Собираем семантическое ядро с помощью Key Collector
Здравствуйте друзья! Раз Вы зашли на эту страницу, то наверняка у Вас есть потребность собрать семантическое ядро максимально полно и при этом потратить минимум времени и энергии.
Для этого я предлагаю воспользоваться замечательной программой и практически на полном автомате произвести составление семантического ядра Key Collector — многофунциональной программой, незаменимой для seo оптимизаторов и директологов.
Для тех кто не в теме, и не знает что такое семантическое ядро сайта рекомендую прочитать мою статью Оружие стратега или способ оптимизации и Вам все станет ясно.
Общая настройка Кей Коллектора
Для работы с вордстатом понадобиться: здесь все просто, нужно отдельно зарегистрировать яндекс почту и создать там тестовую рекламную кампанию, можно с одним объявлением, можно просто черновую (без прохождения модерации и пополнения бюджета). В программе просто прописываем логин и пароль от почты и все работает.
Для работы с гугл планером понадобиться: зарегистрировать новый аккаунт в гугл адвордс. В обязательном порядке скачать последнюю версию браузера internet explorer и зайдя исключительно через данный браузер, также создать тестовую рекламную кампанию (без бюджета и активности). Главное заполнить все настройки пользователя — указать язык и местоположение. Фокус заключается в том, что без данных манипуляций, использовать гугл планер не получиться.
Переходим непосредственно к настройкам:

Заходим в настройки программы во вкладку Яндекс Вордстат», где выставляем следующие параметры:
— глубина парсинга — 0. Выставляя такое значение, вы будите получать обычный парсинг, но программа может автоматом парсить и в глубину, т.е. спарсив ключевые слова, она может парсить то, что уже спарсила, разбивая ключевые слова на более конкретные ключевые слова. Смысла глубокого парсинга нет, так как система будет парсить дубли, а не уникальные ключевые слова, и даже без глубокого парсинга мы все равно будем по нему показываться, так как используем основную маску. Если просто — глубокий парсинг делать не надо, выставляем значение ноль.
— парсить страницы, здесь выставляем стандартное значение — 40.
— добавлять в таблицу фразы с частотами от 1 до 99999999999. Здесь вы указываете какую частотность вы хотите видеть с парсенных ключевых слов. Есть директологи, которые не парсят все доскональна, а работают с ключевыми словами, которые имеют частотность от 10 и выше. Я же советую вам парсить все и начинать с 1. При таком подходе у вас будет самое полное семантическое ядро, а если вы решите, что такие ключевые слова вам не нужно, то уже после парсинга, можно при помощи фильтра выделить такие ключи и удалить.
— не снимать частоты для фраз меньше или равной 0. Логика проста, нам не нужно пустые ключевые слова, которые не будут приносить трафик, поэтому такие не ищем.
— количество потоков. Если вы используете одну почту от яндекс директа, то можете смело выставлять сразу 2 потока, и таким образом программа будет работать в два раза быстрее. И если вы не используете прокси сервера, то не убираем галочку «Использовать основной IP адрес».

Далее заходим во вкладку «Яндекс Директ», где указываем адреса свои электронных почт от яндекса и пароли от них. Достаточно указать 1-2 почты.

Во вкладке «Гугл Адвордс» указываем доступы от гугл адвордс (что логично).
Собственно, это все стандартные настройки, после которых заработает кей коллектор.
Настройка Кей Коллектора
После того, как вы оплатили лицензию с помощью Вебмани, вам придет подробная и простая инструкция по установке Key Collector. Не буду тут дублировать данную информацию.
Лучше приступим непосредственно к запуску и настройке программы Key Collector.
Окно программы состоит из верхней, нижней, боковой панели, а также основного поля, где отображаются собранные ключевые слова.
Верхняя панель инструментов:
![]()
Нижняя панель состояния:

Бокова панель управления группами:

Основное поле сбора:

Для начала работы нам необходимо зайти в настройки в верхней панели слева.

Первым делом, в настройках необходимо указать зарегистрированные вами аккаунты в тех сервисах, которые вы собираетесь использовать.
Например, для Яндекс Директа (основной источник сбора информации):

