Что такое HTTP, или как браузеры общаются с веб-серверами
В статье про устройство веба и как происходит серфинг я упомянул, что браузер отправляет запрос к веб-серверу. Но что представляет из себя запрос? Это куча машиночитаемых квантовых кодов и сингулярных шифров? Программистская магия? Вовсе нет.
HTTP — это протокол передачи данных для клиент-серверных приложений.
Не нужно пугаться слова «протокол». Это значит лишь то, что разработчики встретились и договорились о возможных форматах запросов и ответов на них. Вокруг нас множество таких протоколов-договорённостей.
- При встрече на протянутую руку принято отвечать рукопожатием. Отсутствие рукопожатия — это тоже ответ, иногда даже более красноречивый, чем само рукопожатие.
- Девушкам же руку не протягивают — это тоже часть протокола. Можно и им руку протянуть, но в большинстве случаев не поймут, а в некоторых странах заставят жениться.
- Электрические розетки — хотя в разных странах они разные, внутри одной страны они одинаковы.
- Разъёмы для кабелей — USB type B, USB type C, mini USB, micro USB. Производители приняли внегласный протокол и производят кабели и устройства именно таких форматов, иначе при прочих равных пользователи их не поймут и не будут покупать их продукцию (исключение — Apple).
- Правила дорожного движения — знаки, разметка и светофоры помогают пешеходам дойти, а автомобилистам доехать до места назначения без происшествий.
- Формы налоговых деклараций и прочих бюрократических документов.
Любой из протоколов нас ни к чему не обязывает, это не ГОСТ, он лишь рекомендует поступать так или иначе, если мы хотим добиться желаемой цели — понимания от окружающих людей, одобрения от покупателей, сохранения продаж, избежания аварий и штрафов, получения веб-страницы от сервера.
HTTP — это набор некоторых правил, которым должны следовать клиенты и сервера, если они хотят, чтобы их правильно поняли.
HTTP-клиентами чаще всего являются браузеры — Google Chrome, Mozilla Firefox, Safari, Opera, Yandex Browser и другие. А серверами являются веб-сервера. Вот эта приставка «веб-» и указывает на то, что это не просто какой-то сервер, а сервер, который умеет принимать запросы и отвечать на них по протоколу HTTP. Как он будет устроен внутренне — не определено и не важно. Наиболее популярными в мире веб-серверами являются Nginx, Apache2, но вы можете написать и свой — в некоторых языках это делается крайне легко, см. пример на Golang.
Как увидеть данные, переданные методом POST, в Google Chrome
Итак, открываем (или обновляем, если она уже открыта) страницу, от которой мы хотим узнать передаваемые POST данные. Теперь открываем инструменты разработчика (в предыдущих статьях я писал, как это делать разными способами, например, я просто нажимаю F12):

Теперь отправляем данные с помощью формы.
Переходим во вкладку «Network» (сеть), кликаем на иконку «Filter» (фильтр) и в качестве значения фильтра введите method:POST:
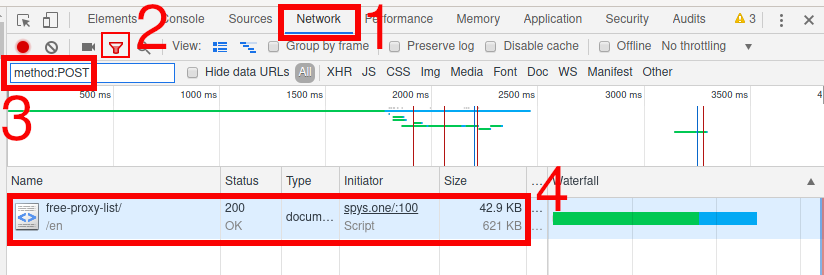
Как видно на предыдущем скриншоте, был сделан один запрос методом POST, кликаем на него:

- Header — заголовки (именно здесь содержаться отправленные данные)
- Preview — просмотр того, что мы получили после рендеренга (это же самое показано на странице сайта)
- Response — ответ (то, что сайт прислал в ответ на наш запрос)
- Cookies — кукиз
- Timing — сколько времени занял запрос и ответ
Поскольку нам нужно увидеть отправленные методом POST данные, то нас интересует столбец Header.
