Задания для самостоятельного выполнения
Цель: изучить понятие информации, три уровня рассмотрения информации, способы определения количества информации на этих уровнях; единицы измерения количества информации.
Теоретическая часть
Понятие информации можно рассматривать при различных ограничениях, накладываемых на ее свойства, т. е. при различных уровнях рассмотрения. В основном выделяют три уровня – синтаксический, семантический и прагматический. Соответственно на каждом из них для определения количества информации применяют различные оценки.
На синтаксическом уровне для оценки количества информации используют вероятностные методы, которые принимают во внимание только вероятностные свойства информации и не учитывают другие (смысловое содержание, полезность, актуальность и т. д.).
Разработанные в середине XX в. математические и, в частности, вероятностные методы позволили сформировать подход к оценке количества информации как к мере уменьшения неопределенности знаний. Такой подход, называемый также вероятностным, постулирует принцип: если некоторое сообщение приводит к уменьшению неопределенности наших знаний, то можно утверждать, что такое сообщение содержит информацию. При этом сообщения содержат информацию о каких — либо событиях, которые могут реализоваться с различными вероятностями. Формулу для определения количества информации для событий с различными вероятностями и получаемых от дискретного источника информации предложил американский ученый К. Шеннон в 1948 г. Согласно этой формуле количество информации может быть определено следующим образом:
где I –количество информации; N –количество возможных событий (сообщений); pi –вероятность отдельных событий (сообщений); Σ – математический знак суммы чисел.
Определяемое с помощью формулы (1.1) количество информации принимает только положительное значение. Поскольку вероятность отдельных событий меньше единицы, то соответственно выражение log pi является отрицательной величиной и для получения положительного значения количества информации в формуле (1.1) перед знаком суммы стоит знак минус.
Если вероятность появления отдельных событий одинаковая, и они образуют полную группу событий, т. е.
то формула (1.1) преобразуется в формулу Р. Хартли:
В формулах (1.1) и (1.2) отношение между количеством информации и соответственно вероятностью, или количеством, отдельных событий выражается с помощью логарифма. Применение логарифмов в формулах (1.1) и (1.2) можно объяснить следующим образом. Для простоты рассуждений воспользуемся соотношением (1.2). Будем последовательно присваивать аргументу N значения, выбираемые, например, из ряда чисел: 1, 2, 4, 8, 16, 32, 64 и т. д. Чтобы определить, какое событие из N равновероятных событий произошло, для каждого числа ряда необходимо последовательно производить операции выбора из двух возможных событий.
Так, при N =1 количество операций будет равно 0 (вероятность события равна 1), при N =2, количество операций будет равно 1, при N =4 количество операций будет равно 2, при N =8, количество операций будет равно 3 и т. д. Таким образом получим следующий ряд чисел: 0, 1, 2, 3, 4, 5, 6 и т. д., который можно считать соответствующим значениям функции I в соотношении (1.2). Последовательность значений чисел, которые принимает аргумент N, представляет собой ряд, известный в математике как ряд чисел, образующих геометрическую прогрессию, а последовательность значений чисел, которые принимает функция I, будет являться рядом, образующим арифметическую прогрессию. Таким образом, логарифм в формулах (1.1) и (1.2) устанавливает соотношение между рядами, представляющими геометрическую и арифметическую прогрессии, что достаточно хорошо известно в математике.
В информатике, изучающей процессы получения, обработки, передачи и хранения информации с помощью вычислительных (компьютерных) систем, в основном используется двоичное кодирование, при котором используется знаковая система, состоящая из двух символов 0 и 1. По этой причине в формулах (1.1) и (1.2) в качестве основания логарифма используется цифра 2.
Исходя из вероятностного подхода к определению количества информации эти два символа двоичной знаковой системы можно рассматривать как два различных возможных события, поэтому за единицу количества информации принято такое количество информации, которое содержит сообщение, уменьшающее неопределенность знания в два раза (до получения событий их вероятность равна 0,5, после получения – 1, неопределенность уменьшается соответственно: 1/0,5 = 2, т. е. в 2 раза). Такая единица измерения информации называется битом (от англ. слова binary digit –двоичная цифра). Таким образом, в качестве меры для оценки количества информации на синтаксическом уровне, при условии двоичного кодирования, принят один бит.
Следующей по величине единицей измерения количества информации является байт, представляющий собой последовательность, составленную из восьми бит, т. е.
1 байт = 2 3 бит = 8 бит.
