8 лучших программ для распознавания текста на 2020 год [Free and Paid]
В наши дни почти все (например, фотографии, музыка, видео) стали цифровыми, и это имеет смысл, поскольку цифровым контентом можно удобно управлять. Так как же текстовые документы могут остаться позади? Благодаря достижениям в Оптическое распознавание символов (OCR) техники, теперь стало проще, чем когда-либо оцифровывать печатные или рукописные тексты. Для этого вам нужны действительно хорошие приложения для распознавания текста, и именно об этом и рассказывается в этой статье. Это программное обеспечение может либо получать источник со сканирующих устройств, либо вы можете вводить свои собственные изображения или файлы PDF для преобразования в редактируемый текст. Заинтригованный? Ну, тогда давайте не будем биться вокруг, и перейдем к 8 лучшим программам для распознавания текста, которые вы должны использовать в 2020 году.
Когда дело доходит до оптического распознавания символов, вряд ли найдется что-то, что даже близко подходит к ABBYY FineReader. ABBYY FineReader позволяет загружать текст со всех видов изображений на одном дыхании.
Несмотря на широкий набор функций, ABBYY FineReader очень прост в использовании. Он может извлекать текст практически из всех популярных форматы изображений, такие как PNG, JPG, BMP и TIFF. И это еще не все. ABBYY FineReader также может извлекать текст из файлов PDF и DJVU. После загрузки исходного файла или изображения (которое предпочтительно должно иметь разрешение не менее 300 т / д для оптимального сканирования) программа анализирует его и автоматически определяет различные разделы файла, имеющие извлекаемый текст. Вы можете либо извлечь весь текст, либо выбрать только некоторые конкретные разделы. После этого все, что вам нужно сделать, это использовать опцию Сохранить, чтобы выбрать формат вывода, а ABBYY FineReader позаботится обо всем остальном. Поддерживаются многочисленные форматы вывода, такие как TXT, PDF, RTF и даже EPUB.
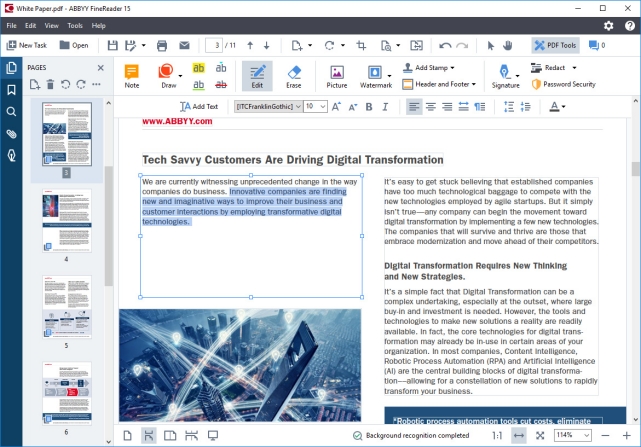
Выводимый текст является полностью редактируемым, и текст даже из самых содержательных документов (например, имеющих несколько столбцов и сложные макеты) извлекается безупречно. Другие функции включают в себя обширная языковая поддержка, многочисленные стили шрифтов / размеры и инструменты коррекции изображения для файлов, полученных из сканеров и камер.
Сказав все это, то, что отличает ABBYY FineReader от остальных программ, это его почти идеальная точность. С новым обновлением Finereader 15, теперь программное обеспечение использует AI для улучшения распознавания символов, AI особенно используется при извлечении текстов из документов, написанных на японском, корейском и китайском языках. Таким образом, если вы хотите получить абсолютно лучшее программное обеспечение для оптического распознавания текста с расширенными функциями, расширенным форматом ввода-вывода и поддержкой обработки, выберите ABBYY FineReader.
Доступность платформы: Windows и macOS
Цена: Платные версии начинаются с $ 199, доступна 30-дневная бесплатная пробная версия
Лидер распознавания текстов — программа ABBYY Finereader
Про FineReader (произносится как Файн Ридер) слышали, наверное, большинство из вас. Эта программа лучшая или одна из лучших для качественного распознавания текстов на русском языке. Программа является платной и цена лицензии для домашнего использования составляет чуть менее 2000 рублей. Также имеется возможность скачать пробную версию FineReader или же воспользоваться онлайн распознаванием текстов в ABBYY Fine Reader Online (бесплатно можно распознать несколько страниц, далее — платно). Все это доступно на официальном сайте разработчика http://www.abbyy.ru.
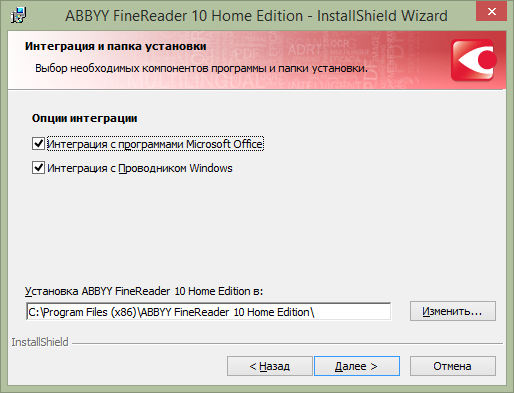
Установка пробной версии FineReader не вызвала никаких проблем. ПО может интегрироваться с Microsoft Office и Проводником Windows, для того чтобы было удобнее запустить распознавание. Из ограничений бесплатной пробной версии — 15 суток использования и возможность распознать не более 50 страниц.

