Импорт файлов CSV и Excel в приложение
Когда приложение создано и запущено, периодически возникает необходимость импортировать информацию в его базу данных из файлов. Конечно, базы будут пополняться и автоматически — за счет информации, которую добавляют пользователи или предоставляют интегрированные сервисы. Но настройки импорта распространенных форматов CSV, XLS или XLSX лучше добавить заранее — скорее всего, они вам пригодятся и существенно упростят работу в будущем.
Сегодня расскажем о настройке импорта на no-code платформе AppMaster.io в двух вариантах:
- Статический: когда порядок столбцов в загружаемых таблицах постоянный.
- Динамический: когда порядок столбцов в таблицах меняется.
В конце статьи — видео с примерами и объяснением всех этапов настройки.
Разработка такого функционала мало чем отличается от классического программирования, но с помощью визуальных инструментов вы сделаете это гораздо быстрее. Для этого нужно выполнить 5 простых шагов:
- Подготовить тестовые образцы файлов для импорта: неважно, в каком расширении, настройка для CSV и форматов Excel будет выглядеть одинаково.
- Настроить пользовательский бизнес-процесс с помощью стандартных блоков, которые предоставляет редактор — дополнительные модули загружать не нужно.
- Создать новый эндпоинт для бизнес-процесса — чтобы реализовать функционал загрузки импортируемого файла в веб-приложении.
- Добавить на страницу веб-приложения форму, которая будет загружать CSV и Excel файлы и сообщать об успешном импорте или выводить сообщение об ошибке.
- Протестировать функционал с помощью тестовых файлов — чтобы убедиться, что все работает корректно.
Если у вас уже есть опыт работы с AppMaster.io или другими no-code платформами, то настройка вряд ли займет больше часа, даже с учетом просмотра обучающего видео.
Многие из них представляют собой аналоги функций классического программирования — только в виде визуальных инструментов, работать с которыми вы будете по принципу drag&drop.
Приведем список основных блоков для настройки импорта с их кратким описанием.
* Кроме них, вам также могут понадобиться различные вспомогательные блоки: если при обработке значений из файла нужно, например, перевести данные из одного формата в другой, сохранить переменную для дальнейшей обработки, объединить или разделить строки.
В этом случае не нужно указывать названия столбцов, но их порядок должен быть неизменным во всех загружаемых файлах — иначе программа некорректно импортирует данные.
- Start — стандартный блок, который будет принимать импортируемый файл для чтения (после добавления в него соответствующей переменной).
- Read CSV File, Read XLS File или Read XLSX File — читает загруженный файл строка за строкой.
- For each loop — цикл, который будет перебирать все столбцы в каждой строке для последующей обработки их значений.
- Switch — для разделения потока: чтобы настроить различный параметры обработки значений, полученных из импортированного файла, на основании их индексов.
- Блоки Make и Create из группы Model Functions — для той модели данных, которую вы будете использовать при создании и сохранении объектов из импортированного файла; и в которую, соответственно, будете добавлять полученные на предыдущих этапах значения.
- End — стандартный блок, завершающий бизнес-процесс после того, как все данные успешно импортированы в базу вашего приложения.
В этом случае столбцы в загружаемых файлах могут располагаться в любом порядке, однако их названия всегда должны быть одинаковыми, чтобы импорт прошел успешно.
Для настройки динамического импорта нужно добавить блоки анализа первой строки таблицы — чтобы определить, какие именно данные содержатся в каждом из столбцов загружаемого файла.
- Equal — оператор сравнения, который определит, является ли обрабатываемая строка первой.
- If-Else — который примет значение из Equal и перенаправит поток в зависимости от этого.
- Дополнительный блок For each loop — цикл, который будет работать только с первой строкой (то есть с названиями столбцов).
- Append Array — сохранит все значения, полученные из первой строки файла, в массив.
- Array Element — получит значения конкретных элементов из Append Array вместе с их индексами из For each loop (того, который обрабатывает все строки).
