Тема 2.1 данные и информация
Информация — это сведения о фактах, концепциях, объектах, событиях и идеях, которые в данном контексте имеют вполне определенное значение. Информация — это не просто сведения, а сведения нужные, имеющие значение для лица, обладающего ими.
Можно при определении понятия информации оттолкнуться от схематичного представления процесса ее передачи. Тогда под информацией будут пониматься любые сведения, являющиеся объектом хранения, передачи и преобразования. Информационное сообщение связано с источником сообщения (передатчиком), приемником (получателем) и каналом связи.
В одном терминологическом ряду с понятием информации стоят понятия «данные» и «знания».
Данные — это информация, представленная в виде, пригодном для обработки автоматическими средствами при возможном участии человека.
Знания — это информация, на основании которой путем логических рассуждений могут быть получены определенные выводы.
Важными характеристиками информации являются ее структура и форма. Структура информации определяет взаимосвязи между составляющими ее элементами. Среди основных форм можно выделить символьно-текстовую, графическую и звуковую формы. Основные требования, предъявляемые к экономической информации — точность, достоверность, оперативность, полнота.
Остановимся на понятии «данные». Все, что нас окружает, и с чем мы сталкиваемся, относится либо к физическим телам, либо к физическим полям. Все объекты находятся в состоянии непрерывного движения и изменения, которое сопровождается обменом энергией и ее переходом из одной формы в другую. Все виды энергообмена сопровождаются появлением сигналов. При взаимодействии сигналов с физическими телами в последних возникают определенные изменения свойств — это явление называется регистрацией сигналов. Такие изменения можно наблюдать, измерять или фиксировать теми или иными способами — при этом возникают и регистрируются новые сигналы, т. е. образуются данные».
Это определение принимает первичность и объективность существования данных, в том числе — независимость от субъекта их использующего. Но если существование данных не зависит от того, будут ли они когда-либо использованы или нет, эффективность функционирования многих процессов (имеющих контур управления) зависит от данных. Например, данные, используемые для изменения поведения процесса на основе построения прогноза (т. е. факты, характеризующие предшествующие состояния), позволят оптимизировать получение конечного результата, и будут уже выступать в роли управляющей информации. Роль и характер используемых данных в целом отражены на обобщенной схеме управляемого функционального процесса, представленной на рис.
Система преобразования ресурса, функциональность которой обусловлена проблемным контекстом (данными, представляющими целевую задачу), фактически преобразует и информацию. Потенциально полезные данные, выделенные из общегомножества в соответствии с контекстом задачи (исходная информация) в результате использования порождает выходную информацию — актуализированные данные, подтверждающие или отрицающие действенность выбранных исходных данных для решения задачи.
Рис. Обобщенная схема функционального процесса, управляемого данными
Компьютер является цифровым устройством, значит любая информация представляется в виде чисел.
Для записи чисел люди используют различные системы счисления. Система счисления показывает, по каким правилам записываются числа и как выполняются арифметические действия над ними.
Мы используем в обычной жизни десятичную систему записи чисел, когда число записывается с помощью 10 цифр (0,1…9). Для счета времени в часах используется двенадцатиричная система счисления, в минутах и секундах — шестидесятиричная система счисления. И это никого из нас не удивляет.
В компьютере для записи чисел используется двоичная система счисления, т.е. любое число записывается в виде сочетания двух цифр — 0 и 1. Почему? Просто двоичные числа проще всего реализовать технически: 0 — нет сигнала, 1 — есть сигнал (напряжение или ток).
И десятичная и двоичная системы счисления относятся к позиционным, т.е. значение цифры зависит от ее расположения в записи числа. Место цифры в записи числа называется разрядом, а количество цифр в числе — разрядностью числа. Разряды нумеруются справа налево, и каждому разряду соответствует степень основания системы счисления.
Минимальной единицей информации в компьютере является 1 бит — информация, определяемая одним из двух возможных значений — 0 или 1.
На практике используется более крупная единица информации — байт. Байт — это информация, содержащаяся в 8-разрядном двоичном коде: 1 байт = 8 бит.
В одном байте можно хранить целые числа (десятичные) от 0 до 255.
Для хранения действительных чисел используются ячейки из 4 или 8 байт. При этом число представляется в экспоненциальной форме: 275,986 = 0,275986 Е + 3.
При хранении действительного числа в ячейке из 4 байт 7 бит занимает порядок числа, а 25 бит — мантисса.
