Кодирование текстовой информации
Множество символов, с помощью которых записывается текст, называется алфавитом.
Число символов в алфавите – это его мощность.
Формула определения количества информации: N = 2 b ,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 2 8 , то вес 1 символа – 8 бит.
Единице измерения 8 бит присвоили название 1 байт:
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Каким же образом текстовая информация представлена в памяти компьютера?
Удобство побайтового кодирования символов очевидно, поскольку байт — наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.
Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Таблицы кодировок [ править ]
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти [math]32[/math] символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов. Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания. Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение [math]256[/math] символов: [math]128[/math] основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) [math]256[/math] символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Конспект урока «Информация. Кодирование информации»
Этот урок посвящён обобщению материала по теме. Сегодня мы с вами вспомним, что такое информация, как кодируется текстовая, графическая и звуковая информация в компьютере, а также, как представляется числовая информация в компьютере.
Начнём мы с вами с определения информации.
Информация – это сведения о предметах, событиях, явлениях и процессах окружающего мира. Она представляется и передаётся в форме знаков, рисунков, фотографий, схем; в виде световых или звуковых сигналов; в виде жестов и мимики; в виде запахов и вкусовых ощущений.

Информацию можно рассматривать с двух сторон: с точки зрения человека и с точки зрения компьютера.
Мы с вами будем рассматривать информацию с точки зрения компьютера. Для этого необходимо представить информацию в форме, понятной для компьютера, то есть в виде битов и двоичных кодов.
Минимальной единицей измерения информации принято считать 1 бит.
Разберёмся на примере.
Вычислить, какой объём информации будет занимать книга в электронном варианте, если известно, что книга содержит 16 страниц. На каждой странице – 16 строк, а в каждой строке – по 24 символа вместе с пробелами. 1 символ = 1 байту.
Для подсчёта объёма информации нам необходимо узнать количество символов в книге. Для этого умножаем количество страниц (16), на количество строк на каждой странице (также на 16), и на количество символов в каждой строке вместе с пробелами, то есть на 24.
16 · 16 · 24 = 6144 (символа).
Также мы с вами знаем, что 1 символ = 1 байту. То есть весь учебник в электронном варианте будет занимать объём, равный 6144 байтам.
6144 : 1024 = 6 (Кбайт).
А сейчас давайте вспомним единицы измерения информации:
1 Кбайт (килобайт) = 1024 байта = 2 10 байт;
1 Мбайт (мегабайт) = 1024 Кбайта = 2 20 байт;
1 Гбайт (гигабайт) = 1024 Мбайта = 2 30 байт;
1 Тбайт (терабайт) = 1024 Гбайта = 2 40 байт;
1 Пбайт (петабайт) = 1024 Тбайта = 2 50 байт;
1 Эбайт (эксабайт) = 1024 Пбайта = 2 60 байт;
1 Збайт (зеттабайт) = 1024 Эбайта = 2 70 байт.
Помимо этого, существует такой подход к измерению информации, как вероятностный. При таком подходе объём занимаемой информации при условии, что число благоприятных исходов равно 1, будет вычисляться по следующей формуле:
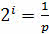
.
Давайте разберёмся на примере.
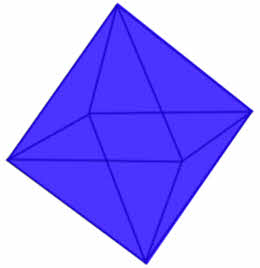
Выполняется бросание симметричной восьмигранной фигуры. Она может с равной вероятностью упасть на любую из сторон. Какое количество информации мы получаем в зрительном сообщении от её падения на одну из граней?
Вероятность события p будет равна:
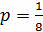
.
Т. к. вероятный благоприятный исход в данном случае может быть только один, а вот общее число исходов будет равно восьми, потому что фигура может упасть на одну из восьми сторон с одинаковой вероятностью.
