. Скачайте последнюю его версию со страницы загрузок (рекомендую качать сборку отсюда), установите и скопируйте исполняемый файл tesseract.exe в папку с программой FreeOCR (обычно C:FreeOCR), согласившись на его замену, после чего перезапустите её.
Теперь распознавание должно работать без ошибок. Чтобы его запустить загрузите в программу изображение со сканера, файла или PDF-документа, в выпадающем окошке «OCR Language» справа выберите нужный язык и нажмите кнопку «OCR» на панели инструментов. Немного подождите и получите распознанный текст в правой части рабочей области программы. Этот текст можно тут же поправить, сохранить в TXT, RTF, буфер обмена или передать на редактирование в MS Word (кнопки на средней панели).
Благодаря неплохому развитию Tesseract распознавание в FreeOCR при хорошем качестве скана на порядок лучше, чем в CuneiForm. Недостатком является лишь уже упомянутая невозможность мультиязычного распознавания (русско-английского или русско-украинского). Также не очень удобно то, что в программе нет функции сохранения отсканированных материалов в PDF со слоем распознанного текста (можно сохранить только в виде последовательности JPEG-изображений).
NAPS2
Ещё одна перспективная находка, которая использует базы Tesseract для распознавания более чем 100 языков мира, но при этом является абсолютно бесплатной и даже с открытым исходным кодом – NAPS2 (сокр. англ. «Not Another PDF Scanner» – примерно «Не очередной PDF-сканер»):

Само название данной программы намекает на то, что перед нами не какой-то там ещё один сканер PDF, а нечто более ценное. И это действительно так! По функционалу NAPS2, хоть и недотягивает до флагманов, но стремится к ним. В его арсенале имеется:
- мультиязычный интерфейс (в том числе и русский);
- портативная версия, не требующая установки;
- функция пакетного сканирования с настройкой профилей;
- импорт изображений (PDF-файлы, увы, не поддерживаются);
- базовые функции обработки изображений (поворот, обрезка, регулировка яркости и контрастности);
- сохранение сканов в PDF со слоем распознавания и без, а также с возможностью шифрования или в виде изображений;
- прямая отправка сканов по почте и их распечатка из интерфейса программы.
Правда, не всё так идеально как хотелось бы. Помимо отсутствия возможности открывать напрямую PDF-файлы для распознавания, NAPS2 не имеет встроенного редактора текста или иных инструментов для экспорта распознанных данных. Чтобы скопировать результат придётся сохранить всё в PDF-документ, открыть его в программе-читалке и только там, воспользовавшись инструментом выбора текста, выделить всё и скопировать в буфер обмена.
NAPS2 по умолчанию работает только с английским текстом и требует предварительной загрузки нужных Вам языков. Правда, делается это намного проще, чем в предыдущем случае: достаточно нажать кнопку «Распознавание», в открывшемся окошке кликнуть по ссылке для установки дополнительных языков, отметить языки галочкой в списке, дождаться их установки и выбрать в выпадающем списке для распознавания:

Также при первом сканировании нужно будет задать настройки сканера для создания правильного профиля. Изменить нужно, во-первых, формат бумаги со стандартного американского Letter на A4, а, во-вторых, разрешение со 100 до 300 или 600 DPI. Остальное на Ваше усмотрение (яркость, формат и перочие параметры).
При пакетном сканировании мы можем использовать как сканирование с запросом перед каждой процедурой, так и с задержкой по времени в секундах. При этом результат можно сохранить как в самой программе (по умолчанию), так и в виде одного или серии файлов.
Радует то, что NAPS2, в отличие от некоторых других проектов, продолжает развиваться и не требует никаких доводок для нормальной работы. Это даёт надежду на то, что, даже если он и «не дорастёт» до уровня коммерческого софта, то, по крайней мере, со временем может приблизиться к нему, поскольку потенциал есть и весьма неплохой!
Сканируем паспорт
- Снимите обложку, выньте все лишнее с паспорта.
- Положите документ на стекло и хорошо прижмите крышкой. Проследите, чтобы края листов документа не замялись.
- В настройках сканирования выберите формат для наилучшего качества (bmp или tiff). Разрешение поставьте максимально доступное.
При отсутствии МФУ, но имея два отдельных устройства для печати и сканирования, запросто получится сделать копию паспорта.
- Сначала оцифруйте паспорт на компьютер.
- Далее распечатайте скан паспорта на печатающем устройстве.
Результат ничем не будет отличаться, если бы делалось стандартное ксерокопирование.
ТОП-5 программы для преобразования изображений в PDF для Linux (в том числе Андройд), Mac OS
Почти все представленные далее программы также прекрасно работают на Windows, просто их было решено вынести в отдельную главу, так как подобный функционал предлагают далеко не все разработчики.
Abbyy Finereader
Это однозначно лучшая программа для сканирования документов в pdf от сторонних разработчиков формата, и сделана она российской компанией.
Программа умеет производить высокоточное распознавание текста и его сканирование с бумажных носителей, в том числе газет и текста, который был набран на печатной машинке.
Умеет работать со всеми популярными форматами, а в версии 11 получил возможность сохранять файлы в формате djvu – ближайший конкурент PDF.
Программа переведена на 192 языка и умеет распознавать их, за что и получила широкое распространение в мире. Имеет, по меньшей мере, 20 миллионов активных пользователей.

Распространяется программа платно, имеет доступную для тестирования демо-версию, которая работает 30 дней или 100 страниц. Работает на Windows, Linux и MAC OS.
Adobe Acrobat Reader
Официальный софт от компании Adobe, выпущенный для работы с PDF файлами. Имеет очень широкий функционал и распространяется условно-бесплатно, с пробным периодом, имеет две версии (Pro и Standart) с разным функционалом.