Снимок для тестирования программ распознавания
Так как сканера у меня нет, то для проверки я воспользовался снимком с некачественной камеры телефона, в котором немного отредактировал контрастность. Качество никуда не годное, посмотрим, кто справится.

Меню программы FineReader
FineReader может получать графическое изображение текста напрямую со сканера, из графических файлов или камеры. В моем случае, достаточно было открыть файл изображения. Результат порадовал — всего пара ошибок. Сразу скажу, что это лучший результат из всех проверенных программ при работе с данным образцом — похожее качество распознавания было только на бесплатном онлайн сервисе Free Online OCR (но в этом обзоре мы говорим только о программных средствах, не онлайн распознавании).
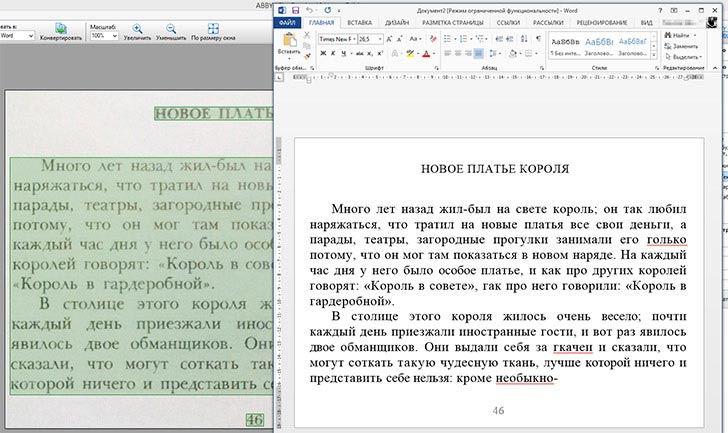
Результат распознавания текста в FineReader
Откровенно говоря, для кириллических текстов у FineReader, наверное, нет конкурентов. Плюсами программы является не только качество распознавания текстов, но и широкая функциональность, поддержка форматирования, грамотный экспорт во множество форматов, включая Word docx, pdf и другие возможности. Таким образом, если задачи OCR — это то, с чем вы сталкиваетесь постоянно, то не пожалейте сравнительно небольшого количества денег и это вполне окупится: вы сэкономите огромное количество времени, быстро получая качественный результат в FineReader. Я, кстати, не рекламирую ничего — действительно считаю, что тем, кому нужно распознать больше десятка страниц, стоит задуматься о покупке такого ПО.
Abbyy Screenshot Reader
Abbyy Screenshot Reader – производный продукт от Abbyy FineReader , работающий, соответственно, на базе технологии OCR от компании Abbyy . Это скриншотер с различными областями захвата экрана и возможностью выбора дальнейших действий – распознавание с копированием в буфер, с сохранением в текстовый файл, в документы Word и Excel , сохранение в снимок, копирование снимка в буфер и т.п. Поддерживает множество языков распознавания, языки распознаёт автоматически.
Работает программа из системного трея, здесь запускается окно захвата. Выставляем нужные параметры захвата – область экрана и тип выгрузки распознанного текста.
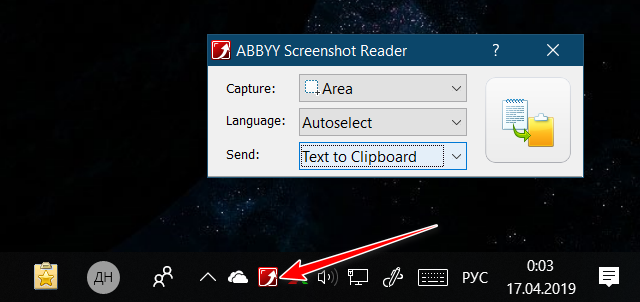
Жмём кнопку захвата, указываем область, если выбран захват области экрана. И далее получаем результат в зависимости от выбранного типа выгрузки.
Abbyy Screenshot Reader – платная программа, стоит $149 . Есть триалка с 15-дневным тестовым периодом.
FreeOCR
FreeOCR — небольшое приложение для оптического распознавания текста. Утилита работает с графическими изображениями (tiff, jpeg, png), PDF-документами. Есть возможность прямого импорта файлов из сканера. Итоговый результат можно сохранить в формате обычного текстового файла или документа Microsoft Word.
Приложение полностью совместимо с операционной системой Windows (32/64 бит). Язык интерфейса — английский. Русская версия не поддерживается. Для комфортной работы с утилитой требуется ОС Windows XP и новее. Модель распространения программы — бесплатная.
После запуска программы FreeOCR откроется главное окно, в котором расположены основные инструменты для работы. На первом этапе необходимо загрузить файл. Для этого нужно выбрать пункт «Open» на панели инструментов.
После этого пользователям необходимо выбрать изображение (tif, bmp, png, jpg, gif) для распознавания текста, который хранится на компьютере. Также с помощью программы можно загрузить PDF-документ. Для этого необходимо выбрать пункт «Open PDF», который расположен на панели инструментов утилиты FreeOCR.

