Краткое объяснение кодирования текстовой информации. Информатика
Кодирование текстовой информации — очень распространенное явление. Один и тот же текст может быть закодирован в нескольких форматах. Принято считать, что кодирование текстовой информации появилось с приходом компьютеров. Это и так и не так одновременно. Кодировка в том виде, в котором мы ее знаем, действительно к нам пришла с приходом компьютеров. Но над самим процессом кодирования люди бьются уже много сотен лет. Ведь, по большому счету, сама письменность уже является способом закодировать человеческую речь, для ее дальнейшего использования. Вот и получается, что любая окружающая нас информация никогда не бывает представленной в чистом виде, потому что она уже каким-то образом закодирована. Но сейчас не об этом.
Самый распространенный способ кодирования текстовой информации — это ее двоичное представление, которое сплошь и рядом используется в каждом компьютере, роботе, станке и т. д. Все кодируется в виде слов в двоичном представлении.
Сама технология двоичного представления информации зародилась еще задолго до появления первых компьютеров. Среди первых устройств, которые использовали двоичный метод кодирования, был аппарат Бодо — телеграфный аппарат, который кодировал информацию в 5 битах в двоичном представлении. Суть кодировки заключалась в простой последовательности электрических импульсов:
- 0 — импульс отсутствует;
- 1 — импульс присутствует.
В компьютерный мир такая кодировка пришла вместе с персонализацией самих компьютеров. То есть в первых компьютерах не было такой кодировки. Но как только компьютеры стали уходить «в массы», то резко обнаружилась потребность обрабатывать компьютерами большое количество именно текстовой информации, которую нужно было как-то кодировать. Тенденция обрабатывать большое количество текстовой информации сохранилась и в современных устройствах.
Так получилось, что двоичное кодирование в компьютерах связано только с двумя символами «0» и «1», которые выстраиваются в определенной логической последовательности. А сам язык подобной кодировки стал называться машинным.
Какие бывают символы?

В роли символов для компьютера выступают не только русские, английские и другие буквы, но и еще знаки препинания, а также другие знаки. Даже пробел, которым мы разделяем слова при печатании на компьютере, устройство воспринимает как символ. Чем-то очень напоминает высшую математику, ведь там, по мнению многих профессоров, ноль имеет двойное значение: он и является числом, и одновременно ничего не обозначает. Даже для философов вопрос пробела в тексте может стать актуальной проблемой. Шутка, конечно, но, как говорится, в каждой шутке есть доля правды.
Кодирование информации числовых и текстовых данных
Сравнение символов (их сопоставление), которое лежит в основе кодирования, выполняется над каждым элементом. Метод, применяемый для кодировки, фактически имеет невысокую значимость. Самый основной момент, который стоит выделить в качестве основного — уникальность единично взятого кода и размер самого шифра (кода).
Для процедуры шифрования используются таблицы. Важно, чтобы при кодировке и декодировании данных применялись одни и те же таблицы. В них занесены символы, выстроенные в определенном порядке, а также обратная процедура.
Сложно разобраться самому?
Попробуй обратиться за помощью к преподавателям
Чаще всего используются такие формы таблиц:
Используя одну таблицу для перекодирования, можно преобразовать 256 символов как максимальное количество. Такое число получается потому, что код размером в 8 бит занимает 1 байт памяти компьютера. Данная система является общепринятой. Таким образом, при преобразовании информации нужно учитывать факт того, что комбинируя варианты из единиц и нулей при размере 8 бит, можно получить 256 комбинаций. При использовании кода другой длиной, данное число поменяется. Например, код в два байта позволит шифровать 65536 символов.
Общий момент кодирования числовых и текстовых данных заключается в том, что при сравнении чисел используются различный код для каждого элемента. В отличие от символьной (текстовой) информации, в преобразовании числовых данных используются не только процедуры сравнения. Для того, чтобы представить числа в конечном виде, применяются арифметические действия вычитания, сложения, умножения и т.д. В работе обычной электронной вычислительной машины кодирование происходит при помощи двоичной позиционной системы счисления. В ней представлена схема шифрования информации на основе арифметических операций.