Там есть разные полезные данные, например:
- Request URL — адрес, куда отправлена информация из формы
- Form Data — отправленные значения
Пролистываем до Form Data:
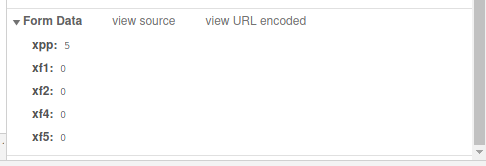
Там мы видим пять отправленных переменных и из значения.
Если нажать «view source», то отправленные данные будут показаны в виде строки:

Вид «view parsed» — это вид по умолчанию, в котором нам в удобном для восприятия человеком виде показаны переданные переменные и их значения.
Что такое HTTP, структура HTTP-запроса и ответа?
Независимо от того, являетесь ли вы пользователем или владельцем веб-сайта, при просмотре вы можете встретить одно слово — HTTP. Важно получить основы HTTP, чтобы понять, как работает Интернет, и какие данные отправляются и принимаются между вашим браузером и веб-сервером. Вот руководство по HTTP для новичков, которое пытается объяснить основы.
В этом руководстве мы объяснили следующие темы:
- Что такое HTTP?
- Структура HTTP-запроса от клиента
- Структура HTTP-ответа от веб-сервера
- Пример сквозного HTTP-сеанса
- Что такое HTTPS?
- Проверка HTTP-запроса и ответа в браузере Chrome
- Проверка заголовков HTTP с помощью бесплатного инструмента
- Устранение неполадок с кодами состояния HTTP
- Детали кода состояния HTTP
- Скачать руководство по кодам состояния HTTP
1. Что такое HTTP?
HTTP означает ЧАС yper Т доб Т перевод п протокол. Это основа для передачи данных в Интернете. Обмен данными начинается с запроса, отправленного от клиента, и заканчивается ответом, полученным от веб-сервера.
- URL-адрес веб-сайта, начинающийся с «http: //», вводится в веб-браузере с компьютера (клиента). Браузером может быть Chrome, Firefox, Edge, Safari, Opera или что-нибудь еще.
- Браузер отправляет запрос на веб-сервер, на котором размещен веб-сайт.
- Затем веб-сервер возвращает браузеру ответ в виде HTML-страницы или документа любого другого формата.
- Браузер отображает ответ сервера пользователю.
Символьное представление процесса связи HTTP показано на рисунке ниже:

Веб-браузер называется пользовательским агентом, а другим примером пользовательского агента являются сканеры поисковых систем, таких как Googlebot.
2. Структура HTTP-запроса от клиента
Простое сообщение-запрос от клиентского компьютера состоит из следующих компонентов:
- Строка запроса на получение необходимого ресурса, например, запрос GET /content/page1.html запрашивает ресурс с именем /content/page1.html с сервера.
- Заголовки (пример — Accept-Language: EN).
- Пустая строка.
- Тело сообщения, которое не является обязательным.
Все строки должны заканчиваться символом возврата каретки и перевода строки. Пустая строка должна содержать только возврат каретки и перевод строки без пробелов.
3. Структура HTTP-ответа от веб-сервера
Простой ответ сервера содержит следующие компоненты:
- Код состояния HTTP (Например, HTTP / 1.1 301 перемещен навсегда, означает, что запрошенный ресурс был постоянно перемещен и перенаправлялся на какой-либо другой ресурс).
- Заголовки (пример — Content-Type: html)
- Пустая строка.
- Тело сообщения, которое не является обязательным.
Все строки в ответе сервера должны заканчиваться символом возврата каретки и перевода строки. Как и в случае с запросом, пустая строка в ответе должна содержать только возврат каретки и перевод строки без пробелов.
4. Пример HTTP-сеанса
Рассмотрим пример, когда вы хотите открыть страницу home.html с сайта yoursite.com. Ниже показано, как должен выглядеть запрос клиентского браузера для получения страницы «home.html» с «yoursite.com».
Ответ веб-сервера должен выглядеть следующим образом:
Кодирование передачи по частям — это метод, при котором сервер отвечает данными фрагментами, которые используются вместо заголовка Content-Length. Связь прекращается, когда получен фрагмент нулевой длины, и этот метод используется в HTTP версии 1.1.
5. Что это за HTTPS?