В информатике также широко используются кратные байту единицы измерения количества информации, однако в отличие от метрической системы мер, где в качестве множителей кратных единиц применяют коэффициент 10n, где п =3, 6, 9 и т. д., в кратных единицах измерения количества информации используется коэффициент 2n. Выбор этот объясняется тем, что компьютер в основном оперирует числами не в десятичной, а в двоичной системе счисления.
Кратные байту единицы измерения количества информации вводятся следующим образом:
1 Килобайт (Кбайт) = 2 10 байт = 1024 байт,
1 Мегабайт (Мбайт) = 2 10 Кбайт = 1024 Кбайт,
1 Гигабайт (Гбайт) = 2 10 Мбайт = 1024 Мбайт,
1 Терабайт (Тбайт) = 2 10 Гбайт = 1024 Гбайт,
1 Петабайт (Пбайт) = 2 10 Тбайт = 1024 Тбайт,
1 Экзабайт (Эбайт) = 2 10 Пбайт = 1024 Пбайт.
Единицы измерения количества информации, в названии которых есть приставки «кило», «мега» и т. д., с точки зрения теории измерений не являются корректными, поскольку эти приставки используются в метрической системе мер, в которой в качестве множителей кратных единиц используется коэффициент 10n, где п =3, 6, 9 и т. д. Для устранения этой некорректности международная организацией International Electrotechnical Commission, занимающаяся созданием стандартов для отрасли электронных технологий, утвердила ряд новых приставок для единиц измерения количества информации: киби (kibi), меби (mebi), гиби (gibi), теби (tebi), пети (peti), эксби (exbi). Однако пока используются старые обозначения единиц измерения количества информации, и требуется время, чтобы новые названия начали широко применяться.
Вероятностный подход используется и при определении количества информации, представленной с помощью знаковых систем. Если рассматривать символы алфавита как множество возможных сообщений N, то количество информации, которое несет один знак алфавита, можно определить по формуле (1.1). При равновероятном появлении каждого знака алфавита в тексте сообщения для определения количества информации можно воспользоваться формулой (1.2).
Количество информации, которое несет один знак алфавита, тем больше, чем больше знаков входит в этот алфавит. Количество знаков, входящих в алфавит, называется мощностью алфавита. Количество информации (информационный объем), содержащееся в сообщении, закодированном с помощью знаковой системы и содержащем определенное количество знаков (символов), определяется с помощью формулы:
где V – информационный объем сообщения; I = log2N, информационный объем одного символа (знака); К – количество символов (знаков) в сообщении; N –мощность алфавита (количество знаков в алфавите).
Определим, какое количество информации можно получить после реализации одного из шести событий. Вероятность первого события составляет 0,15; второго – 0,25; третьего – 0,2; четвертого – 0,12; пятого – 0,12; шестого – 0,1, т. е. Р1 =0,15; Р2 =0,25; Р3 = 0,2; Р4 =0,18; Р5 =0,12; Р6 =0,1.
Для определения количества информации применим формулу (1.1)
Для вычисления этого выражения, содержащего логарифмы, воспользуемся сначала компьютерным калькулятором, а затем табличным процессором Microsoft (MS) Excel, входящим в интегрированный пакет программ MS Office ХР.
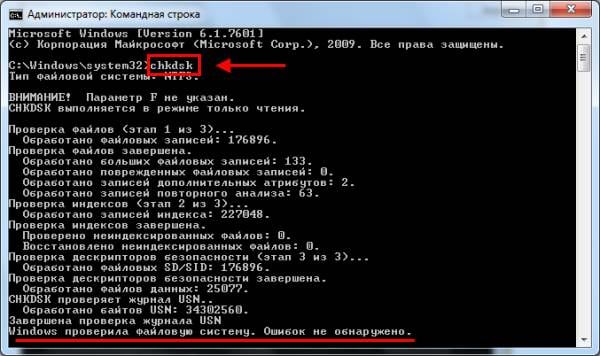
Для вычисления с помощью компьютерного калькулятора выполним следующие действия. С помощью команды: [Кнопка Пуск– Программы – Стандартные – Калькулятор] запустим программу Калькулятор. После запуска программы выполним команду: [Вид – Инженерный] (рис. 1.3).

Рис. 1.3. Инженерный калькулятор
Кнопка log калькулятора производит вычисление десятичного (по основанию 10) логарифма отображаемого числа. Поскольку в нашем случае необходимо производить вычисления логарифмов по основанию 2, а данный калькулятор не позволяет этого делать, то необходимо воспользоваться известной формулой:
В нашем случае соотношение примет вид: log2N = Mlog10N,
т. е log2N = 3,322 · log10N, и выражение для вычисления количества информации примет вид:
При вычислении на калькуляторе используем кнопки: +/‑ (изменение знака отображаемого числа), ()(открывающие и закрывающие скобки), log (логарифм числа по основанию 10) и т. д. Результат вычисления показан на рис. 1.3. Таким образом, количество информации I = 2,52 бит.