Кодирование текстовой информации происходит путем присваивания каждому элементу соответствующего значения. В двоичной системе оно определяется в интервале от 00000000 до 11111111. Если рассматривать кодирование в десятичной системе, данный интервал будет соответствовать числовому ряду от 0 до 255.
В кодировании символьной информации на русском языке используется пять форм таблиц. Это КОИ — 8, ISO, СР1251, СР866 и Мас. Кодирование и декодирование должно происходить по одной и той же таблице.
Стандарты кодирования звука
Звуки, которые слышит человек, представляют собой колебания воздуха. Звуковые колебания – это процесс распространения волн.
Звук имеет две основные характеристики:
- амплитуда колебаний – определяет громкость звука;
- частота колебания — определяет тональность звука.
Звук можно преобразовать в электрический сигнал, с помощью микрофона. Звук кодируется с определенным, заранее заданным интервалом времени. В этом случае измеряется размер электрического сигнала и присваивается бинарная величина. Чем чаще делают данные измерения, тем выше качество звука.

Компакт-диск объемом 700 Мб, вмещает порядка 80 минут звука CD-качества.
Базовые понятия
Прежде чем разобраться с основами процедуры кодирования, следует ознакомиться с несколькими простейшими понятиями.
Код – это набор любых символов или других визуальных обозначений информации, который образует представление данных. В компьютерной технике под кодом подразумевают отдельную систему знаков, которые используют для обработки, передачи и хранения сообщений и файлов.
Кодирование – это процесс преобразования текстовой информации в код. Кодов существует огромное количество. Каждый из них отличается своим алгоритмом работы и алфавитом.
К примеру, компьютер, смартфон, ноутбук и любые другие компьютерные устройства работают с двоичным кодом.
Двоичный код использует алфавит, который состоит из двух символов – «0» и «1» .
Декодирование – это процедура обратная к кодированию. Декодировщик обратно превращает код в понятную для человека форму представления данных. Среди известных примеров постоянной работы с декодированием можно отметить азбуку Морзе: для «прочтения» сообщения нужно сначала преобразовать полученный код в слова.
В компьютерной технике кодирование происходит, когда пользователь вводит любую информацию в систему – создает файлы, печатает текст и так далее.
Для понимания обычных букв кириллицы или латиницы они превращаются в набор нолей и единиц.
Чтобы отобразиться на экране компьютера, система проводит декодирование числовой последовательности и выводит результат на экран.
Все эти действия выполняются за тысячные доли секунды.
Визуальные коды
Язык жестов
Язык жестов — язык, состоящий из комбинации жестов, каждый из которых производится руками в сочетании с мимикой, формой или движением рта и губ, а также в сочетании с положением корпуса тела. Эти языки в основном используются в культуре глухих с целью коммуникации.
Общение жестами используется также людьми и без нарушения слуха, поскольку жест является неотъемлемым компонентом звуковых языков. Поэтому использование жестов, взамен голосового общения, может быть предпочтительно во многих ситуациях, где передавать информацию голосом или невозможно или представляет определенные трудности. Однако, такие системы жестов называть сформировавшимися языками жестов не представляется возможным из-за их примитивности.
Простейший язык жестов — профессиональный «язык» общения такелажников на расстоянии, словарь которого сводится к нескольким десяткам жестов типа майна («вниз, опускай») и вира («вверх, поднимай»). Еще примеры: передача сообщений спортсмену во время выступления, футболисту на поле; при необходимости соблюдения тишины: в театре, на концерте, на съемках, рядом с водопадом, во время сильного шторма на море; даже при незнании звуковых языков собеседников.
Необходимо отметить, что история мирового кинематографа началась с немого кино, где звуки не играли особой роли и большинство воспринимаемой информации, за исключением небольших текстовых вставок, шло с помощью мимики и движений актёров.
Жестовые языки почти полностью независимы от словесных и они продолжают развиваться: появляются новые жесты, отмирают старые — и чаще всего это мало связано с развитием словесных языков.
Часто за жестовые языки ошибочно принимается дактилирование букв (на самом деле используется в жестовых языках в основном для произнесения имён собственных, географических названий и т.п.)
Американский жестовый язык — амслен (ASL) имеет больше сходства с французским (LSF) и практически не имеет ничего общего с британским жестовым языком (BSL), хотя они и разделяют один и тот же звуковой язык — английский.
