Уровень аппаратных абстракций
Как уже упоминалось, одним из наиболее важных элементов конструкции Windows является ее переносимость между разнообразными аппаратными платформами. Уровень аппаратных абстракций — hardware abstraction layer (HAL) является ключевой частью, обеспечивающей возможность такой переносимости.
HAL является загружаемым модулем режима ядра (Hal.dll), обеспечивающим низкоуровневый интерфейс с аппаратной платформой, на которой запущена Windows. Он скрывает подробности, зависящие от аппаратуры, такие как интерфейсы ввода-вывода, контроллеры прерываний и механизмы взаимодействия процессоров, — любые функции, имеющие как архитектурные, так и машинные зависимости.
Поэтому вместо непосредственного доступа к оборудованию, внутренние компоненты Windows, а также написанные пользователями драйверы устройств, при необходимости получения информации, зависящей от платформы, поддерживают переносимость путем вызова HAL-подпрограмм. По этой причине HAL-подпрограммы документированы в WDK. Для получения дополнительной информации о HAL и его использовании драйверами устройств нужно обратиться к WDK.
Хотя в операционную систему включено несколько HAL-модулей (см. табл), у Windows есть возможность определить во время загрузки, какой HAL-модуль должен использоваться, исключая проблемы, существовавшие в ранее выпущенных версиях Windows при попытке загрузки установки Windows на разных типах систем.
Введение¶
Операционные системы окружают нас повсюду – это основное программное обеспечение персональных компьютеров, серверов, мобильных устройств, сетевых устройств (роутеры, коммутаторы) и даже современных автомобилей (борт-компьютер), телевизоров и прочего. Перечислять можно очень долго, ведь они требуются практически в каждой компьютерной системе.
Любой компьютер представляет собой связанную совокупность: процессора, памяти и устройств ввода-вывода.
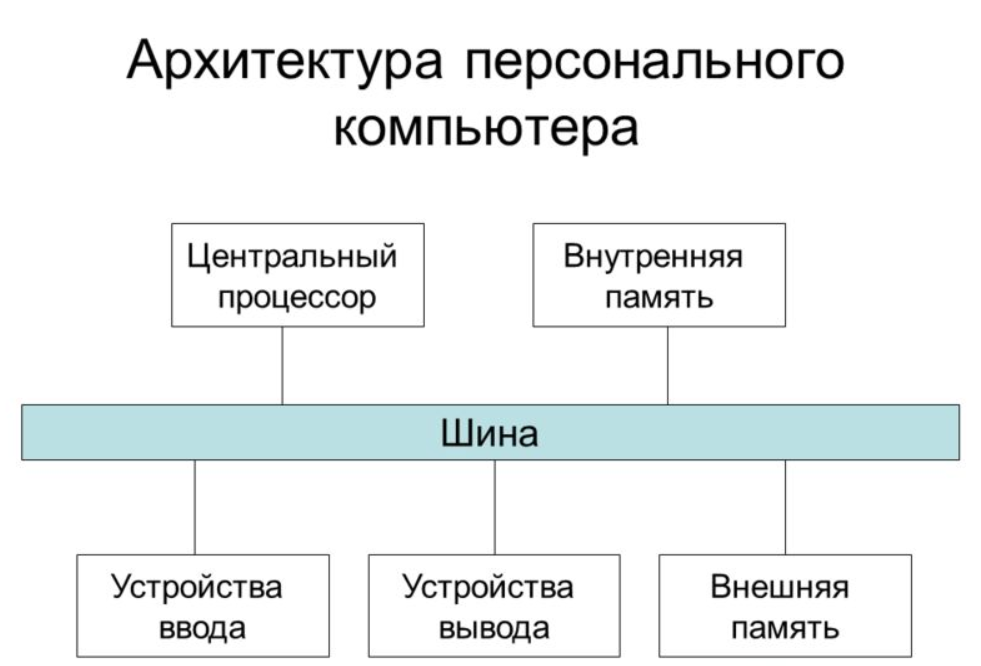
Рис. 1. Общее представление архитектуры компьютера
Сама по себе, аппаратура умеет делать только очень простые, базовые операции — по типу: сложить два числа, перейти к адресу, записать по адресу и тд.
