Из чего состоит материнская плата: структура, элементная база?
У многих людей дома, в школе или на работе есть настольный компьютер. Кто-то ведёт на нём бухучёт, кто-то играет в игры, а кто-то даже сам собирает и ремонтирует их. Но хорошо ли вы знаете, из чего состоит компьютер? Взять к примеру скромную материнскую плату – она сидит себе там тихонечко, спокойно выполняет свою работу, и редко удостаивается такого же внимания, как процессор или видеокарта.
Однако значимость материнских плат, напичканных поистине впечатляющими технологиями, переоценить невозможно. Итак, сейчас мы, как студенты-медики, займёмся изучением анатомии материнской платы. Рассмотрим, какие функции выполняют все её части и чем занимается каждый бит!
Стоит ли включать EPU power saving mode?
Если вопрос энергосбережения у вас не стоит на первом месте, а в приоритете все таки производительность, то включать (переводить в положение enabled или активировать профиль max power saving) данную опцию мы не рекомендуем. Так как при резкой потребности в вычислительной мощности система EPU может не успеть повысить частоты, что приведет пусть к кратковременному, но все таки торможению работы.

EPU Engine (аббревиатура от Energy Processor/Processing Unit) — программно-аппаратная энергосберегающая технология, разработанная компанией ASUSTeK Computer (ASUS) и предназначенная для регулирования энергоснабжения компонентов персонального компьютера (ПК). EPU Engine присутствует на большинстве материнских плат производства ASUS, начиная с 2008 года, и позволяет динамически регулировать количество электроэнергии, потребляемой компонентами персонального компьютера. [1] [2]
Есть две версии EPU Engine, которые отличаются на аппаратном и программном уровнях — EPU-4 Engine и EPU-6 Engine. Различие заключается в количестве компонентов ПК, для которых присутствует возможность регулировки энергопотребления. EPU-6 Engine, как указано в названии, поддерживает шесть компонентов: центральный процессор (CPU), чипсет, оперативную память, видеокарту, носитель информации (как правило, жёсткий диск), процессорный кулер. [3] EPU-4 Engine поддерживает четыре компонента — CPU, видеокарту, носитель информации и кулер (оперативная память и чипсет не поддерживаются). [4] [5]
Как работает CPU
Как подходит к такой задаче CPU? CPU – процессор общего назначения, основанный на архитектуре фон Неймана. Это значит, что CPU работает с ПО и памятью как-то так:
Главное преимущество CPU – гибкость. Благодаря архитектуре фон Неймана, вы можете загружать совершенно разное ПО для миллионов различных целей. CPU можно использовать для обработки текстов, управления ракетными двигателями, выполнения банковских транзакций, классификации изображений при помощи нейросети.
Но поскольку CPU такой гибкий, оборудование не всегда знает заранее, какой будет следующая операция, пока не прочтёт следующую инструкцию от ПО. CPU нужно хранить результаты каждого вычисления в памяти, расположенной внутри CPU (так называемые регистры, или L1-кэш). Доступ к этой памяти становится минусом архитектуры CPU, известным как узкое место архитектуры фон Неймана. И хотя огромное количество вычислений для нейросетей делает предсказуемым будущие шаги, каждое арифметико-логическое устройство CPU (ALU, компонент, хранящий и управляющий множителями и сумматорами) выполняет операции последовательно, каждый раз обращаясь к памяти, что ограничивает общую пропускную способность и потребляет значительное количество энергии.
Впечатляющая производительность и высокая эффективность
Конечно, цель любого процессора – как можно более высокая производительность вычислений. Но насколько быстро TPU работает по сравнению с конкурентами?
Настало время обратиться к тестам. Google использует TPU с 2015 года, поэтому приводит сравнение с конкурирующими решениями, актуальными на 2015 год, а именно Intel Xeon E5-2699 v3 и NVIDIA Tesla K80. В крупных дата-центрах смена аппаратного обеспечения происходит все же не так часто.
Результаты говорят сами за себя, TPU быстрее в 15-30 раз. Если учесть соотношение производительности на ватт, то мы получим преимущество в 30-80 раз. Кроме того, Google указывает, что простое обновление платформы может значительно улучить результат. В первой версии платформы TPU работает с памятью DDR3. Но можно перейти на GDDR5, что утроит вычислительную производительность. А эффективность возрастет в 70-200 раз по сравнению с упомянутыми выше решениями.