Воспользуемся теперь табличным процессором MS Excel. Для запуска программы Excel выполним команду: [Кнопка Пуск – Программы – MS Office ХР – Microsoft Excel].В ячейки А1, В1, С1, D1, E1, F1 открывшегося окна Excel запишем буквенные обозначения вероятностей Р1, Р2, P3, Р4, P5, P6 а в ячейку G1 – количество информации I, которое необходимо определить. Для написания нижних индексов у вероятностей Р1 ÷ P6 в ячейках А1, В1, С1, D1, E1, F1 выполним следующую команду: [Формат – Ячейки – Шрифт – Видоизменение (поставим флажок напротив нижнего индекса)]. В ячейки А2, В2, С2, D2, Е2, F2 запишем соответствующие значения вероятностей.
После записи значений в ячейки необходимо установить в них формат числа. Для этого необходимо выполнить следующую команду: [Формат – Ячейки – Число – Числовой (устанавливаем число десятичных знаков, равное двум)]. Устанавливаем в ячейке G2 тот же числовой формат. В ячейку G2 записываем выражение = – (A2*LOG(A2;2) + B2*LOG(B2;2) + C2*LOG(C2;2) + D2*LOG(D2;2) + E2*LOG(E2;2) + F2*LOG(F2;2) ). После нажатия на клавиатуре компьютера клавиши ,в ячейке G2 получим искомый результат – I =2,52 бит (рис. 1.4).

Рис. 1.4. Результат вычисления количества информации
Определим, какое количество байт и бит информации содержится в сообщении, если его объем составляет 0,25 Кбайта.
С помощью калькулятора определим количество байт и бит информации, которое содержится в данном сообщении:
I =0,25 Кбайт · 1024 байт/1 Кбайт = 256 байт;
I =256 байт · 8 бит/1 байт = 2048 бит.
Определим мощность алфавита, с помощью которого передано сообщение, содержащее 4096 символов, если информационный объем сообщения составляет 2 Кбайта.
С помощью калькулятора переведем информационный объем сообщения из килобайт в биты:
V = 2Кбайт 1024 байт/1 Кбайт = 2048 байт 8 бит/1 байт = 16384 бит.
Определим количество бит, приходящееся на один символ (информационный объем одного символа) в алфавите:
I = 16 384 бит/4096 = 4 бит.
Используя формулу (1.3), определим мощность алфавита (количество символов в алфавите) :
N = 2 I = 2 4 = 16.
На семантическом уровне информация рассматривается по ее содержанию, отражающему состояние отдельного объекта или системы в целом. При этом не учитывается ее полезность для получателя информации.
Данный подход предполагает, что для понимания (осмысливания) и использования полученной информации приемник (получатель) должен обладать априорной информацией (тезаурусом), т. е. определенным запасом знаков, наполненных смыслом, слов, понятий, названий явлений и объектов, между которыми установлены связи на смысловом уровне. Таким образом, если принять знания о данном объекте или явлении за тезаурус, то количество информации, содержащееся в новом сообщении о данном предмете, можно оценить по изменению индивидуального тезауруса под воздействием данного сообщения. В зависимости от соотношений между смысловым содержанием сообщения и тезаурусом пользователя изменяется количество семантической информации, при этом характер такой зависимости не поддается строгому математическому описанию и сводится к рассмотрению трех основных условий, при которых тезаурус пользователя:
• стремится к нулю, т. е. пользователь не воспринимает поступившее сообщение;
• стремится к бесконечности, т. е. пользователь досконально знает все об объекте или явлении и поступившее сообщение его не интересует;
• согласован со смысловым содержанием сообщения, т. е. поступившее сообщение понятно пользователю и несет новые сведения.
Два первых предельных случая соответствуют состоянию, при котором количество семантической информации, получаемое пользователем, минимально. Третий случай связан с получением максимального количества семантической информации. Таким образом, количество семантической информации, получаемой пользователем, является величиной относительной, поскольку одно и то же сообщение может иметь смысловое содержание для компетентного и быть бессмысленным для некомпетентного пользователя.
На прагматическом уровне информация рассматривается с точки зрения ее полезности (ценности) для достижения потребителем информации (человеком) поставленной практической цели. Данный подход при определении полезности информации основан на расчете приращения вероятности достижения цели до и после получения информации.