- Также нужно изменить блок Switch — чтобы он перенаправлял поток и обрабатывал импортируемые данные в зависимости от значений, полученных из Array Element.
При добавлении эндпоинта выберите метод POST, пропишите URL и укажите созданный бизнес-процесс — минимальная настройка завершена. Дополнительную информацию о том, как определить права доступа для групп пользователей или с разных IP, можно найти в документации к платформе (EN и RU версии).
Для корректной работы формы импорта нужно выбрать Create Record при ее создании и указать созданный эндпоинт, а также добавить кнопку подтверждения формы (триггер — onClick, действие — Submit form).
В этом видео подробно описаны все шаги по настройке статического и динамического импорта на примере CSV файла.
Хотите напрямую пообщаться с нашими разработчиками и другими ноукодерами? Присоединяйтесь к сообществу Appmaster.io в Telegram. Будем рады ответить на ваши вопросы!
Экспорт
Выберите действие «Экспорт CSV», после чего система отобразит окно выбора колонок для экспорта.
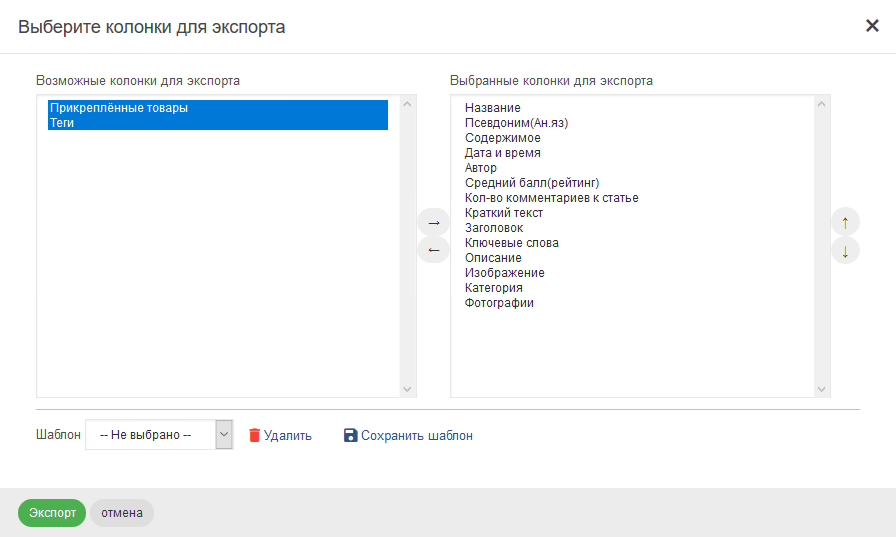
Слева в окне располагается список возможных для экспорта колонок. Справа располагается список выбранных колонок, которые попадут в CSV файл. Порядок колонок задается с помощью кнопок со стрелками «вверх» и «вниз». С помощью кнопок со стрелками «влево» и «вправо» можно перемещать колонки между списками.
В нижней части окна располагаются инструменты для работы с шаблонами экспорта. Выбранные колонки для экспорта можно сохранить в шаблон с указанным названием. Позже, можно использовать данный шаблон, для быстрой установки колонок экспорта.
Сохраненные шаблоны отображаются в выпадающем списке слева. Сразу после выбора требуемого названия шаблона, соответствующие колонки будут помещены в список выбранных.
При нажатии на кнопку «Удалить» будет удален выбранный в настоящий момент шаблон.
После формирования необходимых колонок для экспорта, в нижней части страницы следует нажать на кнопку «экспорт». Браузер предложит сохранить или открыть CSV-файл. Данный файл можно открыть для редактирования в MS Excel.
Экспортный файл, формируемый платформой ReadyScript, является эталоном CSV файла для импорта. Это удобно использовать, чтобы понять в каком формате нужно предоставить системе CSV файл для импорта того или иного объекта. То есть достаточно создать один необходимый объект (например, товар, статью, пункт меню и т.д.) в панели администрирования и произвести его экспорт, чтобы получить требуемый эталон CSV.