Первая сурдопедагогическая школа в России открылась в 1806 г; как и в США, работала по французской методике. В результате русский жестовый язык оказался в родстве с жестовым языком Америки.
С лингвистической точки зрения жестовые языки являются настолько же богатыми и непростыми, как и любой звуковой язык, несмотря на всеобщее отношение к ним как к «ненастоящим» языкам. Профессиональные лингвисты проводили исследования, в ходе которых было обнаружено, что жестовые языки обладают всеми компонентами, характеризующими их как полноценные языки.
Жесты условно-схематичны, иногда придумываются на лету, необязательно имеют визуальную связь с обозначаемым словом. Они обладают своей грамматикой, могут быть использованы для обсуждения самых различных тем: от простых и конкретных до возвышенных или абстрактных.
Слова жестовых языков, как и слова обычных языков, состоят из элементарных, не обладающих смыслом компонентов — хирем (аналогия в обычных языках — фонемы). Жест может состоять из 5 элементов (HOLME):
Уникальные свойства жестовых языков проистекают из возможности жестов обретать разные смыслы в зависимости от многих параметров, передаваемых одновременно, в отличие от обычных языков, где всё это происходит почти всегда последовательно. Структура жестового языка позволяет передавать параллельно несколько потоков информации — синхронность. Так, например, содержание «объект огромных размеров движется по мосту» может быть передано с помощью одного-единственного жеста.
По Стоуки хиремы делятся на три классса. Табы указывают на место исполнения жеста, дезы — на конфигурации руки, а сиги — на характер движения. Хиремы функционально эквивалентны фонемам, но в отличие от фонем, выстраивающихся в морфеме в линейную последовательность, в жесте-морфеме одновременно присутствует хирема каждого из трех классов. В ASL имеется 12 табов, 19 дезов и 24 сига, в шведском жестовом языке, соответственно, 18, 22 и 24, в языке глухих южной Франции — 16, 17 и 20 и т. д.
Возможны более сложные жесты: два деза, задействованы две руки; два сига, выполняются два движения и т.д.
В то время как для слова характерно обобщение, для жеста — конкретность. Отсутствие в жесте широкого обобщения, ограниченного изображением признака предмета и характера действия, видно из того, что например, нет единого жеста для передачи таких слов, как большой (большой дом, большая собака, большой заработок, большой человек) и идти, обозначающего движение, перемещение, отправление, наступление (человек идет, солдаты идут, весна идет, поезд идет, лед идет, письмо идет, деньги идут). Слова такого рода показываются разными жестами, конкретно и точно передающими признак, движение и т. п.
Образность. Жесты всегда образны. Например, при показе жеста дом кисти рук как бы рисуют крышу, книга — раскрывают страницы, любить — прикладываются к сердцу, дружить — складываются в рукопожатие. Мы не можем объяснить, почему стол называется столом, день — днем, хлеб — хлебом. Зато происхождение ручных знаков в подавляющем большинстве случаев можно легко проследить.
Существенным отличием жесто-мимической речи является ее аморфность. Речевой жест содержит понятие, но не выражает форму числа, рода, падежа, а также наклонения, времени и вида. В такой «натуральной мимике» словесное сообщение: «Я сегодня не была на работе, потому что тяжело заболел ребенок» будет выражено следующим набором жестов: «Я — работать — сегодня — быть — нет — почему — ребенок — больной — тяжело».
Из-за отсутствия в жестовом языке чёткой системы слышащим трудно его выучить, что приводит к уменьшению числа сурдопереводчиков. В настоящее время более соответствующей системой записи жестов признано их запись на видео, а не бумагу (причём, нередко с нескольких различных позиций). Вместе с тем, большого распространения системы записи жестовых языков не получили. Они используются для изучения жестовых языков, в то время как сами представители сообществ глухих их не используют.
Главная сложность состоит даже не в освоении жестов, а в том, чтобы научиться их «читать» с рук. Жесты бывают сложными — состоят из нескольких положений кисти, следующих друг за другом. И с непривычки сложно разделить окончание одного жеста и начало другого. Потому обучение занимает не меньше времени, чем изучение любого иностранного языка, а может — и больше.