Указываете логин и через двоеточие пароль: к примеру, pro.wp:1234. Можно указать два или больше аккаунтов, тогда в случае блокировки одного, будет задействован второй. Не рекомендуется использовать больше 3-х.
Аккаунт может быть вычеркнуть системой, а соответственно информация не будет обрабатываться по причине слишком маленьких промежутков между запросами.
![]()
Для Яндекс Директа у меня проставлены такие значение:
Пока проблем не наблюдалось. Соответственно, если сократить временные диапазоны между обращениями к системе, результаты будут обрабатываться быстрее, но это может привести к блокировке аккаунта.
Обратите также внимание на остальные закладки настроек, кроме «Парсинга» это «Сеть», «Интерфейс», «Антикапча», «KEI».
В разделе «Сеть» вы можете задать значения прокси-серверов, если вы их используете для работы с программой.
В «Интерфейс» в Key Collector можно настроить отображения столбцов и заголовков таблиц, особенности экспорта файлов в Excel.
На вкладке «KEI» вы можете задать любые значения, которые вам нужно просчитать посредством вами заданных формул Kei в Кей Коллекторе. Например, просчет конкурентности запроса: сумма главных страниц с данным ключевым словом и заголовков других страниц с этим словом в Яндексе или Гугле.

Когда вы подкорректировали все настройки, можно приступать к работе с Кей Коллектор.
Очистка семантики от «мусора»
Во-первых, найдите «мусорные» ключи и избавьтесь от них – с большой разницей между базовой частотностью и точной (в кавычках).
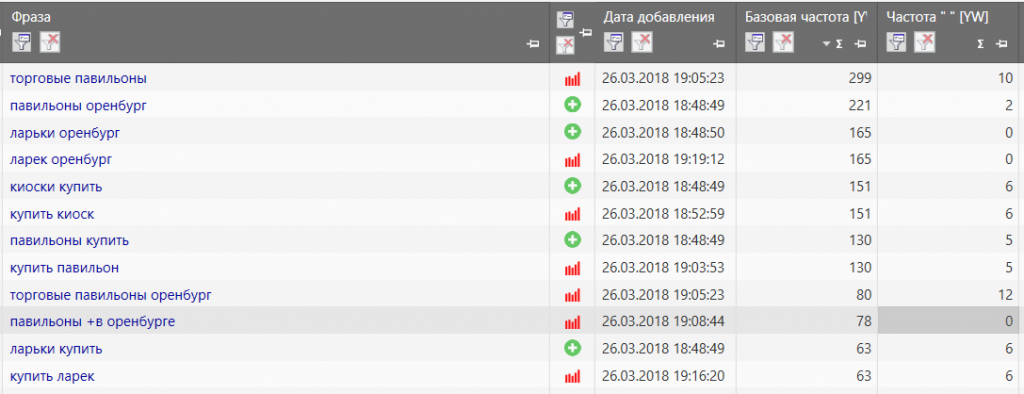
Допустим, если базовая частота превышает 30, а точная близка к 0, смотрите, насколько адекватные это фразы, насколько они подходят под вашу тематику. В большинстве случаев они не приведут на сайт целевой трафик.
Во-вторых, стоит избавиться от неявных дублей – фраз, которые включают одинаковые наборы слов, но в разном порядке. Они между собой не конкурируют, но увеличивают время на создание объявлений.
Настройте их удаление следующим образом: перейдите на вкладку «Данные», кликните «Удаление неявных дублей» и затем – «Выполнить умную групповую отметку» и «Удалить отмеченное».
В-третьих, в Key Collector можно составлять списки минус-слов, чтобы программа их сразу же отфильтровывала в выдаче результатов. Нажмите значок «Стоп-слова», скопируйте или загрузите список в такое окно и примените при сборе семантики из Вордстата, как показано ниже.
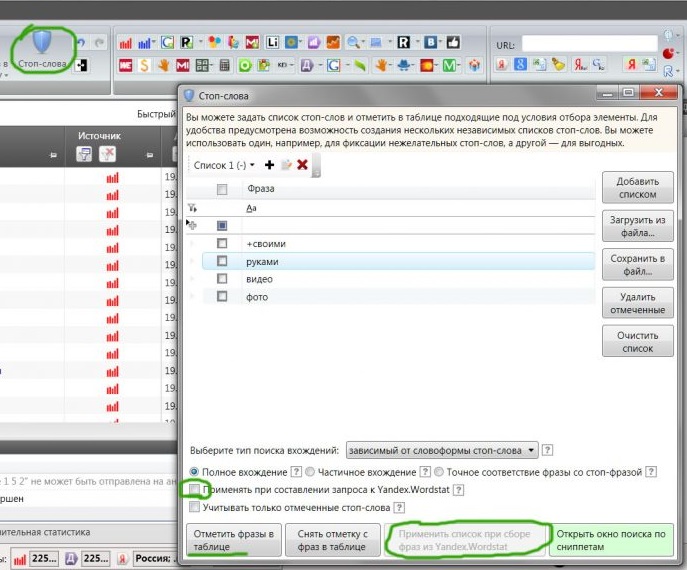
Чтобы заминусовать ключ из результатов Key Collector, выделите его галочкой и нажмите «Добавить в стоп-слова».
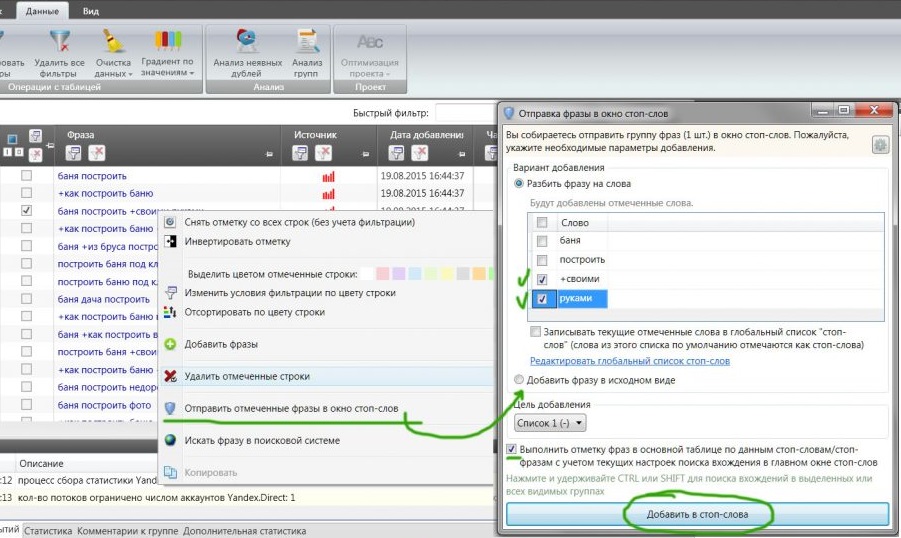
Однако даже за вычетом минус-слов собранная семантика еще недостаточно «чистая», чтобы применять её для запуска рекламы. Посмотрим, какие еще инструменты Key Collector могут быть полезными.
Преимущества сервиса от Моаб очевидны:
— Глубина парсинга на площадке достаточно большая. Дополнительно, есть вариант выбора длины хвоста.
— Скорость выполнения исследования достаточно высокая. Для сравнения обычная обработка запроса «ОКНА» занимает 14 часов, а при использовании ресурса процесс заканчивается за 5 часов и приносит даже большее количество результатов.