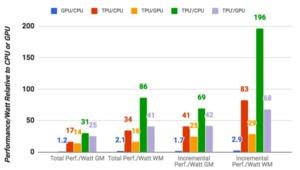
Поэтому Google и решила разработать собственные чипы TPU, ориентированные на узкую область применения. Все же производители, подобные Intel, IBM или NVIDIA выпускают универсальные чипы с широкой сферой использования, а не оптимизированные под 8-битные вычисления. Конечно, все производители с каждым поколением увеличивают производительность. Но в ближайшем будущем индустрия вряд ли будет обходиться без специализированных решений.
Структура тензорного процессора
Быстрое сложение и умножение — сильная сторона тензорного процессора. В ответственном за это модуле с матрицей в качестве центрального компонента производятся вычисления нейронных сетей. Она занимает около четверти площади процессора. Остальное место используется для быстрой подачи вводных данных. Они поступают через PCI Express и оперативную память DDR3. Результаты вычислений возвращаются на сервер через PCI Express и интерфейс хоста.
Свое название процессоры получили от библиотеки программного обеспечения TensorFlow. Основное предназначение TPU состоит в ускорении алгоритмов искусственного интеллекта, которые делают ставку на библиотеки свободного программного обеспечения.
Изначально TPU обрели популярность в качестве аппаратной платформы для AlphaGo —искусственного интеллекта, который победил лучших в мире игроков в азиатскую игру го. В отличие от шахмат, разработка программного обеспечения для го на профессиональном уровне на протяжении многих лет считалась невозможной.
Последующая разработка AlphaGo Zero смогла самостоятельно обучиться игре на основе заданных ей правил. Через три дня она достигла профессионального уровня, через три недели — догнала предшествующую версию AlphaGo, обучение которой стоило громадных усилий и потребовало проведения миллионов профессиональных партий. Выяснилось, что искусственный интеллект ранее ограничивал изучение ходов со стороны человека. Еще через шесть недель AlphaGo Zero уже невозможно было обыграть.
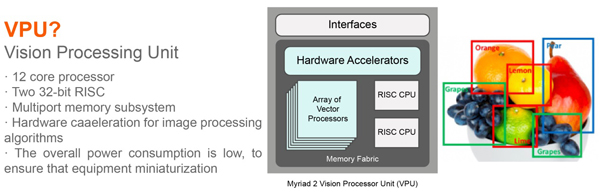
Разные другие буквы
Вообще, тема ускорения нейросетей стала модной, ей занимаются все крупные компании и десятки стартапов, и как минимум 5 из них привлекли более 100 миллионов долларов инвестиций к началу 2018 года. Всего же в 2017 в стартапы, связанные с разработкой чипов, было инвестировано 1,5 МИЛЛИАРДА долларов. При том, что инвесторы не замечали чипмейкеров добрых 15 лет (ибо ловить там на фоне гигантов было нечего). В общем — сейчас появился реальный шанс на небольшую железную революцию. Причем предсказать, какая архитектура победит крайне сложно, необходимость в революции назрела, а возможности в увеличении производительности велики. Созрела классическая революционная ситуация: Мур уже не может, а Дин еще не готов.