Задание. Посмотреть видео «Beautiful» by Christina Aguilera. Какие жесты используются для обозначения слов: Я, нет, красивый, тяжело. I, not, hard, beautiful
Зачем кодировать информацию?
Во-первых, необходимо ответить на вопрос для чего кодировать информацию? Дело в том, что компьютер способен обрабатывать и хранить только лишь один вид представления данных – цифровой. Поэтому любую входящую в него информацию необходимо переводить в цифровой вид.
Чтобы все компьютеры могли однозначно понимать тот или иной текст, необходимо использовать общепринятые стандарты кодирования текста. В прочих случаях потребуется дополнительное перекодирование или несовместимость данных.

ASCII
Самым первым компьютерным стандартом кодирования символов стал ASCII (полное название — American Standart Code for Information Interchange). Для кодирования любого символа в нём использовали всего 7 бит. Как вы помните, что закодировать при помощи 7 бит можно лишь 27 символов или 128 символов. Этого достаточно, чтобы закодировать заглавные и прописные буквы латинского алфавита, арабские цифры, знаки препинания, а так же определенный набор специальных символов, к примеру, знак доллара — «$». Однако, чтобы закодировать символы алфавитов других народов (в том числе и символов русского алфавита) пришлось дополнять код до 8 бит (28=256 символов). При этом, для каждого языка использовалась свой отдельная кодировка.
UNICODE
Нужно было спасать положение в плане совместимости таблиц кодировки. Поэтому, со временем были разработаны новые обновлённые стандарты. В настоящее время наиболее популярной является кодировка под названием UNICODE. В ней каждый символ кодируется с помощью 2-х байт, что соответствует 216=62536 разным кодам.

Обработка звукового потока
Кодирование текстовой и звуковой информации, как и другие виды кодирования, имеет некоторые особенности. Речь сейчас пойдет о последнем процессе: кодировании звуковой информации.
Представление звукового потока (как и отдельного звука) может быть произведено при помощи двух способов.
Кодирование информации, применяемое в ЭВМ
1.Коды, применяемые в ЭВМ
Каким образом обрабатывается информация в компьютере и как обеспечить обмен информацией между пользователем и ЭВМ?
Процесс приема и передачи информации можно изобразить на схеме:

Кодирование – операция, связанная с переходом от исходной формы представления информации в форму, удобную для хранения, передачи или обработки.
Декодирование – связано с обратным переходом к исходному представлению информации.
В настоящее время существуют разные способы кодирования и декодирования информации в компьютере.
Выбор способа зависит от вида информации, которую необходимо кодировать: текст, число, графическое изображение и т.д.
ЭВМ может обрабатывать информацию, представленную только в числовой форме. Любая другая информация (текстовая, графическая) преобразуется в числовую информацию. Так, например, при вводе текста, каждый символ кодируется определенным числом (существуют специальные таблицы кодировки, наиболее известные и распространенные коды ASCII), а при выводе наоборот, каждому числу соответствует изображение определенного символа.
Восемь двоичных разрядов позволяют закодировать 2 8 =256 символов, этого достаточно, чтобы закодировать любую букву, цифру или служебный символ. Нажатие клавиши на клавиатуре приводит к тому, что сигнал посылается в компьютер в виде двоичного числа, которое хранится в кодовой таблице.
2. Кодовая таблица символов
Кодовая таблица символов — это внутреннее представление символов в компьютере. Во всем мире в качестве стандарта принята таблица ASCII (American Standart Code for Information Interchange) – Американский стандартный код для обмена информацией.
Первые 128 символов (от 0 до 127) – это цифры, прописные и строчные буквы латинского алфавита, управляющие символы. Вторая половина кодовой таблицы (от 128 до 255) предназначена для национальных символов (в том числе кириллицы), математических символов и так называемых псевдографических символов, которые используются для рисования рамок.
Нужно помнить о трех особенностях алфавита в кодовой таблице и их следствия:
1) прописные и строчные буквы представлены разными кодами, т.е. “А” и “а” – разные объекты;
2) при упорядочивании слов по алфавиту сравниваются между собой десятичные коды букв. Поэтому, чтобы избежать недоразумений, если не указано “нечувствителен к регистру”, используйте только латинский или русский алфавит и только прописные или только строчные первые буквы. Необходимо помнить, что любая цифра “меньше” любой буквы, код латинских букв “меньше” чем русских;
3) Многие латинские и русские буквы имеют визуально неразличимое начертание, но разные коды.