Заметки В CSV файле первая строка всегда будет содержать список названий колонок.
Стандартный механизм экспорта экспортирует абсолютно все объекты выбранного типа.
Glpi импорт компьютеров csv
Network and Classroom Management Thread, Anyone know how to bulk import into glpi in Technical; I have just had a horrible thought. I have been using GLPI exclusively as our hardware inventory. I have now .
LinkBack
Thread Tools
Search Thread
Join Date Apr 2008 Location In the vast area of space and time Posts 1,557 Thank Post 522 Thanked 56 Times in 50 Posts Rep Power 45
Импорт данных из CSV файла в AD
Процесс импорта данных заключается в
- Импортирование CSV файла через
$ListContacts = Import-Csv .contacts.csv -Delimiter «;»
- Проверка и не создавался ли такой контакт ранее:
if ($Contact.Mail -eq $ExistContact.WindowsEmailAddress)
- Непосредственное создание контакта
New-MailContact -Name $Contact.Name -DisplayName $Contact.Name -LastName $io -FirstName $fio[0] -Alias $MailNickName -OrganizationalUnit «<Domain name>/<OU Name>» -ExternalEmailAddress $Contact.Mail
- Установка значений атрибутов, которые нет возможности указать при создании контакта:
Set-Contact -Identity $newcontact.Identity -Company $Contact.Company -Title $Contact.Title -Phone $contact.OfficePhone
Безошибочный импорт файлов CSV с использованием Pandas DataFrame

25.05.2021 | Алексей Семериков, г. Нижний Новгород | 0
EmptyDataError… Звучит знакомо? В этой статье рассмотрим несколько советов, дабы избежать ошибок при загрузке файлов CSV с помощью Pandas DataFrame.
Данные находятся в центре конвейера машинного обучения. Чтобы использовать полную мощность алгоритма, данные должны быть сначала правильно очищены и обработаны.
Первый шаг очистки/обработки данных — загрузка файла и последующее установление соединения по пути к файлу. Существуют файлы с различными типами разделителей:
- разделители-табуляция;
- разделители-запятые;
- разделители из нескольких символов и другие.
Импорт файла в фрейм данных Pandas часто вызывает ошибки. Например, EmptyDataError говорит о том, что нет столбцов для синтаксического анализа из файла. Возникает ошибка в основном из-за того, что:
- неверно указан путь к файлу;
- неверно указаны типы разделителей данных;
- неверно указан каталог файлов;
- файловое соединение не установлено.
Специалисты по обработке данных не могут позволить себе тратить много времени на трудоемкий этап. Поэтому при загрузке файла необходимо выполнять определенные шаги, которые позволят сэкономить время и избавят от хлопот, связанных с просмотром большого количества информации, чтобы найти решение вашей конкретной проблемы.
Чтение и импорт файла CSV не так прост, как можно предположить. Вот несколько советов, которые помогут загрузить файл данных для построения модели машинного обучения.
- Проверьте свой тип разделения в настройках.
Для Windows
- Зайдите в Панель управления;
- Нажмите на региональные и языковые параметры;
- Перейдите на вкладку «Региональные параметры»;
- Нажмите Настроить/Дополнительные настройки;
- Введите запятую в поле «Разделитель списка» (,);
- Дважды нажмите «ОК», чтобы подтвердить изменение.
Примечание: работает, только если «десятичный символ» также не является запятой.
Для MacOS
- Зайдите в Системные настройки;
- Щелкните «Язык и регион», а затем перейдите к параметру «Дополнительно»;
- Измените «Десятичный разделитель» на один из следующих сценариев: если десятичным разделителем является точка, то разделителем CSV будет запятая, если десятичным разделителем является запятая, то разделителем CSV будет точка с запятой.