— берёте пакет ПРО за 4999 рублей, а получаете почти бесконечный боезапас, полноценный Key Collector и огромное количество бонусов.
— Никакие капчи, прокси и прочие проблемы подборки вас не беспокоят. Просто нажимаете кнопку и получаете результат.
— 500 000 фраз — это объем, на википедию, не говоря уж о простых ресурсах.
Большой полюс в MOAB Tools — качество подбора фраз. Попробуйте в действии все функции на тарифе Free и убедитесь в возможностях сами. Лучше один раз потрогать, чем сто раз услышать.
Определяем уровень конкуренции
Отличной возможность программы KeyCollector является парсинг данных о количестве найденных проиндексированных страниц по каждому поисковому запросу, число сайтов в ТОП-10, которые содержат эту ключевую фразу в заголовке страницы Title, а также сколько страниц из первой десятке по этим запросам являются главными страницами.
Понятно, что чем больше проиндексированных страниц, оптимизированных заголовков и главных страниц в выдаче, тем сложнее с ними будет конкурировать.
Однако очень часто бывает ситуация, когда хорошие высокочастотные запросы имеют сравнительно небольшой уровень конкуренции. Поэтому очень важно проанализировать все собранные ключевые запросы на уровень конкуренции для того, чтобы выбрать и продвигаться по самым выгодным и еще незанятым ключам.
Для этого кликаем на иконку «KEI» и выбираем «Получить данные для ПС Яндекс».
Можно, конечно, уточнять уровень конкуренции и в других поисковых системах, это зависит от задания на продвижение, но в большинстве случаев Яндекса хватает, чтобы получить объективную картину сложности продвижения того или иного запроса.
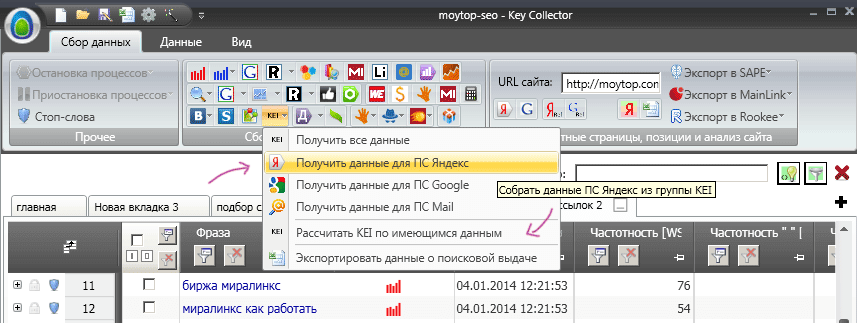
Конечно, этот уровень определения конкуренции несовершенен. Было бы просто идеально, чтобы программа умела также парсить по каждому запросу:
- Средний тИЦ и PR сайтов в ТОП-10.
- Средний объем страниц.
- Среднее количество внешних ссылок на конкурента и т.п.
В этом случае результат был бы точнее.
Но как показывает практика даже такого «беглого» анализа конкуренции достаточно для того, чтобы успешно находить выгодные ключи и быстро по ним продвигаться, так как многие оптимизаторы его не проводят вовсе и в итоге многие сайты продвигаются по сложным конкурентным запросам, хотя рядом «лежат» запросы с не меньшей частотой и с полным отсутствием оптимизированных конкурентов.
После парсинга данных, остается только рассчитать индекс уровеня конкуренции (KEI) по определенной формуле, которая обычно индивидуальна у каждого оптимизатора. Вы можете использовать свои наработки или воспользоваться моими. Я их привожу в статье «Как рассчитать формулу KEI».
Чтобы сделать расчет добавьте формулу в настройки программы и просто нажмите «Рассчитать KEI по имеющимся данным».
Семантическое ядро готово. Его можно экспортировать в формат Microsoft Excel (*.xls) и немного отредактировать полученные данные. Самые выгодные ключи можно выделить другим цветом. Вот, например, что получилось у меня:
Как я уже говорил, KeyCollector — платная программа, цена около 1500 RUB. Но программа того стоит
Отбивается она за неделю работы.

Вы можете даже разместить свой аккаунт на Kwork.ru, дать объявления и собирать ключи за деньги.
Или же наоборот, можете просто заказывать сбор ключей у тамошних специалистов по 500 руб. и экономить время, если заказов немеряно.
Но мне кажется, что лучше один раз заплатить, освоить KeyCollector самому и зарабатывать на нем, хотя бы и на том же Кворке или на Weblancer.net (тут заработки раза в 3 выше, но и биржа платная).
P.S. Хотите узнать, как у меня получилось настроить сервис для съема позиций в поиске — так, чтобы он работал бесплатно? Тогда читайте статью по ссылке.
Сбор данных SERP
Включаем фильтр группы «Частота “!”», оставляем фразы больше 4 — в итоге в группе остается 448 фраз:

Включаем сбор данных по SERP:

Программа собирает данные ТОП-20 в Яндекс по каждой фразе. Параметры сбора этого инструмента выставляются в общих настройках:

В результате сбора в программе по каждой фразе с частотой «!» от 5 и выше будет список сайтов, которые находятся в ТОП-20. Кей Коллектор автоматически сведет данные на уровне доменов, чтобы можно было увидеть сайт и количество фраз, по которым он в ТОП.
Выводы
Мы разобрали базовые настройки Key Collector (то, без чего невозможно начать работать). Также мы рассмотрели самые простые (и основные) примеры использования программы. И подобрали простенькое семантическое ядро, используя статистику Яндекс.Вордстат и Google AdWords.
Как вы понимаете, в статье показано примерно 20% от всех возможностей программы. Чтобы освоить Key Collector, нужно потратить несколько часов и изучить официальный мануал. Но оно того стоит.
Если после этой статьи вы решили, что проще заказать семантическое ядро у специалистов, чем разбираться самому, напишите мне через страницу Контакты, и мы обсудим детали.
И бонусное видео: чувак по имени Derek Brown виртуозно играет на саксофоне. Я даже побывал на его концерте во время джаз-фестиваля, это реально круто.
Статус-панель

Статус-панель
Панель показывает, сколько результатов (ключевых фраз) найдено на данный момент, сколько отмечено галочкой строк. Далее показывается, включена ли антикапча и сколько баланса на счету осталось. Следом вы можете задать регион для сбора статистики в Водрдстате, Директе, ПС Яндекс (для определения позиций) и Гугле. При их нажатии появляются дополнительные окна, но там все просто и писать о них не стану.
Не забывайте указывать регион при необходимости, иначе вы рискуете собрать бесполезные ключевые фразы и статистику!
Если нажать черную круговую стрелочку, то произойдет принудительное обновление всех данных в таблице, т.е. данные были собраны, но не выводились в таблицу сразу, поэтому их надо принудительно синхронизировать с активной таблицей проекта.
Зеленые разнонаправленные стрелки показывают, что программа работает и происходит сбор данных, т.е. идут обращение к сети.
На этом изучение интерфейса и основных его функций можно считать законченным. В следующий раз будем беседовать об алгоритме сбора семантического ядра.