Например, процессор умеет выполнять только четыре базовых типа инструкции:
- Чтение инструкций/данных из памяти (read)
- Выполнение интрукции (execute)
- Запись результата в память (write)
- Прерывание (interrupt)
Получается, что непосредственное создание и управление сложными процессами (приложениями) на аппаратуре становится крайне неэффективным и неудобным. То есть, например, создать и запустить на исполнение программу-браузер исключительно с помощью данных инструкций становится крайне сложной задачей. Особенно при условии, что помимо этого процесса (браузера) существуют и другие процессы, которые также пользуются ресурсами вычислительной машины.
Возникает вопрос — Как заставить всё это слаженно и эффективно работать, сделав пользование компьютером удобным как для обычного человека, так и для прикладного программиста?
Чтобы ответить на этот вопрос более последовательно, немного заглянем туда, откуда всё начиналось.
Немного истории¶
На заре компьютерной эпохи, первые компьютеры представляли собой огромные блоки (занимавшие большие комнаты), в которых размещались основные его компоненты: процессор, память и устройства ввода-вывода. И всего можно было выделить два состояния, в котором, в реальном времени находится компьютерная система:
- Ввод/Вывод
- Вычисление
Важная идея! Так как вычисления производятся быстрее, чем непосредственный ввод-вывод данных, разработчикам пришла идея о том, что к ресурсам можно допускать не одного пользователя (процесс), а множество, предоставляя им способ независимо друг от друга загружать (ввод) и получать (вывод) данные через отдельные терминалы, чтобы более эффективно использовать ресурсы компьютера и вычислительные модули не простаивали в ожидании ввода/вывода.
Идея многопользовательского режима в использовании ресурсов компьютера нашла свою реализацию в понятии процесс. То есть, каждый процесс — это пользователь ресурсов компьютера.
Эта идея положила начало созданию такой системы, которую мы теперь называем операционной — программной системы, которая управляет ресурсами компьютера, а следовательно осуществляет доступ к этим ресурсам и управляет процессами — пользователями этимх ресурсов.
Далее, термины: процесс, приложение идут как синонимы термину пользователь ресурсов.
Преимущества
- Более простая реализация по сравнению с другими подходами.
- Предлагает абстракцию благодаря разделению ответственностей между уровнями.
- Изолирование защищает одни слои от изменений других.
- Повышает управляемость программного обеспечения за счет слабой связанности.
- Не предлагает большой масштабируемости.
- ПО, созданное с таким подходом, будет иметь монолитную структуру, усложняющую внесение модификаций.
- Данные должны проходить по каждому слою, даже если нет необходимости передавать их с определенных слоев.
Абстракция управления
Языки программирования предлагают абстракцию управления как одну из основных целей своего использования. Компьютерные машины понимают операции на очень низком уровне, такие как перемещение некоторых битов из одного места памяти в другое место и создание суммы двух последовательностей битов. Языки программирования позволяют делать это на более высоком уровне. Например, рассмотрим это утверждение, написанное в Паскаль-как мода:
Человеку это кажется довольно простым и очевидным расчетом («один плюс два равно три, умноженный на пять равно пятнадцать»). Однако шаги низкого уровня, необходимые для выполнения этой оценки и возврата значения «15», а затем присвоения этого значения переменной «a», на самом деле довольно тонкие и сложные. Значения необходимо преобразовать в двоичное представление (часто гораздо более сложная задача, чем можно было бы подумать), а вычисления разложить (компилятором или интерпретатором) на инструкции сборки (опять же, которые гораздо менее интуитивно понятны для программиста: такие операции, как сдвиг двоичного регистра влево или добавление двоичного дополнения содержимого одного регистра к другому — это просто не то, как люди думают об абстрактных арифметических операциях сложения или умножения). Наконец, присвоение результирующего значения «15» переменной с меткой «а», чтобы «а» можно было использовать позже, включает в себя дополнительные «закулисные» шаги по поиску метки переменной и результирующего местоположения на физическом носителе. или виртуальная память, хранящая двоичное представление числа «15» в этой ячейке памяти и т. д.
Без абстракции управления программисту нужно было бы указать все шаги регистров / двоичного уровня каждый раз, когда они просто хотели сложить или умножить пару чисел и присвоить результат переменной. Такое дублирование усилий имеет два серьезных негативных последствия:
- это заставляет программиста постоянно повторять довольно обычные задачи каждый раз, когда требуется аналогичная операция
- он заставляет программиста программировать для конкретного оборудования и набора команд
Структурированное программирование
Структурированное программирование включает разделение сложных программных задач на более мелкие части с четким управлением потоком и интерфейсами между компонентами, с уменьшением сложности, потенциально возможной для побочных эффектов.