Чтобы загрузить документ из сканера необходимо нажать «Scan». В открывшемся окне пользователям приложения следует выполнить следующие действия:
- Выбрать устройство для сканирования.
- Установить режим цвета: черно-белый или цветной.
- Определить размер страницы.

После того, как документ будет загружен в программу, необходимо запустить процесс распознавания текста. Для этого используется функция «OCR» на панели инструментов.

На выбор доступно два варианта выполнения задачи: распознавание текущей страницы и распознавание всех страниц документа.
Для распознавания текста используется движок Tesseract. Благодаря этому повышается точность анализа текста. Процесс распознавания текстов запускается без использования дополнительных инструментов по выделению отдельных зон документа. Итоговый результат отобразится в правом окне интерфейса утилиты FreeOCR.
- бесплатная модель распространения;
- мощный движок Tesseract для распознавания текста;
- работа со всеми популярными форматами изображений;
- можно загрузить файлы из сканера.
- нет официальной поддержки русского языка.
Яндекс OCR
Недавно обнаружила этот сервис, и он мне очень понравился качеством и простотой использования. Вообще то он предназначен для перевода загруженной картинки, но его можно использоваться и для распознавания текста с картинки. Регистрации не требует, ограничений на количество изображений нет. В данный момент находится в стадии бета-тестирования.
Просто перейдите на https://translate.yandex.ru/ocr, загрузите картинку (можно перетащить) и щелкните «Открыть в Переводчике». Откроется как текст с картинки, так и перевод в правом поле.
Перетащите картинку Результат распознавания
Convertio
Convertio hhttps://convertio.co/ru/ocr/ работает своеобразно, поэтому сравнивать его тяжело. В целом не понравился. Свидетельство ИНН, загруженное целиком, он не распознал совсем, так как плохо выделяет текст среди картинок. Не распозналось ни одного слова! Для его проверки я вырезала текстовый кусочек из ИНН и распознала его — это удалось сделать.
К тому же временами он зависает в попытках что-либо распознать.
Как пользоваться
- Загрузите файл
- Выберите язык
- Выберите выходной формат
- Введите капчу
- Щелкните «Преобразовать»
- Чтобы увидеть результат, промотайте наверх к форме загрузки файлов. Там же можно будет и скачать результат.
Вырезанный и распознанный кусок (целиком не распознается):