Так как у нас фигура бросается один раз, то следует использовать следующую формулу:
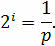
Подставим p в формулу и получим следующее:
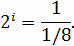
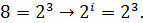
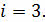
То есть в зрительном сообщении при бросании симметричной восьмигранной фигуры мы получим 3 бита информации.
Ещё один подход, который мы с вами рассмотрим, – алфавитный. Он применяется в компьютерных системах хранения и передачи информации. Здесь используется двоичный способ кодирования информации и важен только размер (объём) хранимого и передаваемого кода. Именно поэтому алфавитный подход также называют объёмным.
Разрядность двоичного кода i и количество возможных кодовых комбинаций или мощность алфавита N связаны следующим соотношением:
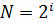
Также необходимо помнить, что 1 бит – это минимальная единица измерения информации.
А сейчас давайте разберёмся на примере. Какой объём будет занимать число F4, которое представлено в шестнадцатеричной системе счисления.
Приступим к решению.
Для начала вспомним, что:
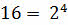
.
Из этого следует, что все символы в этой системе счисления можно закодировать четырёхразрядными двоичными кодами от 0000 до 1111. То есть 1 символ = 4 битам. Соответственно, наше число в шестнадцатеричной системе счисления будет занимать объём:
Если же рассматривать число 71 в восьмеричной системе счисления, то:
1 символ = 3 бита.
Объём информации, которое будет занимать число 71, равно 6 битам.
А сейчас переходим к видам информации, которые воспринимаются компьютером. К ним относятся текстовая, числовая, звуковая, графическая, мультимедийная. Все эти виды информации в компьютере кодируются.
Кодирование – это процесс представления информации в удобной для её хранения и/или передаче форме.
Начнём с рассмотрения текстовой информации в памяти компьютера. Каждая буква алфавита, цифра, знак препинания или любой другой символ, который нужен для записи текста, обозначается двоичным кодом, длина которого является фиксированной. Так, например, в системе кодирования Windows, таблица которого содержит 256 символов, каждый символ заменяется на восьмиразрядное целое положительное двоичное число, которое хранится в 1 байте памяти. Такое число является порядковым номером символа в кодовой таблице.
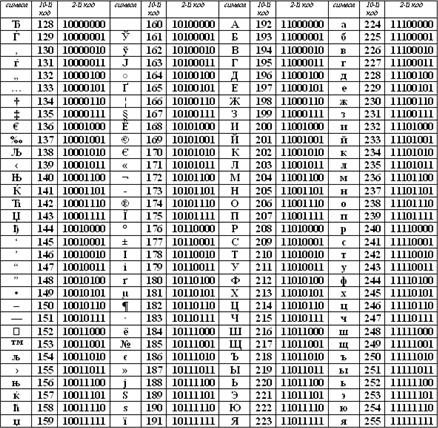
То есть под хранение 1 символа используется 8 бит или 1 байт. Также мы можем заметить, что два в восьмой степени равно двумстам пятидесяти шести.
Но такой кодировки достаточно лишь для одновременного кодирования не более чем 2 языков.
Для одновременной работы с большим количество языков в 1991 году был разработан новый стандарт кодировки символов – Юникод.
Юникод, или Унико́д (англ. Unicode), – это стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков.

В Юникод каждый символ кодируется шестнадцатибитовым двоичным кодом. Это говорит о том, что один символ будет занимать 16 бит или 2 байта. Также следует отметить, что 2 16 = 65 536. И именно такое максимальное количество символов будет содержать таблица Юникод.
Таким образом можно сделать вывод, что в зависимости от разрядности используемой кодировки, информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 бит или 1 байт – при использовании восьмиразрядной кодировки;
• 16 бит или 2 байта – при использовании шестнадцатиразрядной кодировки.
Если же сравнивать таблицы кодировок Windows и Юникод, то можно сделать вывод, что при кодировании текста при помощи таблицы Юникод, его информационный объём будет в 2 раза больше, чем если бы мы кодировали этот же текст при помощи таблицы Windows. Но в то же время не стоит забывать, что при помощи таблицы кодировки Windows мы можем работать одновременно не более чем с 256 различными символами.