В простой программе это может быть направлено на обеспечение того, чтобы циклы имели единственные или очевидные точки выхода и (где возможно) имели единственные точки выхода из функций и процедур.
В более крупной системе это может включать разбиение сложных задач на множество различных модулей. Рассмотрим систему, которая обрабатывает заработную плату на кораблях и в береговых офисах:
- Самый верхний уровень может содержать меню типичных операций конечного пользователя.
- В нем могут находиться автономные исполняемые файлы или библиотеки для таких задач, как вход в систему и выход из нее или печать чеков.
- Внутри каждого из этих автономных компонентов может быть множество различных исходных файлов, каждый из которых содержит программный код для решения части проблемы, и только выбранные интерфейсы доступны для других частей программы. Программа входа в систему может иметь исходные файлы для каждого экрана ввода данных и интерфейса базы данных (который сам может быть отдельной сторонней библиотекой или статически связанным набором библиотечных подпрограмм).
- Либо база данных, либо приложение для расчета заработной платы также должны инициировать процесс обмена данными между судном и берегом, и эта задача передачи данных часто будет содержать множество других компонентов.
Эти уровни производят эффект изоляции деталей реализации одного компонента и его различных внутренних методов от других. Объектно-ориентированное программирование охватывает и расширяет эту концепцию.
Что пишут в блогах
- User story в тестировании: что это такое и как их составлять
- Как лучше организовать команду автоматизаторов в тестировании
- The State of Testing 2022 — часть 2
- The State of Testing 2022 — часть 1
- Типы руководителей по модели PAEI, их преимущества и минусы
- 50 оттенков DevOps
- Шесть причин проблем с требованиями в вашем проекте
- Тренды вакансий ИТ на HH.ru Апрель 2022
- Из туризма в тестирование ПО в 32 года: история Юлии
- Схема сопроводительного письма для тестировщика на английском + полезные фразы

§ 9. Определение. Мы уже не раз формулировали следующий принцип проектирования: «Одним из главных условий эффективного программирования является максимизация части программы, которую можно проигнорировать при работе над конкретными фрагментами кода» [Макконнелл 10]. Это вполне очевидное правило является одной из формулировок принципа сокрытия информации. Считается, что впервые он был сформулирован в 1970-х годах в работе [Парнас 16] 15 .
При этом мы отмечали, что всегда и на любом языке можно написать код, вполне удовлетворяющий принципу сокрытия информации. В конце концов, мы можем структурировать код с помощью комментариев. Другой вопрос в том, что крайне сложно добиться соблюдения этого принципа, если мы не опираемся на возможности языка. Основной такой возможностью является инкапсуляция – на уровне методов (процедурное программирование) или классов (объектно-ориентированное программирование). Именно инкапсуляция позволяет создавать в коде полноценные абстракции. Полноценные в том смысле, что пользователи этих абстракций (вызывающий код) ничего не знают и не могут знать о реализации используемой абстракции, то есть могут абстрагироваться от ненужных деталей, сосредоточившись только на необходимых. «Что мы хотим от абстракции – это механизма, который позволяет выражать существенные детали и скрыть несущественные детали. В случае программирования, то, как мы можем использовать абстракцию важно, а способ, которым абстракция реализована – неважен» [Лисков 9]. Следует ясно представлять соотношение обсуждаемых понятий: сокрытие информации, инкапсуляция и абстракция. «Сокрытие информации – это прежде всего вопрос проектирования программ; сокрытие информации возможно в любой правильно спроектированной программе вне зависимости от используемого языка программирования. Инкапсуляция, однако, это прежде всего вопрос разработки конкретного языка; абстракция может быть эффективно инкапсулирована только в том случае, если язык запрещает доступ к скрытой в абстракции информации.» [18]
Классы в том объеме технических возможностей, который мы обозначили в предыдущих параграфах, реализуют идею абстрактных типов данных. Приведем развернутое определение по [Пратт 18]:
Абстрактный тип данных – новый тип данных, определяемый программистом и включающий 1) определяемый программистом тип данных; 2) набор абстрактных операций над объектами этого типа; инкапсуляцию объектов этого типа таким образом, что пользователь нового типа не может манипулировать этими объектами, иначе как только с помощью определенных при разработке типа абстрактных операций.