Ну а поскольку важнейший рыночный закон — отличайся, появилось много новых букв, например:
-
Neural Processing Unit (NPU) — Нейропроцессор, иногда красиво — нейроморфный чип — вообще говоря, общее название для акселератора нейросетей, каковым называют чипы Samsung, Huawei и далее по списку…

Здесь и далее в этом разделе будут приведены в основном слайды корпоративных презентаций в качестве примеров самоназваний технологий
Понятно, что прямое сравнение проблематично, но вот любопытные данные, сравнивающие чипы с нейропроцессорами от Apple и Huawei, производимые упоминавшейся в начале TSMC. Видно, что соревнование идет жесткое, новое поколение показывает прирост производительности в 2-8 раз и усложнение технологических процессов:
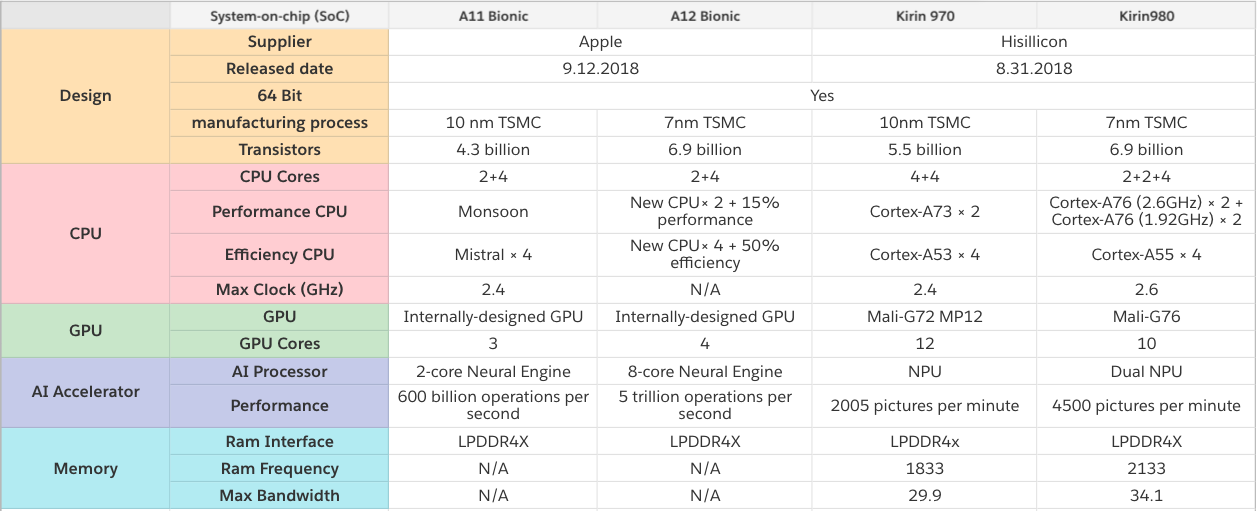


В общем, как видим, бурно расцветают все цветы. Постепенно компании переварят миллиарды долларов инвестиций (обычно на производство чипов требуется 1,5–3 года), пыль осядет, лидер станет понятен, победители, как обычно, напишут историю, и название наиболее успешной на рынке технологии станет общепринятым. Так уже было не раз («IBM PC», «Smartphone», «ксерокс» и т.д.).
2017: Анонс первого поколения
17 мая 2017 года Google анонсировала процессор для суперкомпьютеров Cloud Tensor Processing Unit (TPU). Решение, ориентированное на системы машинного обучения, будет использоваться не только самой компанией, но и ее клиентами, которые смогут получить доступ к новинке через облако Google Cloud.
Cloud TPU не будет продаваться производителям серверов напрямую. Они смогут воспользоваться производительностью процессоров, подключившись к облачному сервису Google для выполнения своих рабочих нагрузок и хранения данных на оборудовании американской компании.

Cloud TPU — это второе поколение чипов, разрабатываемых Google. Первая версия была представлена 2016 году. Тогда сообщалось, что TPU — это интегральная схема специального назначения (ASIC), предназначенная для ускорения процессов получения готовых результатов в уже обученных нейросетях. К примеру, система вступает в работу, когда пользователь инициирует голосовой поиск, запрашивает перевод текста или ищет совпадение с изображением.
Cloud TPU стал быстрее предшественника: производительность выросла до 180 терафлопс в операциях с плавающей точкой. В каждом процессоре содержится специальная высокоскоростная сеть, позволяющая создавать суперкомпьютеры, которые в Google называют TPU Pod.
Один такой модуль содержит 64 новых процессора и обладает производительностью на уровне 11,5 петафлопс. Такая скорость значительно снижает время обучения систем искусственного интеллекта. Так, один из суперкомпьютер Google проходил за сутки одну процедуру обучения, используя 32 самых быстрых на рынке GPU, в то время как лишь восьмая часть TPU Pod позволяет проводить аналогичные операции всего лишь с утра до вечера.
Один модуль, состоящий из четырех процессоров Cloud TPU, примерно в 12 тыс. быстрее суперкомпьютера Deep Blue, получившего известность после победы в шахматах над чемпионом мира Гарри Каспаровым в 1997 году, отметил Урс Хёльцле (Urs Hölzle), старший вице-президент Google по технической инфраструктуре.
Google не раскрыла ни сроки, ни стоимость аренды новых процессоров, ни имя производителя этих решений. Компания, продолжающая закупать чипы у Intel и Nvidia, может ежегодно экономить миллиарды долларов за счет использования собственных решений, отмечает Bloomberg.