Итак, компьютер способен распознавать только значения бита. Однако он редко работает с конкретными битами в отдельности, а совокупность из 8 битов, воспринимаемая компьютером как единое целое, называется байтом.
Вся работа компьютера – это управление потоками байтов, которые устремляются в компьютер с клавиатуры или дисков (или по линии связи), преобразовываются по командам программ, запоминаются временно или записываются на постоянное хранение на магнитный диск, а также выводятся на экран дисплея или бумагу принтера в виде букв, цифр, значков.


3.Кодирование информации. Кодирование данных в ЭВМ
В ЭВМ применяется двоичная система счисления, т.е. все числа в компьютере представляются с помощью нулей и единиц, поэтому компьютер может обрабатывать только информацию, представленную в цифровой форме.
Для преобразования числовой, текстовой, графической, звуковой информации в цифровую необходимо применить кодирование.
Кодирование – это преобразование данных одного типа через данные другого типа. В ЭВМ применяется система двоичного кодирования, основанная на представлении данных последовательностью двух знаков: 1 и 0, которые называются двоичными цифрами (binary digit – сокращенно bit).
Целые числа кодируются двоичным кодом довольно просто (путем деления числа на два). Для кодирования нечисловой информации используется следующий алгоритм: все возможные значения кодируемой информации нумеруются и эти номера кодируются с помощью двоичного кода.
Кодирование чисел
Есть два основных формата представления чисел в памяти компьютера. Один из них используется для кодирования целых чисел, второй (так называемое представление числа в формате с плавающей точкой) используется для задания некоторого подмножества действительных чисел.
Кодирование целых чисел производиться через их представление в двоичной системе счисления: именно в этом виде они и помещаются в ячейке. Один бит отводиться при этом для представления знака числа (нулем кодируется знак «плюс», единицей – «минус»).
Для кодирования действительных чисел существует специальный формат чисел с плавающей запятой. Число при этом представляется в виде:
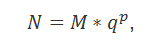
где M – мантисса, p – порядок числа N, q – основание системы счисления. Если при этом мантисса M удовлетворяет условию , то число N называют нормализованным.

Кодирование координат
Закодировать можно не только числа, но и другую информацию, например, о том, где находится некоторый объект. Величины, определяющие положение объекта в пространстве, называются координатами. В любой системе координат есть начало отсчёта, единица измерения, масштаб, направление отсчёта, или оси координат. Примеры систем координат – декартовы координаты, полярная система координат, шахматы, географические координаты.
Кодирование текста
Для представления текстовой информации используется таблица нумерации символов или таблица кодировки символов, в которой каждому символу соответствует целое число (порядковый номер). Восемь двоичных разрядов могут закодировать 256 различных символов.
Существующий стандарт ASCII (сокращение от American Standard Code for Information Intercange – американский стандартный код для обмена информацией; 8 – разрядная система кодирования) содержит две таблицы кодирования – базовую и расширенную. Первая таблица содержит 128 основных символов, в ней размещены коды символов английского алфавита, а во второй таблице кодирования содержатся 128 расширенных символов.
Так как в этот стандарт не входят символы национальных алфавитов других стран, то в каждой стране 128 кодов расширенных символов заменяются символами национального алфавита. В настоящее время существует множество таблиц кодировки символов, в которых 128 кодов расширенных символов заменены символами национального алфавита.
Так, например, кодировка символов русского языка Widows – 1251 используется для компьютеров, работающих под ОС Windows. Другая кодировка для русского языка – это КОИ – 8, которая также широко используется в компьютерных сетях и российском секторе Интернет.
В настоящее время существует универсальная система UNICODE, основанная на 16 – разрядном кодировании символов. Эта 16 – разрядная система обеспечивает универсальные коды для 65536 различных символов, т.е. в этой таблице могут разместиться символы языков большинства стран мира.
Кодирование графической информации
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие группы – растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселями (pixel, от англ. picture element). Код пикселя содержит информации о его цвете.