А теперь перейдём к кодированию графической информации.
Любое графическое изображение состоит из пикселей. Пиксель – это наименьший элемент изображения, получаемый с помощью компьютерного монитора или принтера. Для того, чтобы увидеть пиксель на изображении, нужно его увеличить.

А сейчас разберёмся непосредственно с кодированием графической информации.
Начнём с чёрно-белых изображений.

Каждый пиксель может иметь одно из двух состояний: чёрный или белый цвет. Для кодирования этой информации требуется 1 бит. Так, например, для кодирования чёрно-белого изображения, размер которого составляет 4 х 8 пикселей, нам понадобиться 32 бита или же 4 байта.
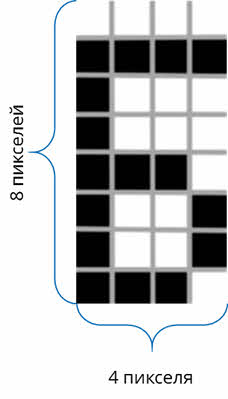
Современные компьютеры имеют просто огромные палитры цветов. Само же количество цветов в таких палитрах зависит от того, сколько двоичных разрядов отводится для кодирования цвета пикселя.
Если размер кода цвета равен b битов, то количество цветов (размер палитры) K вычисляется по формуле:
K = 2 b .
Величину b в компьютерной графике называют битовой глубиной цвета.
Глубина цвета – это величина, обозначающая то, какое количество цветов или оттенков передаёт изображение.
В настоящее время наиболее распространены значения глубины цвета 8, 16 и 24 бита.
Разберёмся на примере. Нам дано изображение размером 16 х 16 при глубине цвета в 8 бит. Найти количество цветов в палитре и объём памяти, который будет занимать изображение.
Количество цветов в палитре находится по формуле:
Для нахождения же объёма памяти, который будет занимать изображение, необходимо перемножить размеры изображения и всё это умножить на глубину цвета.
16 · 16 · 8 = 2048 (бит).
2048 : 8 = 256 (байт).
Переходим к кодированию звука в компьютере.
Для того, чтобы кодировать звуковую информацию, нужно её записать.
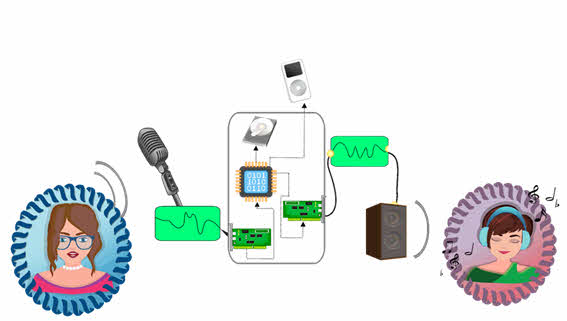
С помощью микрофона происходит запись звука в память компьютера, то есть преобразование непрерывных звуковых сигналов в непрерывный электрический сигнал. Но компьютер может работать только с цифровой информацией, поэтому для работы со звуком в компьютере необходимо его дискетизировать. Дискретизация – это процесс обработки информации при помощи звуковой карты или аудиоадаптера, в результате которой непрерывная информация преобразуется в прерывистую, состоящую из отдельных частей, последовательность нулей и единиц.
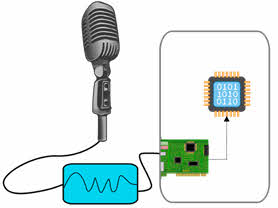
Звуковая карта – это устройство для записи и воспроизведения звука на компьютере.
То есть задача звуковой карты – с определённой частотой производить измерения уровня звукового сигнала и результаты измерения записывать в память компьютера. Этот процесс называют оцифровкой звука.
Количество измерений может лежать в диапазоне от 8000 (частота радиотрансляции) до 48 000 Гц (качество звучания аудио-CD).