Теперь вы понимаете HTTP, тогда что это за HTTPS? HTTPS — это защищенный протокол HTTP, необходимый для безопасной отправки и получения информации через Интернет. В настоящее время для всех веб-сайтов обязательно иметь протокол HTTPS, чтобы иметь защищенный Интернет. Браузеры, такие как Google Chrome, будут отображать предупреждение с сообщением «Небезопасно» в адресной строке, если сайт не обслуживается через HTTPS.
Помимо безопасности и шифрования, структура связи протокола HTTPS остается такой же, как и у протокола HTTP, как описано выше.
Настоятельно рекомендуется не использовать конфиденциальную информацию, такую как данные кредитной карты, на сайтах HTTP. Убедитесь, что финансовые транзакции происходят через протокол HTTPS.
6. Как проверить HTTP-запрос и ответ в Chrome?
Что ж, пора практиковаться. Давайте возьмем популярный браузер Google Chrome, но процесс просмотра деталей остается таким же во всех других браузерах.
- Откройте веб-страницу в Google Chrome и перейдите в меню «Просмотр> Разработчик> Инструменты разработчика».
- Вы также можете открыть консоль разработчика, щелкнув страницу правой кнопкой мыши и выбрав опцию «Проверить».
- Перейдите на вкладку «Сеть» и перезагрузите страницу. Теперь вы увидите время загрузки для каждого отдельного компонента на странице.
- Щелкните значок «Показать обзор», чтобы удалить временную шкалу, чтобы можно было четко просмотреть другие сведения.
- Щелкните URL-адрес страницы на левой панели и перейдите на вкладку «Ответ». (Вы также можете просмотреть те же сведения на вкладке «Предварительный просмотр»).
Вы можете увидеть детали запроса и ответов, как мы объяснили в предыдущих разделах. Вкладка «Заголовки» покажет вам подробную информацию о заголовке HTTP для запроса и ответа для выбранного элемента.
7. Средство проверки заголовка HTTP
Как и в случае с Chrome, существует множество других бесплатных инструментов для проверки кода ответа, полученного в заголовках HTTP. Например, перейдите к этому инструменту проверки заголовка HTTP, введите любой URL-адрес, который вы хотите проверить, и нажмите кнопку отправки.
Вы увидите полную информацию о заголовке, как показано ниже:
8. Устранение неполадок с кодами состояния HTTP.
Есть много причин, по которым запрос браузера не получит требуемый ответ от веб-сервера. В таких случаях отказа информация ответа от веб-сервера важна для устранения неполадок. Коды состояния, возвращаемые сервером, можно четко увидеть в разделе инструментов разработчика Chrome. На приведенном выше снимке экрана строка 4 — код HTTP / 1.1 200 OK указывает, что сервер успешно вернул запрошенный ресурс без каких-либо проблем. Вы можете получить эти сведения с помощью инструмента проверки заголовка HTTP, как описано выше.
Трехзначный код, возвращаемый сервером, называется кодом состояния HTTP, хотя некоторые люди называют его кодом ошибки, хотя это не ошибка. Это просто статусный ответ, который поможет вам найти причину сбоя связи. Помните, что сбой связи также может произойти из-за проблем с браузером и компьютером, таких как проблемы с локальной сетью. В этих случаях современные браузеры, такие как Chrome, будут отображать ошибки браузера, такие как «err_network_changed», «err_internet_disconnected» и т. Д.
9. Подробная информация о кодах состояния HTTP
Коды состояния HTTP разработаны в соответствии со стандартами Интернета, определенными Инженерной группой Интернета (IETF). Они подразделяются на пять различных категорий, как показано ниже:
- Серия 1xx — информационное сообщение
- 2xx — Сообщение об успехе
- 3xx — сообщение о перенаправлении
- 4xx — сообщения об ошибках, относящиеся к клиенту
- 5xx — сообщения об ошибках, относящиеся к серверу
9.1. Информационная серия — 1xx
Это информационные коды, отправленные сервером, указывающие на то, что запрос получен от клиента успешно, и он обрабатывается на стороне сервера. Это предварительный ответ от сервера, который обычно содержит только строку состояния и необязательные заголовки и заканчивается пустой строкой. Узнайте подробнее о кодах состояния 1xx.
9.2. Успех серии — 2хх
Это коды успеха, отправленные сервером, указывающие, что запрос получен и обработан успешно. Подробнее о каждом коде состояния 2xx.