Это вполне исчерпывающее и точное определение, хотя оно несколько устарело в части используемых терминов. Разберем его подробно. Первый элемент – «определяемый программистом тип данных» – это собственно перечень данных, хранимых объектами определяемого типа, то есть перечень полей класса. Такая формулировка обусловлена тем, что долгое время (этапы рассмотренной эволюции 1-2-3) под типом данных понималась исключительно структура без методов. Второй элемент – «набор абстрактных операций» – это набор методов класса, имеющих доступ к полям объекта. Абстрактная операция – это, в современной терминологии, метод. Отметим, что здесь слово «абстрактная», как и в термине «абстрактный тип данных» обозначает, что речь идет о некоторой абстракции предметной области 16 . Третье утверждение в определении – об инкапсуляции – описывает возможность объявления закрытых полей, к которым имеют доступ только методы класса. Отметим, что определение предполагает, что все поля всегда будут закрытыми. В этом смысле возможность объявления открытых полей является нарушением и отходом от «теоретически правильной» реализации. Далее мы увидим, что в большинстве случаев теория совпадает с практикой и такое нарушение нежелательно. Таким образом, можно переформулировать приведенное определение на современном языке:
Абстрактный тип данных (abstract data type) – новый тип данных, определяемый программистом и включающий 1) определяемый программистом перечень данных (полей типа); 2) набор методов, имеющих доступ ко всем полям типа; инкапсуляцию объектов этого типа таким образом, что пользователь нового типа не может манипулировать этими объектами, иначе как только с помощью определенных при разработки типа методов, то есть к полям типа имеют доступ только методы этого же типа.
В чем отличие класса и абстрактного типа данных? Можно ли сказать, что абстрактный тип данных – теоретическая концепция, а класс – это реализация этой концепции в языке программирования? С одной стороны, так и есть. Но, как мы уже говорили во введении, объектно-ориентированное программирование основывается на двух базовых идеях. Первая из них и есть абстрактные типы данных. А вторая – иерархические типы. Соответственно, сформулируем следующее определение:
Класс (class) в объектно-ориентированном программировании – это определяемый программистом тип данных, удовлетворяющий определениям: 1) абстрактного и 2) иерархического типа.
Детальному концептуальному и техническому разбору иерархических типов посвящен раздел 3 книги. В настоящем разделе, в последующих главах, мы подробно остановимся на технических возможностях, относящихся к абстрактным типам данных.
В заключение отметим, что основная специфика ООП связана именно с иерархическими типами данных, поэтому многие вопросы, рассматриваемые в настоящем разделе, имеют отношение и к другим парадигмам программирования и могут быть в той или иной мере знакомы читателю.
Низкоуровневые языки
Как я уже отметил выше, компьютер не умеет разговаривать по-английски. Общение с машиной происходит при помощи нулей и единиц. Мы буквально подаем ток на определенные транзисторы, чтобы превращать импульсы тока в слова, изображения на экране компьютера, сложные программы и видеоигры. Это наиболее рациональный с точки зрения производительности вариант взаимодействия с процессором, потому, используя двоичную систему, вы передаете команды напрямую: управляете памятью, перемещаете данные и т.п.
Но есть низкоуровневые языки, которые немного упрощают процесс общения с «железом» за счет преобразования часто используемых команды из 1011 в более удобоваримые директивы в духе MOV, AAD.
Такие языки строго оптимизируются под конкретные чипы и работают только на тех архитектурах, под которые они изначально разрабатывались.
Машинный язык
Это единственный язык, который понимает компьютер без какой-либо предобработки. Сейчас программисты его не используют, потому что он слишком сложный в восприятии. Есть масса более понятных аналогов, выполняющих те же функции, в то время как машинный язык очень сложный, требует куда больше времени и внимательности от специалиста и вообще никак не помогает в создании новых программ, а только усложняет эту задачу.

Машинный язык – это информация в чистом виде, зачастую представляющая собой набор чисел в двоичной системе исчисления (иногда используются десятичные и другие варианты). Разработчики должны прописывать каждую команду с помощью заранее предусмотренных запросов, четко следуя правилам написания инструкций для конкретного чипа, с которым работает программист.