Для описания черно-белых изображений используются оттенки серого цвета, то есть при кодировании учитывается только яркость. Она описывается одним числом, поэтому для кодирования одного пикселя требуется от 1 до 8 бит: чёрный цвет – 0, белый цвет – N = 2 k -1, где k – число разрядов, которые отводятся для кодирования цвета. Например, при длине ячейки в 8 бит это 256-1 = 255. Человеческий глаз в состоянии различить от 100 до 200 оттенков серого цвета, поэтому восьми разрядов для этого вполне хватает.
Цветные изображения воспринимаются нами как сумма трёх основных цветов – красного, зелёного и синего. Например, сиреневый = красный + синий; жёлтый = красный + зелёный; оранжевый = красный + зелёный, но в другой пропорции. Поэтому достаточно закодировать цвет тремя числами – яркостью его красной, зелёной и синей составляющих. Этот способ кодирования называется RGB (Red – Green – Blue). Его используют в устройствах, способных излучать свет (мониторы). При рисовании на бумаге действуют другие правила, так как краски сами по себе не испускают свет, а только поглощают некоторые цвета спектра. Если смешать красную и зелёную краски, то получится коричневый, а не жёлтый цвет. Поэтому при печати цветных изображений используют метод CMY (Cyan – Magenta – Yellow) – голубой, сиреневый, жёлтый цвета. При таком кодировании красный = сиреневый + жёлтый; зелёный = голубой + жёлтый.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент такого изображения – линия, прямоугольник, окружность или фрагмент текста – располагается в своем собственном слое, пиксели которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т.д.) Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Объекты векторного изображения, в отличие от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость).
Кодирование звука
Как всякий звук, музыка является не чем иным, как звуковыми колебаниями, зарегистрировав которые достаточно точно, можно этот звук безошибочно воспроизвести. Нужно только непрерывный сигнал, которым является звук, преобразовать в последовательность нулей и единиц. С помощью микрофона звук можно превратить в электрические колебания и измерить их амплитуду через равные промежутки времени (несколько десятков тысяч раз в секунду). Каждое измерение записывается в двоичном коде. Этот процесс называется дискретизацией. Устройство для выполнения дискретизации называется аналогово-цифровым преобразователем (АЦП). Воспроизведение такого звука ведётся при помощи цифро-аналогового преобразователя (ЦАП). Полученный ступенчатый сигнал сглаживается и преобразуется в звук при помощи усилителя и динамика. На качество воспроизведения влияют частота дискретизации и разрешение (размер ячейки, отведённой под запись значения амплитуды). Например, при записи музыки на компакт-диски используются 16-разрядные значения и частота дискретизации 44 032 Гц.
Описанный способ кодирования звуковой информации достаточно универсален, он позволяет представить любой звук и преобразовывать его самыми разными способами. Но бывают случаи, когда выгодней действовать по-иному.
Издавна используется достаточно компактный способ представления музыки – нотная запись. В ней с помощью специальных символов указывается высота и длительность, общий темп исполнения и как сыграть. Фактически, такую запись можно считать алгоритмом для музыканта, записанным на особом формальном языке. В 1983 г. ведущие производители компьютеров и музыкальных синтезаторов разработали стандарт, определивший такую систему кодов. Он получил название MIDI (Musical Instrument Digital Interface). При таком кодировании запись компактна, легко меняется инструмент исполнителя, тональность звучания, одна и та же запись воспроизводится как на синтезаторе, так и на компьютере.
Конечно, такая система кодирования позволяет записать далеко не всякий звук, она годится только для инструментальной музыки. Но есть у нее и преимущества: чрезвычайно компактная запись, естественность для музыканта (практически любой MIDI-редактор позволяет работать с музыкой в виде обычных нот), легкость замены инструментов, изменения темпа и тональности мелодии.
Есть и другие форматы записи музыки. Среди них – формат MP3, позволяющий с очень большим качеством и степенью сжатия кодировать музыку, при этом вместо 18 – 20 музыкальных композиций на стандартном компакт-диске (CDROM) помещается около 200. Одна песня занимает примерно 3,5 Mb, что позволяет пользователям сети Интернет легко обмениваться музыкальными композициями.