9.3. Перенаправление — 3хх
Это коды состояния для перенаправления. Когда пользовательский агент (веб-браузер или поисковый робот), запрашивающий URL1, перенаправляется на другой ресурс URL2, в качестве ответа возвращаются коды 2xx. Эти коды не видны в окне браузера, поскольку браузеры автоматически перенаправляются на другой URL. Подробно узнайте больше о кодах состояния 3xx.
9.4. Ошибки клиента — 4xx
Это ошибки со стороны клиента, которые сервер не смог устранить. Простой и хорошо известный пример — ошибка «404 — страница не найдена», отображаемая в окне браузера, когда браузер запрашивает недоступный URL. Узнайте подробнее о кодах состояния 4xx.
9.5. Серия ошибок сервера — 5xx
Когда веб-сервер не может выполнить действительный запрос от клиента, он отправляет в ответ код ошибки 5xx. Примером является ошибка «504 — Тайм-аут шлюза», когда веб-сервер1 действует как прокси-сервер для получения ответа от другого веб-сервера2, но не может получить своевременный ответ. Узнайте подробнее о кодах состояния 5xx.
10. Загрузите руководство по кодам состояния HTTP.
Вы можете загрузить полное руководство по кодам состояния HTTP для автономного использования и подробно узнать больше о каждом коде.

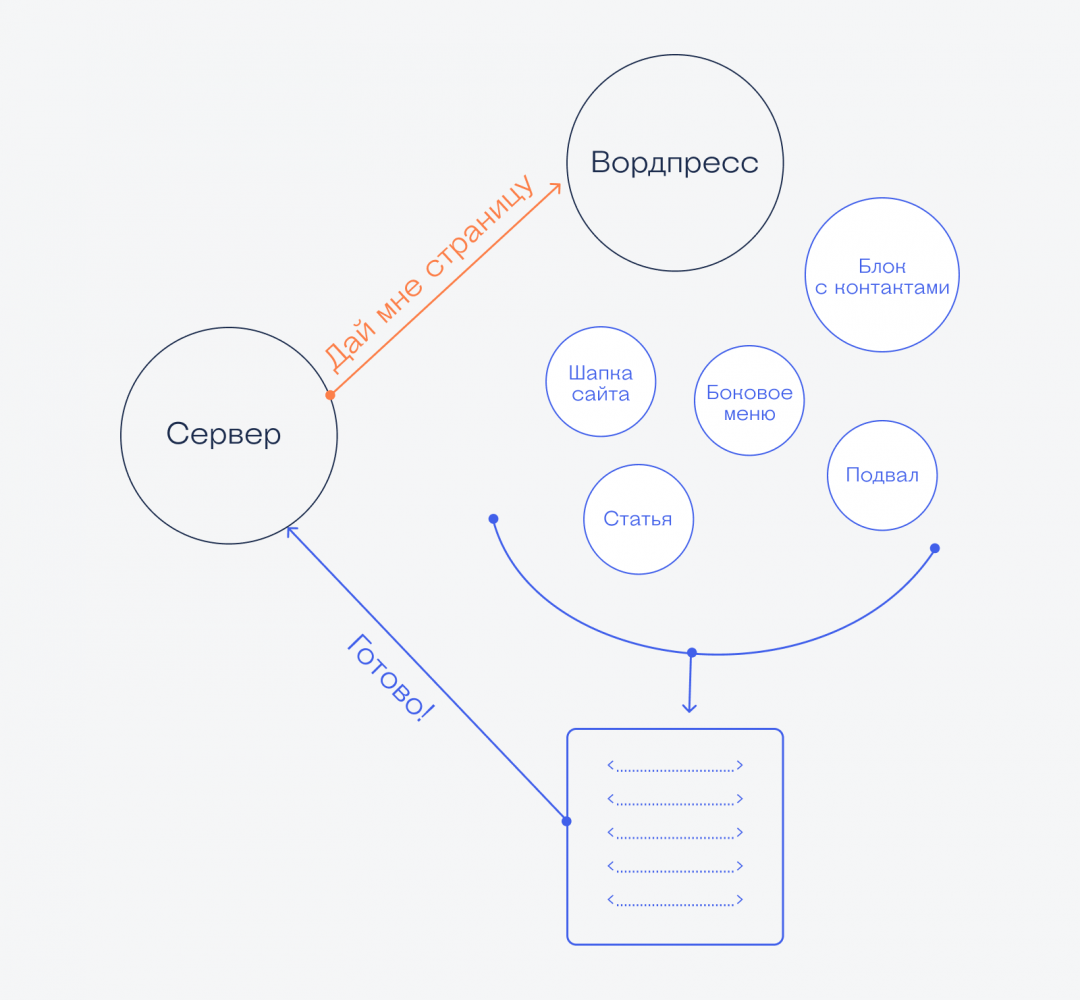
Сервер думает
Когда сервер получает запрос от браузера и с адресом всё в порядке, он начинает готовить данные к отправке. Для этого он смотрит, какие серверные программы отвечают за этот домен, и говорит им «Соберите мне вот эту страницу, чтобы я её отправил в браузер». Например, на сервере может стоять Вордпресс или PHP-обработчик, который на лету собирает страницу из разных фрагментов кода.
Метод GET
Во-первых, что вообще такое HTML-форма? Это интерфейс, позволяющий отправлять какие-либо данные с браузера клиента на сервер. Взгляните на атрибуты вашей формы:
Атрибут action отвечает за адрес получателя отправляемых данных. В нашем случае форма отправляется на тот же адрес, т.е. на lessons/index.php.
Особое внимание заслуживает атрибут method , который определяет метод отправки запроса на сервер. Таких методов несколько, а наиболее распространенные (и практичные) это методы GET и POST. Сейчас нас будет интересовать метод GET.
GET-запрос означает, что данные будут передаваться на сервер непосредственно через адресную строку. Вы в этом уже убедились, отправив форму – к строке адреса добавились определенные данные. Откуда эти данные берутся? Обратите внимание на теги input в HTML-форме. У всех их присутствует атрибут name , который устанавливает имя данного поля.
При методе GET к основному адресу добавляется символ «?» (знак вопроса), чтобы сервер понимал, что поступили какие-то данные. После символа «?» идут непосредственно сами данные в виде имя=значение . Если таких данных несколько, то они разделяются между собой символом объединения «&». Отправьте форму с другими значениями полей и убедитесь в этом.
Ладно, данные отправились. Что дальше? Куда они ушли и что с ними делать? Вот тут и начинается самое интересное.
Пришло время научиться «ловить» и обрабатывать полученные данные. Ввиду того, что атрибут action указывает на текущий файл index.php, значит данные поступают именно сюда, поэтому в этом же файле мы и пропишем код обработки GET-запроса .
Итак, сразу же после тега добавим такой PHP-код:
Сохраните файл, снова зайдите на http://lessons/, отправьте форму и – о, чудо! – что вы видите?
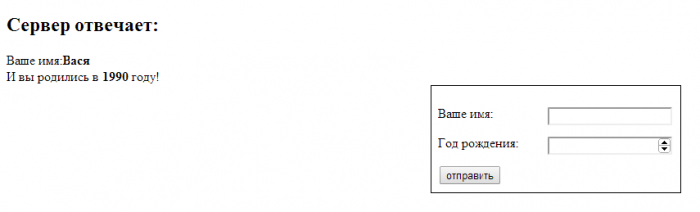
Только что, после отправки формы, сервер получил и обработал полученные данные и прислал в браузер свой ответ!
Рассмотрим PHP-код нашего проекта, который представляет собой условие:
Сервер проверяет, а получена ли переменная GET-запроса с именем submit_form? То есть, говоря проще, а была ли вообще отправлена форма? Если это так, то серверный php-код отправляет прямо в браузер пользователя новую HTML-разметку со своим ответом, используя для этого оператор echo . Если вы внимательно изучите написанный код-обработчик, то вам сразу все станет понятным!
Интересный же этот метод GET! Измените адресную строку, например, на такую:
и нажмите кнопку «Ввод». Сервер снова вам ответит, приняв уже другие данные! Думаю, с этим все понятно.
Недостатки GET-метода в том, что, во-первых, есть ограничение на объем передаваемых данных, а во-вторых, этот метод является открытым и любую информацию можно перехватить. Поэтому личные данные пользователя (логин, имя, пароль и др.) никогда нельзя передавать через строку адреса.
Что такое HTTP и как он работает?
Чтобы получить нужный документ в интернете, пользователю достаточно ввести в поисковую строку браузера нужный URL-адрес (тут о структуре урлов подробности), который как раз содержит название протокола HTTP (или HTTPS).
Сюда же входит имя домена (что это?), следующее за двойным слешем «//». Причем, путь (часть адреса за слешем после домена) может быть прописан как до нужной страницы сайта, так и до файла, физически находящегося в определенной директории (папке). Но это может быть и главная вебстраница, адрес которой состоит только из доменного имени:
А теперь попробуем разобраться в общих чертах, как работает этот механизм. Для начала необходимо выяснить, что же такое HTTP. Это протокол, который служит для «транспортировки» информации между клиентским приложением и сервером.
Аббревиатура HTTP (HyperText Transfer Protocol) переводится с английского как «протокол передачи гипертекста». Вообще говоря, протоколов достаточно много, и каждый из них решает определенную задачу (например, тот же FTP).
Но нас в первую очередь интересует HTTP, поскольку именно этот протокол связан с отображением страниц в браузере, которые как раз имеют гипертекстовую структуру, отличающуюся наличием ссылок, помогающих пользователю переходить от одного текстового фрагмента к другому (со страницы на страницу в пределах одного сайта либо даже на вебстраницу другого ресурса).
Необходимо отметить, что передача данных по HTTP происходит посредством TCP/IP-соединения. При этом серверное приложение по умолчанию использует порт 80, хотя в некоторых случаях может применяться и другой.
TCP (Transmission Control Protocol)/IP является довольно сложной системой и включает в себя четыре уровня протоколов (прикладной, к которому и относится HTTP, транспортный, сетевой и канальный). Думаю, для общей информации этого пока достаточно, а то мы залезем в дебри.
Как осуществляется взаимодействие между клиентским приложением и сервером
Итак, мы определили, что HTTP организует передачу данных в форме гипертекста. Но как это происходит на практике? Я уже упомянул, что здесь применяется технология, заключающаяся в общении между клиентским приложением и сервером, на котором располагаются физические файлы, получаемые в чистом виде для просмотра, либо шаблоны той или иной CMS, генерирующие странички сайта «на лету».
Ну с сервером худо-бедно понятно (это просто большой компьютер, где и расположены веб-сайты), а вот что за клиентские приложения участвуют в «игре»? Но и здесь все просто. Это может быть браузер пользователя (тут о всех популярных веб-обозревателях материал), который является не чем иным как программой для поиска и просмотра информации в глобальной сети.
Я уже давал общую схему того, как, благодаря отлаженному взаимодействию серверов DNS и системы IP-адресации реализовано бесперебойное функционирование интернета, когда пользователь сети может получить доступ к любому файлу или документу (например, к странице сайта) для получения информации, которая его интересует.
Теперь немного конкретизируем действие этого механизма. После того, как юзер вбил в адресную строку URL (который, как известно содержит доменное имя конкретного вебсайта) либо перешел по ссылке с другой вебстраницы или с закладок, браузер обращается в ближайший ДНС сервер.
Там хранятся все имена доменов, каждому из которых соответствует уникальный IP адрес, связанный с сервером, на котором «живет» сайт с этим ДИ. Получив ай-пи, браузер отправляет на сервер HTTP-запрос, после чего получает ответ. Единую схему запросов и ответов при общении клиентского приложения (в нашем случае браузера) с сервером можно представить так:

Между списком заголовков и телом сообщения присутствует пустая строка, которая определяется символом переноса. В случае запроса начальная строка состоит из следующих компонентов:
Давайте разберем вкратце все составляющие, чтобы иметь хотя бы общее представление об этом этапе взаимодействия браузера и сервера. Итак, верхняя строка:
1. Метод — указывает на действие, которое необходимо совершить с данным веб-ресурсом. Таких методов несколько, но самые распространенные среди них это GET и POST. Первый предполагает получение данных с сервера для просмотра (например, определенную страницу конкретного сайта), а второй обратную операцию, то есть отправку информации на сервер (регистрации пользователей, формы авторизации, различных сообщений и т.д.).
2. URI (унифицированный идентификатор ресурса, который является более общим понятием, чем URL) — путь до файла относительно корневой папки (почитайте, как формируются абсолютные и относительные ссылки).
3. HTTP/Версия — указывается действующая модификация протокола. На данный момент это HTTP 1.1 (вы можете ознакомиться с ее спецификацией). Однако, в черновом виде уже существует следующая версия протокола 2.0, который основан на двоичной (бинарной) системе счисления.