То есть чем больше частота дискретизации, тем качественнее звук.
Промежуток времени между двумя измерениями называется периодом измерений – обозначается буквой t и измеряется в секундах.
Обратная величина называется частотой дискретизации. Она обозначается буквой ? и измеряется в герцах.
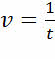
.
Таким образом на качество преобразования звука влияет несколько условий:
· частота дискретизации, то есть сколько раз в секунду будет измерен исходный сигнал;
· разрядность дискретизации – количество битов, выделяемых для записи каждого результата измерений.
При воспроизведении звукового файла цифровые данные преобразуются в электрический аналог звука. К звуковой карте подключаются наушники или звуковые колонки. С их помощью электрические колебания преобразуются в механические звуковые волны, которые воспринимают наши уши.
Таким образом, чем больше разрядность и частота дискретизации, тем точнее представляется звук в цифровой форме и тем больше размер файла, хранящего его.
Разберёмся на примере.
Определить качество звука (качество радиотрансляции или аудио-CD), если известно, что объём моноаудиофайла длительностью звучания в 10 секунд, равен 940 Кбайт. Разрядность аудиоадаптера равна 16 бит.
Рассмотрим решение. Для начала переведём 940 Кбайт в биты.
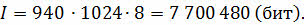
Мы знаем, что для того, чтобы найти размер цифрового аудиофайла, нужно время звучания или записи звука умножить на частоту дискретизации и умножить на разрядность регистра.
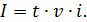
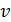
Отсюда мы можем найти . Для этого нужно размер аудиофайла разделить на произведение времени звучания и разрядности аудиоадаптера.
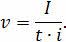
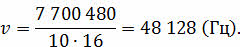
Мы получили частоту дискретизации, близкую к самой высокой. Запишем ответ: качество аудио-CD.
Нам осталось рассмотреть представление числовой информации в компьютере.
Числовая информация в компьютере может представляться в различных системах счисления. Основная же система счисления, в которой представляется информация в компьютере, – двоичная.
При выполнении каких-либо арифметических действий над числами, которые представлены в различных системах счисления, нужно перевести их в одну, например, в десятичную, а затем, после выполнения всех арифметических действий, перевести десятичное число в ту систему счисления, которая требуется по условию задания.
Для перевода числа, которое представлено в системе счисления с основанием q, в десятичную систему счисления, нужно:
1) перейти к его развёрнутой записи;
2) заменить буквы на соответствующие им числа в десятичной системе счисления, если таковые имеются;
3) вычислить значение получившегося выражения.
Для того, чтобы перевести целое десятичное число в систему счисления с основанием q, нужно:
1) последовательно выполнять деление данного числа и получаемых целых частных на основание новой системы счисления до тех пор, пока не получим частное, равное нулю;
2) полученные остатки, которые являются цифрами числа в новой системе счисления, привести в соответствии с алфавитом новой системы счисления.
3) составить число в новой системе счисления, записывая его справа налево, начиная с последнего полученного остатка.
Пришла пора подвести итоги урока. Сегодня мы с вами вспомнили, что такое информация, как кодируется текстовая, графическая и звуковая информация в компьютере, а также, как представляется числовая информация в компьютере.
Содержание
Для того чтобы сохранить информацию, ее надо закодировать. Любая информация всегда хранится в виде кодов.
Код — набор условных обозначений для представления информации.
Кодирование — процесс представления информации в виде кода.
Для общения друг с другом мы используем код — русский язык. При разговоре этот код передается звуками, при письме — буквами.
Водитель передает сигнал с помощью гудка или миганием фар. Вы встречаетесь с кодированием информации при переходе дороги в виде сигналов светофора.
Закодировать можно и звуковую информацию: для этого существует особый метод кодирования — нотная грамота.
Та же проблема универсального средства кодирования достаточно успешно реализуется в отдельных отраслях техники, науки и культуры.
В качестве примеров можно привести систему записи математических выражений, телеграфную азбуку, морскую флажковую азбуку, систему Брайля для слепых и многое другое.