Количество информации, определяющее ее ценность (полезность), находится по формуле:
где Р0, P1 –вероятность достижения цели соответственно до и после получения информации.
В качестве единицы измерения (меры) количества информации, определяющей ее ценность, может быть принят 1 бит (при основании логарифма, равном 2), т. е. это такое количество полученной информации, при котором отношение вероятностей достижения цели равно 2.
Рассмотрим три случая, когда количество информации, определяющее ее ценность, равно нулю и когда она принимает положительное и отрицательное значение.
Количество информации равно нулю при Р0 = Р1, т.е. полученная информация не увеличивает и не уменьшает вероятность достижения цели.
Значение информации является положительной величиной при P1 > P0, т. е. полученная информация уменьшает исходную неопределенность и увеличивает вероятность достижения цели.
Значение информации является отрицательной величиной при P1 < P0, т. е. полученная информация увеличивает исходную неопределенность и уменьшает вероятность достижения цели. Такую информацию называют дезинформацией.
Задания для самостоятельного выполнения
1. По каналу связи передается пять сообщений, вероятность получения первого сообщения составляет 0,3; второго – 0,2; третьего – 0,14, а вероятности получения четвертого и пятого сообщений равны между собой. Какое количество информации мы получим после приема одного из сообщений?
2. Совершаются два события. При каких вероятностях этих событий мы получим минимальное и максимальное количество информации?
3. Какое количество информации несет в себе сообщение о том, что нужная вам компьютерная программа находится на одной из семи дискет?
4. С помощью компьютерного калькулятора заполнить пропуски числами:
а) 2 Кбайт = ___ байт = ___ бит;
б) ___ Гбайт = 2357 Мбайт = ___ Кбайт;
в) ___ Кбайт = ___ байт = 14567 бит;
г) 3 Гбайт = __ Мбайт = ___ Кбайт;
д) ___ Тбайт = 8 Гбайт = ___ Мбайт.
5. Определить информационную емкость буквы в русском и латинском алфавитах.
6. Сколько символов содержит сообщение, если его информационный объем составляет 1,25 Кбайта и мощность алфавита, с помощью которого записано сообщение, равна 32?
7. Опытный пользователь компьютера может вводить в минуту 110 знаков. Мощность алфавита, используемого в компьютере, равна 256. Какое количество информации в байтах может ввести пользователь в компьютер за 1 и 1,5 минуты?
8. Определить количество информации, определяющее ее ценность, если вероятность достижения цели до получения информации равна 0,5, а после получения информации – 0,3.
Перечень документов по охране труда. Сроки хранения: Итак, перечень документов по охране труда выглядит следующим образом.
Группы красителей для волос: В индустрии красоты колористами все красители для волос принято разделять на четыре группы.
пользователь компьютера, хорошо владеющий навыками ввода информации с клавиатуры, может вводить в минуту 100 знаков. какое кол-во информации может ввести пользователь в компьятер за одну минуту в кодировку виндоус? кодировку юникод?
С клавиатуры вводят строку, состоящую из латинских букв и цифр. Написать программу, которая вычисляет сумму цифр, попадающихся в этой строке, а также выводящую строку после исключения из неё этих цифр. Для паскаль abc.
Дан одномерный целочисленный массив В состоящий из 16 элементов найти максимальный элемент массива и его порядковый номер.
Написать программу вычисления стоимости покупки с учётом скидки: скидка в 10% предоставляется, если сумма покупки >1000 руб.
Главная » Информатика » пользователь компьютера, хорошо владеющий навыками ввода информации с клавиатуры, может вводить в минуту 100 знаков. какое кол-во информации может ввести пользователь в компьятер за одну минуту в кодировку виндоус? кодировку юникод?
IР-адресу 64.129.255.32 соответствует 32-битовое представление:
Переводим числа из 10-ой системы счисления в двоичную и добавляем слева нули, чтобы было 8 разрядов:
6410 = 010000002
12910 = 100000012
25510 = 111111112
3210 = 001000002
A) Пушкин | Лермонтов | поэзия
Б) Пушкин | Лермонтов | поэзия | проза
B) Пушкин | Лермонтов |
Г) Пушкин & Лермонтов & проза
0 ответы
- около 18 часов назад
- 1
- 19 дней назад
- 1
- 21 день назад
- 1
- 28 дней назад
- 0
- 28 дней назад
- 0
- Информатика /
- 10 — 11 классы
- 29 дней назад
- 0
- 29 дней назад
- 1
- 29 дней назад
- 1
- Информатика /
- 10 — 11 классы