2. Воспользуйтесь предварительным просмотром данных (в блокноте Jupyter, либо в Microsoft Excel) для проверки способа разделения данных.
3. Правильно укажите все аргументы.
От правильности заполнения аргументов функции pd.read_csv напрямую зависит правильность чтения вашего CSV файла. Рассмотрим список всех аргументов:

Нас больше всего интересует следующий аргумент: sep — определяет тип разделения между значениями данных. По умолчанию ‘,’. Наиболее распространенные типы разделителей: запятая, табуляция и двоеточие. Следовательно, они должны быть указаны, как sep = ‘,’, sep = », sep = ‘;’ соответственно. Это сообщит pandas DataFrame, как распределять данные по столбцам.
Если после корректного указания аргументов проблема не устранена, воспользуемся следующим пунктом.
4. Проверьте путь к файлу.
Местоположение файла должно быть указано правильно. Чаще всего люди не знают рабочий каталог и в конечном итоге указывают неправильный путь к файлу. В этом случае мы должны проверить рабочий каталог, чтобы убедиться, что указанный путь к файлу написан правильно. Напишите приведенный ниже код, чтобы проверить рабочий каталог.
Мы также можем изменить рабочий каталог, используя приведенную ниже строку кода. После указания нового каталога мы должны указать путь.
5. Отметьте разделитель, используемый для указания местоположения файла.
Часто ошибка возникает и при изменении рабочего каталога. Это происходит из-за того, что разделитель не написан в соответствии с правильным синтаксисом.

Прежде всего проверьте разделитель, используя команду ниже.
Затем используйте разделитель только в начале расположения каталога, а не в конце. Пожалуйста, обратите внимание, что эта спецификация синтаксиса разделителя (/) верна для MacOS и может быть неверна для Windows.
Если ваш файл находится в рабочем каталоге, упомяните только имя файла, как показано ниже.
Но если ваш файл находится в какой-либо другой папке, вы можете указать следующие папки после рабочего каталога, например, ваш рабочий каталог — «/Users/username», а ваш файл находится в папке с именем «files» в «документах», тогда используйте следующий код:
6. Убедитесь, что файл находится по пути:
Теперь проверьте, присутствует ли ваш файл по описанному пути, используя приведенный ниже код. Мы получим ответ либо «True», либо «False».
7. Распечатайте данные файла для перекрестной проверки:
Теперь мы можем проверить, правильно ли загружен наш файл данных, используя приведенный ниже код.

Эти советы помогут вам больше не сталкиваться с проблемами при загрузке файла CSV с помощью Pandas DataFrame.
Вспомогательные функции импорта
Центральной функцией является I2W_Parse, которая разбирает переданную строку и помещает значения полей в массив. Функция возвращает код успеха, ошибки или номер поля, тип данных которого не соответствует спецификации. Спецификация передается массивом, где параметры каждого поля задаются массивом из четырех элементов: имя, тип данных, размер и признак обязательного заполнения. Т.е. структура спецификации — это массив массивов. Преобразование данных полей из строк к нужному типу осуществляется функциями: I2W_Str2Date, I2W_Str2Num, I2W_Str2Int, I2W_Str2Cur.
Так как строковое поле может быть обрамлено в двойные кавычки и содержать в себе символ разделитель (в нашем случае «;»), для разбиения исходной строки из файла мы используем свою функцию I2W_Split вместо стандартной Split.
Для обращения к полям по имени, а не индексу в массиве значений, используется функция I2W_FieldByName.
Вспомогательная процедура I2W_Log используется для записи информации о ходе процесса в лог системы.
Функция I2W_GetID находит в базе данных объект по заданному значению поля и возвращает его идентификатор. Поиск по строковым полям осуществляется без учета регистра символов, концевых и начальных пробелов. Если объект не найден, то он создается и его поля инициализируются переданными значениями.
Подробные комментарии для каждой функции приведены непосредственно в исходном коде: