Руководства по Windows Machine Learning
Использовать Windows Machine Learning может быть полезно во многих решениях настраиваемых приложений. Здесь мы перечислим несколько подробных руководств, в которых показано, как создавать модели машинного обучения из разнообразных служб, в том числе программных и не использующих код, а также интегрировать эти модели в простое приложение Windows ML. Кроме того, мы описали несколько более сложных методов, которые позволяют настроить функциональность приложения. Если же вам нужны только вводные данные об использовании API с существующей моделью или готовые примеры, см. ссылки ниже.
В этих руководствах описано, как создать модель машинного обучения и интегрировать ее в приложение Windows 10 с помощью Windows ML.
Учебная среда без использования кода
Хотите применить существующие служебные программы для обучения модели машинного обучения? В этих руководствах описано, как создавать приложения Windows ML с использованием моделей, обученных в других существующих службах.
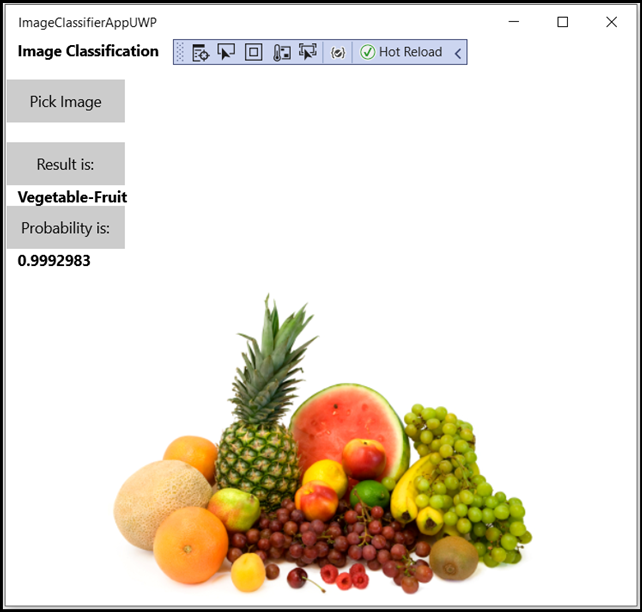
Узнайте, как с помощью службы Пользовательского визуального распознавания Azure обучить модель для классификации изображений и развернуть ее в приложении Windows ML для локального выполнения на компьютере.
Узнайте, как с помощью расширения ML.NET Model Builder для Visual Studio создать модель ONNX и развернуть ее в приложении Windows ML для локального выполнения на компьютере.
Учебная среда с использованием кода
В этих руководствах описано, как создать собственный код для обучения модели Windows ML вместо использования существующий службы.
Узнайте, как установить PyTorch на локальном компьютере для обучения модели классификации изображений, как преобразовать эту модель в формат ONNX и развернуть ее в приложении Windows ML для локального выполнения на компьютере.
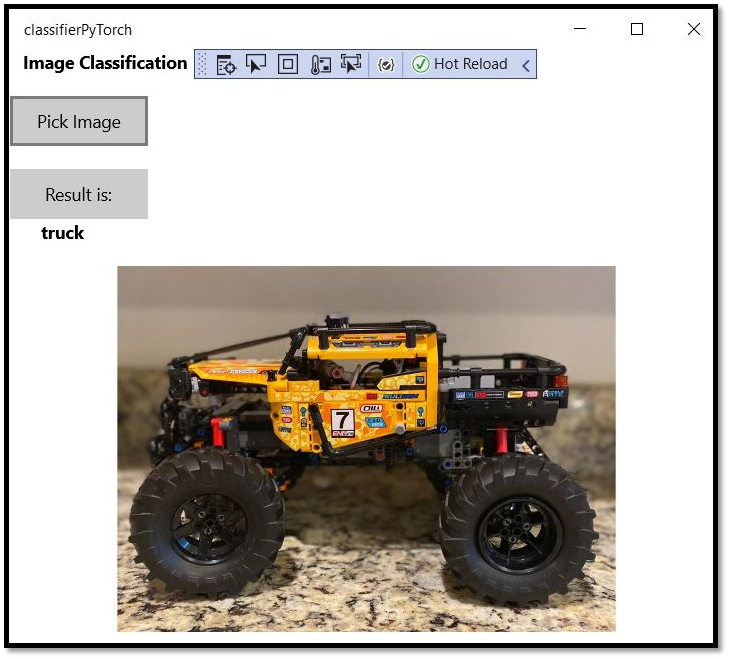
Узнайте, как установить PyTorch на локальном компьютере для обучения модели анализа данных, как преобразовать эту модель в формат ONNX и развернуть ее в приложении Машинного обучения Windows для локального выполнения на компьютере.
Узнайте, как установить TensorFlow на локальном компьютере, как реализовать обучение переносом с использованием архитектуры YOLO, как преобразовать модель в формат ONNX и развернуть ее в приложении Windows ML для локального выполнения на компьютере.
Мини-компьютер от Intel наделит любой PC возможностями машинного обучения
Нейронные сети, машинное обучение, компьютерное зрение и прочие технологии являются одним из главных современных трендов в мире IT. Компания Intel, являясь одним из лидеров рынка, представила Movidius Neural Compute Stick — первый в мире набор средств для глубокого обучения и автономный ускоритель искусственного интеллекта в виде миниатюрного компьютера. Он выполнен в форм-факторе обычной флешки, но при этом позволяет существенно упростить жизнь разработчикам приложений на базе искусственного интеллекта.
Intel Movidius Neural Compute Stick предназначен для разработчиков и исследователей, позволяя уменьшить все преграды при создании, настройке и развёртывании приложений искусственного интеллекта путём предоставления специализированной высокоэффективной обработки глубоких нейронных сетей.

Разработчики могут использовать сразу несколько таких компьютеров, объединяя их в массив и повышая тем самым общую производительность. Сам девайс потребляет менее 1 Вт энергии, а его заявленная производительность достигает 100 Гфлопс. Важно отметить, что Intel Movidius Neural Compute Stick не является автономным устройством. Он подключается к обычному компьютеру по USB 3.0, увеличивая его производительность при нейронных вычислениях и наделяя возможностями машинного обучения.
Суперкомпьютер для искусственного интеллекта
Самые успешные технологические компании регулярно пытаются сделать искусственный интеллект умнее. Google и Facebook проводили эксперименты, используя миллиарды фотографий и тысячи мощных процессоров. Однако в прошлом году правительственный проект превзошел масштаб любой лаборатории ИИ, пишет IKSMEDIA.
В рамках проекта исследования климата на суперкомпьютере запустили эксперимент по машинному обучению. Самый мощный суперкомпьютер в мире Summit, занимающий площадь, эквивалентную двум теннисным кортам, задействовал в этом проекте более 27 тысяч мощных графических процессоров. Он использовал их мощность для работы алгоритмов глубокого обучения.
Проект фокусировался на одной из самых важных мировых проблем: изменении климата. Технологические компании обучают алгоритмы распознавать лица или дорожные знаки, а правительственные ученые – погодные условия вроде циклонов по климатическим моделям, которые умещают столетние прогнозы атмосферы Земли в три часа.
Проект важен как для будущего ИИ, так и климатологии. Он демонстрирует научный потенциал применения глубокого обучения к суперкомпьютерам, которые традиционно моделируют физические и химические процессы. Он также показывает, что мы можем достичь большего на высоких вычислительных мощностях.
У суперкомпьютеров вроде Summit особая архитектура: тысячи их процессоров объединены в систему, которая может работать как одно целое. До недавних пор мало кто стремился адаптировать машинное обучение к такой мощной аппаратуре. Адаптация ПО TensorFlow под масштабы Summit поможет Google расширить свои внутренние ИИ-системы. Инженеры из Nvidia также принимали участие в проекте. Благодаря им десятки тысяч процессоров машины работали без сбоев.
Проект показывает, как ИИ в широких масштабах может улучшить наше понимание будущих погодных условий. Когда исследователи генерируют столетние предсказания погоды, интерпретация полученного прогноза становится сложной задачей. Обычно для автоматизации этого процесса используется программное обеспечение, но оно не совершенно. Результаты Summit показали, что машинное обучение может делать это намного лучше, что должно помочь в прогнозировании наводнений и других природных катастроф.
По прогнозу Frost & Sullivan, к 2022 году объем мирового рынка технологий ИИ увеличится до $52,5 млрд при ежегодных темпах роста 31%. Основные направления инвестиций – платформы машинного обучения и компьютерного зрения, приложения машинного обучения, а также роботы, виртуальные помощники и распознавание видеоизображений.
Опросы Forrester свидетельствуют, что в мире более половины компаний уже внедрили или расширяют внедрение ИИ и еще 20% планируют реализовать эти технологии в течение ближайшего года. В России, по информации «АйПи Лаборатории», чаще всего искусственный интеллект применяют для бизнес-аналитики и других подобных задач в сфере B2B. В число наиболее популярных областей использования ИИ также входят компьютерное зрение, системы здравоохранения и различные NLP-системы обработки естественного языка — от распознавания голоса до чат-ботов.
По прогнозам аналитиков, к 2025 г. свыше 86% предприятий и организаций в мире станут применять в своей работе ИИ, а 80% данных будут реально использоваться, а не просто храниться в архивах. ИИ проникнет во все сферы деятельности любого крупного предприятия. Это позволит увеличить прибыль благодаря предиктивной аналитике и выявлению тенденций, повысить продуктивность и уровень информационной безопасности за счет глубокого анализа данных, улучшить качество обслуживания клиентов и, наконец, высвободить сотрудников для решения задач более высокого уровня. Поэтому предприятия изучают возможности извлечения ценной информации из имеющихся данных, и это вызывает потребность в подходящих для подобных задач вычислительных мощностях.
Компьютер для программирования
-
Если сфера программирования не требует мощного железа. Например , вы разрабатываете небольшие веб-сайты на HTML, CSS, JavaScript, PHP. В этом случае вам не нужно использовать мощную и прожорливую IDE и вам вполне будет достаточно ч его -то типа «Notepad++» или «Sublime Text». Возможно , вы вообще сможете работать в онлайн-редакторах кода. Если же программировать что-то сложное, например , нейронные сети, мощные компьютерные игры, даже приложение на Android — со слабым компьютером будут возникать проблемы.
-
Если вам нравится, когда компьютер «тормозит». То ест ь п рограммировать можно на слабых компьютерах, но это будет ужасно медленно. Такую «скорость» работы не оценит ваш заказчик, да и вам такая «работа» надоест.
Стационарный компьютер или ноутбук для программирования — что лучше?
-
При одинаковой стоимости стационарный компьютер будет немного мощнее. Так сложилось, что ноутбуки ценятся за собственную мобильность, поэтому при одинаковых характеристиках ноутбук будет стоить немного дороже.
-
У ноутбуков сложно сделать апгрейд. Ноутбук покупается с определенными характеристиками , и редко какие производители ноутбуко в оставляют возможность их улучшить. У стационарных компьютеров все по-другому. Его можно собрать самостоятельно, а если купить «готовый сбор», тогда всегда будет возможность его улучшить.
-
Стационарный компьютер подойдет для тех, кто не любит «переезжать». Купить, установить, настроить и работать на одном месте и в одном положении. Если вас это устраивает, тогда стационарный компьютер для вас. Но нужно помнить, что программирование — скучная и однообразная работа. Когда уже немного п оработа ете программистом, у вас появится огромное желание часто менять положение тела и локацию работы. Такую возможность дает только ноутбук.
Компьютер для программирования: на что обращать внимание
-
Экран. Необходимо определиться с размером экрана. Маленький экран — это неудобство и постоянно напряженные глаза. Есть такое негласное правило: чем больше экран, тем легче на нем работать. Иногда программисты используют 2 экрана на устройстве, чтобы во время работы не переключаться. Подключить второй экран можно даже к ноутбуку.
-
Разрешение экрана. Разрешение экрана влияет на качество транслируемой картинки , п оэтому важно использовать FullHD и обязательно с матовой матрицей. В этом случае вы получите матовую качественную картинку , а ваши глаза не будут так сильно уставать.
-
Клавиатура. Это основной «инструмент» программиста, так как при помощи клавиатуры он вводит программный код. Клавиатура должна иметь небольшой ход клавиш и работать максимально тихо. Другой атрибут комфортной работы на клавиатуре — это раскладка и наличие подсветки.
-
Оперативная память. Это важнейший критерий выбора , как и процессор, о котором речь пойдет чуть ниже. Тут все просто : чем больше — тем лучше. Уровень оперативной памяти зависит от сферы программирования. Чем требовательней ваша сфера, тем больше нужно оперативки. Чтобы комфортно работать, нужно 16 Гб и больше. Минимум для программирования — это 8 Гб , х отя заниматься веб-программированием можно даже с 4 Гб.
-
Процессор. Процессор характеризуется частотой и ядрами. Принцип тот же — чем больше частота на каждом отдельном ядре, тем лучше. А также чем больше ядер, тем лучше. Можно ли программировать на двух ъ ядерном компьютере? Можно, но лучше на 4 ядрах и выше. Есть одна тонкость — наличие потоков в ядрах , п оэтому даже если компьютер будет двух ъ ядерным, то важно , чтобы на каждом ядре было минимум по 2 потока. Таким образом , 2 ядра по 2 потока даст 4 потока — это лучше , чем просто 2 ядра. Один поток — это одна «очередь» из команд, которые будет обрабатывать процессор. Соответственно, если будет больше потоков, тогда компьютер будет быстрее работать. Обычно одно ядро — это один поток , п оэтому есть нюанс : 2 ядра по 2 потока в каждом будут работать медленнее , чем 4 ядра по одному потоку.
-
Объем жесткой памяти. Тут есть два вида памяти: HDD и SDD. SDD обычно не такие емкие, как HDD, но они работают быстрее и стабильнее, поэтому выбор лучше остановить на них. А вообще , объем памяти жесткого диска — это дело индивидуальное , т о ест ь к ому сколько нужно.
Компьютер для программирования: операционная система
Еще одна дилемма: MacOS, Linux или Windows? На самом деле , принципиальной разницы нет. Выбор зависит от предпочтений и финансовых возможностей программиста. Если есть свободные средства, тогда можно приобрести Макбук или лицензию для операционной системы Windows. Если нет свободных средств, тогда можно использовать любой бесплатный дистрибутив Линукс.
Раньше выбор операционной системы был важен, так как основное программистское программное обеспечение было «заточено» под Виндовс , н а МакОС и Линуксе с программами были проблемы. Сейчас все совсем по-другому. Практически любую программистскую программу можно инсталлировать на каждую из популярных операционных систем.
Поэтому выбор операционной системы — это дело личное , и существенных ограничений или привилегий нет ни в одной операционной системе. Единственное , о чем нужно сказать , — MacOS поставляется вместе с устройствами компании Apple. Цены у таких устройств немного выше , чем у аналог ов от других компаний при похожи х характеристиках.
Nvidia vs Intel: чья платформа быстрее для машинного обучения? [обновлено]

Так называемый «бенчмаркетинг», когда производительность в тестах становится одним из инструментов рекламы, в т.ч. недобросовестной, практикуют не только производители смартфонов. Позавчера Nvidia опубликовала статью, в которой раскритиковала заявление Intel о том, что её новые (поколения Knights Landing) сопроцессоры Xeon Phi превосходят графические ускорители. Согласно Intel, четыре сопроцессора Xeon Phi в сети AlexNet обучаются в 2.3 раза быстрее четырех видеокарт, а их масштабируемость (повышение производительности по мере увеличения количества устройств в системе) в сети GoogleNet лучше на 38%.
На это Nvidia язвительно заметила, что технологии глубокого обучения быстро меняется, «поэтому понятно, что новички могут не знать обо всех наработках, имевших место в аппаратном и программном обеспечении«. Согласно компании, в более свежей версии AlexNet четыре видеокарты Titan X (Maxwell) обучаются на 30% быстрее четырех Xeon Phi, а четыре более современных Titan X (Pascal) — на 90%:
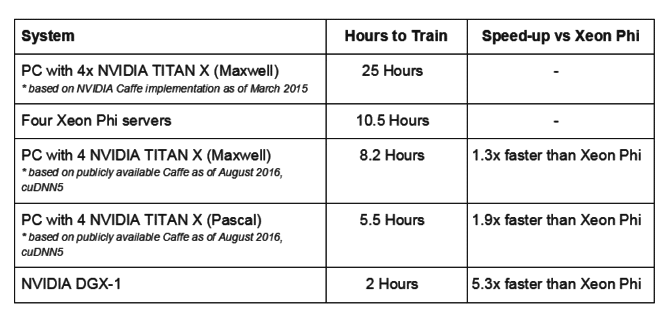
Как видно из таблицы, огромную роль в скорости обучения играет программное обеспечение — в марте 2015 обучение компьютера с четырьмя видеокартами Titan X (Maxwell) заняло 25 часов, а полтора года спустя, в августе 2016, в полтора раза меньше времени — 10.5 часов. Intel в своих данных о производительности четырех неназванных видеокарт Maxwell (как утверждает Nvidia — Titan X) указывает как раз 25 часов, и следовательно опирается на устаревшие данные.
Что касается масштабируемости, то согласно примечаниям самой Intel, сервер из 32 новейших Xeon Phi 7250 сравнивался с сервером из 32 Tesla K20X (ноябрь 2012), показав 87% эффективность новейших сопроцессоров Intel против 63% видеокарт Nvidia 4-летней давности. Сославшись на данные китайского поисковика Baidu, Nvidia утверждает, что на 128 видеокартах с архитектурой Maxwell (конкретные модели не называются) масштабируемость является почти линейной:
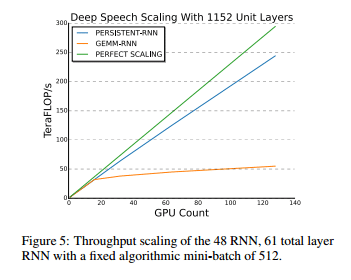
Примечательно, что Nvidia при этом не раскрывает подробных характеристик систем, на которых были получены эти результаты (включая конкретную модель тестируемого Xeon Phi). Будем надеяться, что по умолчанию использовалась та же Xeon Phi 7250, что была в тестах Intel, но с учетом по меньшей мере двух случаев не вполне добросовестного «бенчмаркетинга» Nvidia, я допускаю, что Nvidia могла запустить свой тест и на самой младшей модели, Xeon Phi 7210.

Любопытно также, что с профессиональными, специально созданными в т.ч. для задач машинного обучения, сопроцессорами Xeon Phi, Nvidia сравнивает игровые видеокарты Titan X, а не предназначенную для аналогичных целей Tesla P100, анонсированную в апреле этого года. Точнее говоря, Nvidia её сравнивает, но в рамках сервера Nvidia DGX-1, оснащенного восемью Tesla P100. Последний на днях был торжественно передан (см. фото сверху) OpenAI — некоммерческому проекту, который занимается исследованиями в области искусственного интеллекта. Я надеюсь безвозмездно, потому что стоит этот сервер $129 тысяч. Согласно Nvidia, по скорости обучения (2 ч) он в 5.3 раз превосходит четыре сервера, оснащенных по одному Xeon Phi (10.5 ч). Напомню, что компьютер из четырех видеокарт Titan X (Pascal) быстрее четырех Xeon Phi почти в 2 раза, на 90% (5.5 ч), а из четырех Titan X (Maxwell) — на 30% (8.2 ч).
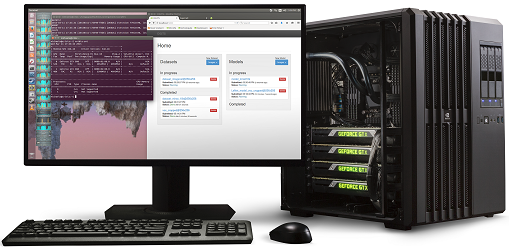
И тут возникает интересный вопрос о цене достижения 5.3-кратного преимущества на сервере Nvidia DGX-1 — оно обойдется в $129 тысяч, тогда как компьютер Digits DevBox, оснащенный четырьмя видеокартами Titan X (Maxwell) стоит $15 тысяч. Получаем 2 часа обучения AlexNet за $129 тысяч ($64.5 тысяч за час) на DGX-1 и 8.2 часа — за $15 тысяч ($1.8 тысяч за час) на Digits DevBox.
Что касается Xeon Phi 7250, то оснащенный одним таким сопроцессором ($4,876) сервер по оценкам Intel будет стоить $7.3 тысяч, соответственно четыре сервера — $29.2 тысячи. При времени обучения 10.5 часов это дает $2.8 тысяч за час. Это вполне соразмерная с Digits DevBox сумма, тогда как себестоимость машинного обучения на Nvidia DGX-1 представляется просто заоблачной.
ОБНОВЛЕНИЕ
В ответной публикации Intel заявила, что «споры вокруг публично доступных бенчмарков производительности — потеря времени. Intel традиционно основывает свои утверждения на публично доступной на то время информации, и мы придерживаемся своих данных«. Компания также отметила тот красноречивый факт, что по её оценкам процессоры Intel установлены на 97% серверов, используемых для машинного обучения.
Правительственный суперкомпьютер США бьет рекорды
В рекордном проекте участвовал самый мощный в мире суперкомпьютер Summit, находящийся в Национальной лаборатории Ок-Ридж. Эта машина получила корону в июне прошлого года, вернув США титул спустя пять лет, когда список возглавлял Китай. В рамках проекта исследования климата гигантский компьютер запустил эксперимент по машинному обучению, который протекал быстрее, чем когда-либо прежде.
«Саммит», занимающий площадь, эквивалентную двум теннисным кортам, задействовал в этом проекте более 27 000 мощных графических процессоров. Он использовал их мощность для обучения алгоритмов глубокого обучения, той самой технологии, которая лежит в основе передового искусственного интеллекта. В процессе глубокого обучения алгоритмы выполняют упражнения со скоростью миллиард миллиардов операций в секунду, известной в суперкомпьютерных кругах как экзафлоп.
«Ранее глубокое обучение никогда не достигало такого уровня производительности», говорит Прабхат, руководитель исследовательской группы в Национальном научно-вычислительном центре энергетических исследований в Национальной лаборатории имени Лоуренса в Беркли. Его группа сотрудничала с исследователями в штаб-квартире «Саммита», Национальной лаборатории Ок-Ридж.
Как можно догадаться, тренировка ИИ самого мощного в мире компьютера была сосредоточена на одной из самых больших проблем в мире — изменении климата. Технологические компании обучают алгоритмы распознавать лица или дорожные знаки; правительственные ученые обучили их распознавать погодные условия вроде циклонов по климатическим моделям, которые сжимают столетние прогнозы атмосферы Земли в три часа. (Непонятно, правда, сколько энергии затребовал проект и как много углерода было выброшено в воздух в этом процессе).

Эксперимент Summit имеет значение для будущего искусственного интеллекта и климатологии. Проект демонстрирует научный потенциал адаптации глубокого обучения к суперкомпьютерам, которые традиционно моделируют физические и химические процессы, такие как ядерные взрывы, черные дыры или новые материалы. Это также показывает, что машинное обучение может извлечь выгоду из большей вычислительной мощности — если вы сможете ее найти — и обеспечить прорывы в будущем.
«Мы не знали, что это можно сделать в таком масштабе, пока не сделали это», говорит Раджат Монга, технический директор Google. Он и другие «гугловцы» помогали проекту, адаптировав программное обеспечение машинного обучения TensorFlow с открытым исходным кодом компании для гигантских масштабов Summit.
Большая часть работы по масштабированию глубокого обучения проводилась в центрах обработки данных интернет-компаний, где серверы работают совместно над проблемами, разделяя их, потому что расположены относительно разобщенно, а не связаны в один гигантский компьютер. Суперкомпьютеры же вроде Summit имеют другую архитектуру со специализированными высокоскоростными соединениями, связывающими их тысячи процессоров в единую систему, которая может работать как единое целое. До недавнего времени проводилось относительно мало работ по адаптации машинного обучения для работы с такого рода аппаратными средствами.
Монга говорит, что работа по адаптации TensorFlow к масштабам Summit также будет способствовать усилиям Google по расширению ее внутренних систем искусственного интеллекта. Инженеры Nvidia также поучаствовали в этом проекте, убедившись, что десятки тысяч графических процессоров Nvidia в этой машине работают без сбоев.
Поиск путей использования большей вычислительной мощности в алгоритмах глубокого обучения сыграл важную роль в текущем развитии технологии. Та же технология, которую использует Siri для распознавания голоса и автомобили Waymo для считывания дорожных знаков, стала полезной в 2012 году после того, когда ученые адаптировали ее для работы на графических процессорах Nvidia.

В анализе, опубликованном в мае прошлого года, ученые из OpenAI, исследовательского института в Сан-Франциско, основанного Илоном Маском, подсчитали, что объем вычислительной мощности в крупнейших публичных экспериментах с машинным обучением удваивается примерно каждые 3,43 месяца с 2012 года; это будет означать 11-кратное увеличение за год. Такая прогрессия помогла бота из Alphabet победить чемпионов в сложных настольных и видеоиграх, а также способствовала значительному повышению точности переводчика Google.
Google и другие компании в настоящее время создают новые виды микросхем, адаптированных под ИИ, чтобы продолжить эту тенденцию. Google заявляет, что «стручки» с тесно расположенными тысячами ее чипов ИИ — дублированные тензорные процессоры, или TPU — могут обеспечивать 100 петафлопс вычислительной мощности, что составляет одну десятую от скорости, достигнутой Summit.
Вклад проекта Summit в науку о климате показывает, как ИИ гигантского масштаба может улучшить наше понимание будущих погодных условий. Когда исследователи генерируют столетние предсказания погоды, чтение полученного прогноза становится сложной задачей. «Представьте, что у вас есть фильм на YouTube, который идет 100 лет. Нет никакой возможности найти всех кошек и собак в этом фильме вручную», говорит Прабхат. Обычно для автоматизации этого процесса используется программное обеспечение, однако оно не совершенно. Результаты «Саммита» показали, что машинное обучение может делать это намного лучше, что должно помочь в прогнозировании штормовых воздействий вроде наводнений.
По словам Майкла Причарда, профессора Калифорнийского университета в Ирвайне, запуск глубокого обучения на суперкомпьютерах — это относительно новая идея, которая появилась в удобное время для исследователей климата. Замедление темпов усовершенствования традиционных процессоров привело к тому, что инженеры стали оснащать суперкомпьютеры растущим числом графических чипов, чтобы производительность росла более стабильно. «Наступил момент, когда больше нельзя наращивать вычислительную мощность обычным способом», говорит Причард.
Этот сдвиг завел традиционное моделирование в тупик, а значит пришлось адаптироваться. Также это открывает дверь для использования силы глубокого обучения, которое естественным образом подходит для графических чипов. Возможно, мы получим более четкое представление о будущем нашего климата.
А как бы использовали такой суперкомпьютер вы? Расскажите в нашем чате в Телеграме.