Нижняя строка представляет собой заголовок Host в составе HTTP-запроса, отсылаемого браузером серверу в соответствии с полученным от ДНС IP. Для чего это надо? Для идентификации нужного сайта, поскольку на вебсерверах обычно расположен не один ресурс.
Разберем наглядный пример для закрепления пройденного. Скажем, браузер получил «задание» от пользователя отобразить страничку вот с таким адресом:
Тогда HTTP-запрос посредством метода GET может быть составлен следующим образом (в этом случае обычно тело сообщения отсутствует):
Для наглядности я предоставил лишь самый простой пример, включающий один заголовок Host, на самом деле, их может быть несколько. Но это не все. Ведь для полноценного общения необходим диалог, который и устанавливается после того, как на запрос браузера сервер дает ответ. Начальную строку ответа тоже можно изобразить схематически:
Теперь пробежимся вкратце и по составу ответа сервера:
1. Версия HTTP указывается по аналогии с запросом.
2. Код состояния (Status Code) — три цифры, информирующие о том, каков статус документа, запрошенного браузером. Например, 200 — ОК, страница существует и будет отображена в браузере, 301 — осуществлен постоянный редирект (перенаправление) на другой урл, 404 — вебстранички по такому адресу нет (возможно, она удалена либо юзер ошибся при вводе URL).
3. Пояснение (Reason Phrase) — текст дополнения к коду ответа. В некоторых случаях пояснение может отличаться от стандартного либо отсутствовать вовсе. Это связано в том числе с настройкой ПО, размещенного на сервере.
Реальный пример? Пожалуйста. Попробуем получить ответ сервера на запрос, приведенный мною в качестве примера выше (урл «http://subscribe.ru/group/»). Он будет выглядеть так (начальная строка с заголовками):
В данном случае отсутствуют пояснение и тело сообщения, которое при использовании метода GET может содержать, например, HTML-код запрашиваемого документа (веб-странички). В зависимости от типа приложения клиента эти разделы могут присутствовать.
Итак, резюмируем вкратце выше изложенное. Если пользователь вводит урл искомой страницы, имея ввиду получить ее содержимое для просмотра, браузер посылает GET запрос на нужный сервер и получает ответ. В результате этого общения либо (при благоприятных обстоятельствах) контент запрошенного документа будет отображен, либо нет.
В любом случае, по содержанию HTTP-ответа сервера (включая код состояния) можно получить полезную информацию, связанную с запрашиваемым документом.
Для того, чтобы выше предложенная информация без усилий ложилась в пазл, не хватает конкретного примера. Его мы рассмотрим с помощью одного из расширений Google Chrome (именно этот веб-обозреватель является моим рабочим инструментом), именуемого HTTP Headers.
Он удобен тем, что дает полную картину взаимодействия «клиент-сервер», предоставляя в «одном флаконе» содержание HTTP запроса (request) и ответа (response). Посмотрите, какой документ выдал этот плагин при переходе по ссылке с одной страницы моего блога на другую:

Здесь в самом верху отмечен метод GET, с помощью которого браузер обращается к серверу, а также статус странички, отмеченный кодом состояния 200 OK, который дает понять, что сервер передал все данные в отношении запрашиваемой вебстраницы.
Интерес вызывают также HTTP Headers (заголовки), отображенные ниже. Например, пункт «Referer» дает информацию в виде урла, откуда был осуществлен переход.
Заголовок «User Agent» отражает как раз клиентское приложение, отправившее запрос вебсерверу. В данном случае это браузер, но могут быть и другие (мобильные устройства, поисковые роботы и т.д.). Данные, представленные в Юзер Агенте, необходимы серверному программному обеспечению для идентификации приложения, посылающего запрос.
Как раз боты поисковых систем, сканирующие страницы сайтов для получения информации, влияющей на ранжирование, нас и интересуют в первую очередь, потому как именно они решают судьбу той или иной страницы в плане эффективности ее продвижения.
Вот потому-то в следующей публикации я планирую поподробнее остановится на том, как просмотреть HTTP-заголовки и проверить коды ответов сервера именно на запрос робота, что исключительно важно для вебмастеров в свете SEO оптимизации ресурса. Поэтому оформляйте подписку, чтобы своевременно получить свежую статью.