Результат работы Convertio
Начал я с бесплатных программ:
- glmageReader
- Paperwork
- VietOCR
- CuneiForm.
- В таких программах как VietOCR, Paperwork, glmageReader можно настроить хранение отсканированных документов в определенные папки, Paperwork умеет их даже сортировать, согласно меткам.
- В основном они хорошо справляются с текстом, а там, где текст распознан некорректно, в некоторых программах можно вручную изменить содержимое, прежде чем экспортировать файл.
Однако есть и проблемы:
- Есть разница между работой с pdf сканами и png. Не всегда удается удачно конвертировать png в pdf.
- Большинство таких программ сложно справляются с распознаванием документов табличного вида, даже самого простого формата. В результате мы получаем распознанный текст без размеченных полей.

Технология сработала достаточно хорошо, Учитывая, что программы бесплатные, описанные выше проблемы допустимы. Однако, я искал более упорядоченного решения.
SimpleOCR
Старенькая бесплатная программа SimpleOCR — тоже весьма достойный инструмент распознавания текстов с электронных изображений и сканов, но, к сожалению, без поддержки русского языка. Зато в ней есть уникальная функция считывания рукописных слов, а также редактор, позволяющий исправить ошибки перед сохранением готового результата.
Другие возможности SimpleOCR:
- Проверка орфографии с возможностью пополнять словарь вручную.
- Чтение документов в низком разрешении и с помарками (есть опция очистки «шума»).
- Максимально близкая подборка шрифта и передача стилей написания (жирный, курсив). При желании функцию можно отключить.
- Одновременная обработка нескольких листов или отдельного фрагмента.
- Выделение возможных ошибок в готовом тексте для ручного редактирования.
- Поддержка множества модификаций сканеров.
- Входные форматы электронных документов: tif, jpg, bmp, ink, а также сканы.
- Сохранение готового текста в форматах txt и doc.
Качество распознавания и печатных текстов, и рукописей довольно высокое.
Программу можно было бы назвать универсальной, если бы не ограничение языковой поддержки. Последняя версия поддерживает только английский, французский и датский языки, добавление других, скорее всего, не планируется. Интерфейс полностью на английском, но прост для понимания. Кроме того, в главном окне есть кнопка «Demo», которая запускает обучающий ролик по работе с SimpleOCR.
Чем отличается сканирование от распознавания?
Как оказалось, сканирование и распознавание текста – это разные вещи. Сканирование листов документа – это его перевод текста в электронный вид. Делается это через сканер или при помощи обычного фотографирования на смартфон или цифровую камеру.
Распознавание – это преобразование сканированного документа (текста) в электронный вид.
Кстати! Для наших читателей сейчас действует скидка 10% на любой вид работы
Google Документы
Помимо всех вышеперечисленных утилит, функция оптического распознавания текстовых фрагментов присутствует в Google Документах. Данный сервис поддерживает работу как с файлами в форматах JPG, PNG и GIF, так и многостраничными PDF –документами. Исходниками могут служить изображения, полученные с помощью сканеров, а также обычные фотографии.

Стоит заметить, что при использовании данного сервиса, в результате не всегда сохраняется оригинальное форматирование. Некоторые структуры, как, например, списки, колонки и сноски, могут быть утеряны.
На это в значительной степени влияет качество загружаемого графического файла. Полученные документы могут быть сохранены на сервисе Google Диск, затем скачаны на компьютер или отосланы на электронную почту.
Каждая из рассмотренных программ обладает достаточным инструментарием для выполнения своего первоначального предназначения – конвертации файлов различных форматов в текстовые документы. Однако они отличаются своим набором дополнительных функций, интерфейсом и поддерживаемыми языками. Для работы стоит выбрать то приложение (или несколько), которое отвечает вашим нуждам и способно наиболее точно справиться с поставленной задачей.