Таким образом, кодирование сводится к использованию совокупности символов по строго определенным правилам.
Кодировать информацию можно различными способами: устно; письменно; жестами или сигналами любой другой природы.
Юникод — появление универсальной кодировки текста (UTF 32, UTF 16 и UTF 8)
Эти тысячи символов языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных кодировках ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой кодировкой текста, вышедшей под эгидой консорциума Юникод, была кодировка UTF 32 . Цифра в названии кодировки UTF 32 означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного символа в новой универсальной кодировке UTF 32.
В результате чего один и то же файл с текстом, закодированный в расширенной кодировке ASCII и в кодировке UTF 32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью UTF 32 число символов равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество символов использовать в кодировке вовсе и не было необходимости, однако при использовании UTF 32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много и такое расточительство себе никто не мог позволить.
В результате развития универсальной кодировки Юникод появилась UTF 16 , которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. UTF 16 использует два байта для кодирования одного символа. Например, в операционной системе Windows вы можете пройти по пути Пуск — Программы — Стандартные — Служебные — Таблица символов.
В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберите в Дополнительных параметрах набор символов Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из этих символов вы сможете увидеть его двухбайтовый код в кодировке UTF 16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF 16 с помощью 16 бит? 65 536 символов (два в степени шестнадцать) было принято за базовое пространство в Юникод. Помимо этого существуют способы закодировать с помощью UTF 16 около двух миллионов символов, но ограничились расширенным пространством в миллион символов текста.
Но даже удачная версия кодировки Юникод под названием UTF 16 не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них после перехода от расширенной версии кодировки ASCII к UTF 16 вес документов увеличивался в два раза (один байт на один символ в ASCII и два байта на тот же самый символ в кодировке UTF 16). Вот именно для удовлетворения всех и вся в консорциуме Юникод было решено придумать кодировку текста переменной длины .
Такую кодировку в Юникод назвали UTF 8 . Несмотря на восьмерку в названии UTF 8 является полноценной кодировкой переменной длины, т.е. каждый символ текста может быть закодирован в последовательность длинной от одного до шести байт. На практике же в UTF 8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить.
В UTF 8 все латинские символы кодируются в один байт, так же как и в старой кодировке ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в UTF 8. Т.е. базовая часть кодировки ASCII перешла в UTF 8.
Кириллические же символы в UTF 8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания кодировок UTF 16 и UTF 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. Производителям шрифтов остается только исходя из своих сил и возможностей заполнять это кодовое пространство векторными формами символов текста.
Теоретически давно существует решение этих проблем. Оно называетсяUnicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодированоN=2 16 =65 536 символов.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Для символов кириллицы в Юникоде выделено два диапазона кодов:
Cyrillic (#0400 — #04FF)
Cyrillic Supplement (#0500 — #052F).
Но внедрение таблицы Unicode в чистом виде сдерживается по той причине, что если код одного символа будет занимать не один байт, а два байта, что для хранения текста понадобится вдвое больше дискового пространства, а для его передачи по каналам связи – вдвое больше времени.
Поэтому сейчас на практике больше распространено представление Юникода UTF-8 (Unicode Transformation Format). UTF-8 обеспечивает наилучшую совместимость с системами, использующими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байтов. В целом, так как самые распространенные в мире символы – символы латинского алфавита — в UTF-8 по-прежнему занимают 1 байт, такое кодирование экономичнее, чем чистый Юникод.
В кодируемом английском тексте используется только 26 букв латинского алфавита и еще 6 знаков пунктуации. В этом случае текст, содержащий 1000 символов можно гарантированно сжать без потерь информации до размера:
Словарь Эллочки – «людоедки» (персонаж романа «Двенадцать стульев») составляет 30 слов. Сколько бит достаточно, чтобы закодировать весь словарный запас Эллочки? Варианты: 8, 5, 3, 1.