Написанный машинный код передается в загрузчик программ напрямую, обычно игнорируя любые посреднические программные слои.
Языки ассемблера
Это первый уровень абстракции от машинного языка. Первая надстройка, упрощающая восприятие программного кода и помогающая разработчикам писать более стабильные приложения, практически не теряя в производительности.
Синтаксис языка ассемблера состоит не из нулей и единиц (и даже не из цифр с буквенными значениями, как в десятичной системе), а из вполне читаемых директив, которые похожи на сокращенные английские слова. Например MOV вместо 1011 отвечает за перемещение данных из одного регистра в другой.
Каждый язык ассемблера поставляется с собственным переводчиком, превращающим директивы на английском языке в директивы, которые умеет читать компьютер, то есть в машинный код. Этот переводчик называют ассемблером. И это одна из причин, почему ПО, написанное с использованием ассемблера работает медленнее, – компьютеру требуется время на перевод.
Уровень абстракции языка ассемблера довольно посредственный, потому что информация, которой манипулирует разработчик, хранится в регистрах процессора (специальных ячейках, где может храниться определенный объем данных), из-за чего формируется тесная взаимосвязь между написанным кодом и используемым железом. Без больших затрат по времени ретранслировать этот код под другую платформу или операционную систему не получится.
В отличие от машинного языка, язык ассемблера используется даже в современной разработке. В частности, для создания ПО, требующего очень высокой производительности, низкоуровневых системных компонентов или драйверов для аппаратной части устройств.
Краткое сравнение ассемблера и машинного языка
Машинный код
Язык ассемблера
Нулевой уровень абстракции. Полный контакт с аппаратной составляющей компьютера
Первый уровень абстракции. Есть прослойка в виде переводчика-ассемблера
Трудно понять, что написано в коде
Код больше похож на человеческий язык
Для запуска не нужны дополнительные инструменты
Требуется ассемблер для превращения кода в машинный язык
Синтаксис состоит из нулей и единиц
Синтаксис состоит из английских слов

Математика
Перейдём к более точным наукам. Математика сама по себе достаточно абстрактная штука, поэтому возьмём что-нибудь простое — числа.
Все началось с необходимости подсчитать количество нападающих волков и сравнить их с количество защищающихся людей, так что натуральные числа — это счётные числа: 1, 2, 3, 4 и так далее. Надо сказать, что число 3 само по себе достаточно абстрактное понятие. На самом деле, его не существует в природе. Есть 3 дерева или 3 барана, но числа 3 нет.
Далее умные индусы придумали число ноль. Долгое время 0 вообще в Европе не считали числом, а каким-то условным символом. Даже в 17 веке находились господа, которые ноль знать не хотели. Отрицательные числа ввели, чтобы было удобно записывать долги и решать некоторые уравнения. В итоге получили целые числа: -2, -1, 0, 1, 2
Всё бы хорошо, но иногда хочется что-то измерить. Например, длину отрезка. Для этого целых чисел будет недостаточно. На самом деле, если мой эталонный отрезок помещается в другом отрезке больше 1 но меньше 2 раз, то какая длина-то? На помощь приходят дроби. Делим один отрезок на другой и получаем дробь n/m. Такие числа называют рациональными.
Дальше сложно. Выяснилось, что есть числа, которые дробями не представишь. Например, число «пи» или квадратный корень из двух. Древним грекам данный факт выносил мозг, и они старательно не замечали таких чисел. Они называются иррациональными. Дать точное определение оказалось не так-то просто, вот Дедекинд смог.
Иррациональные числа гораздо сложнее представить, чем целые. В самом деле, что же такое Pi?
Но и это ещё не всё. Мы дошли до комплексных чисел, которые описываются в виде z = x + iy, где i — мнимая единица. К счастью, в наш просвещённый век комплексные числа учат в школе. Но, к несчастью, понимает их примерно 5% учеников.
Что мы имеем? Комплексные числа самые абстрактные и самые мощные. Из них можно вывести все другие числа. Кроме того, они наиболее сложны в понимании.
(Мы не будем трогать ещё более абстрактные кватернионы, октонионы и седенионы, потому что я их не знаю).