Компьютер всегда округляет действительные числа, представляя их приближенно. Для уменьшения погрешности вычислений используют представление чисел с двойной точностью, когда число храниться в ячейках памяти из 8 байт.
Любая информация, кроме числовой, в компьютере кодируется, т.е. представляется в виде чисел. Каким образом осуществляется кодировка информации? Рассмотрим представление текстовой информации.
В одном байте можно хранить 256 различных чисел (от 0 до 255). Для того чтобы закодировать прописные и строчные буквы латинского алфавита, необходимо 52 числа, а для русского алфавита необходимо еще 66 чисел. Кроме того, необходимо закодировать различные знаки препинания и специальные символы. Таблица такой кодировки носит название таблицы ASCII. Ее первая половина используется для хранения латинского алфавита и специальных символов, а вторая половина содержит символы псевдографики и буквы национальных алфавитов.
Для хранения больших объемов информации используются производные единицы измерения ее количества:
1 Кбайт = 1024 байт = 210 байт;
1 Мбайт = 1024 Кбайт = 210 Кбайт;
1 Гбайт = 1024 Мбайт = 210 Мбайт.
Если на одной странице текста содержится около 3000 знаков, то это 3 Кбайт информации, а в 1 Мбайт можно сохранить около 300 страниц текста.
Представление графической информации опирается на представление экрана монитора в виде массива цветовых точек размером MxN. Каждая точка имеет свой цвет, представляемый в виде комбинации оттенков трех основных цветов: красного, синего и зеленого. Для того чтобы цветопередача была приближена к реальной, необходимо не менее 256 оттенков каждого цвета. При представлении экрана монитора в виде массива 800×600 точек экран покрывает 480000 точек. Используя 8-битное кодирование каждого цвета, получим: 8x3x480000= 1 х 107 бит — 1,12 Мбайт.
В двоичном виде также можно закодировать и звуковую информацию.
1.Дайте определения следующим терминам: «Информация», «Знания».
2. Назовите виды данных.
3.Какие системы счисления вы знаете?
База данных — это.
Вы можете и не подозревать, что такое базы данных, но на самом деле вы пользуетесь ими почти каждый день. Как только вы собираетесь найти нужную информацию в поисковой системе, вы прибегаете к помощи баз данных.
То же самое происходит в момент, когда вы набираете логин и пароль при авторизации на сайте: введенные пользователем значения сравниваются с тем, что хранится в базе сервиса. В случае совпадения данных вы получаете доступ к сайту.
Если вводимые логин и пароль не совпадают с тем, что уже хранится в БД, система выдаст ошибку и попросит снова ввести данные для авторизации.
Несмотря на ежедневное использование баз данных, многие люди не понимают, что это такое и для чего они нужны. А все потому, что под этим определением подразумевается сразу несколько значений, отражающих субъективное мнение авторов. При этом общепризнанного универсального определения понятия пока не существует.
Согласно порталу Глоссарий:
база данных — это организованная структура, которая предназначается для хранения, обработки и изменения большого количества информации.
Она используется, например, в динамических сайтах (как, например, этот), оперирующих значительными объемами данных: порталах, интернет-магазинах, корпоративных сайтах. Такие проекты разрабатываются при помощи серверного языка программирования (пример — PHP) или на основе CMS (это как?) по типу WordPress или Joomla.
Динамические сайты, в отличие от HTML-аналогов, не имеют готовых страничек. Их структура создается на ходу благодаря взаимодействию скриптов и баз данных после конкретного запроса от пользователя.
Классификация банков и баз данных
Банк данных — это система специальным образом организованных баз данных, программных, технических, языковых и организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
База данных — это поименованная совокупность взаимосвязанных данных, находящихся под управлением СУБД. Комплекс программных и языковых средств: СУБД — сложный комплекс, обеспечивающий взаимодействие всех частей информационной системы при ее функционировании. Сюда входят организация ввода, обработка и хранение данных, а также средства настройки системы и ее тестирования. Языковые средства обеспечивают интерфейс пользователя с БД.
Классификация баз и банков данных может быть произведена по разным признакам.
- 1. По форме представляемой информации можно выделить фактографические, документальные, мультимедийные, в той или иной степени соответствующе цифровой, символьной и другим (нецифровой и несимвольной) формам представления информации и вычислительной среде.
- 2. По типу хранимой (не мультимедийной) информации можно выделить фактографические, документальны, лексикографические БД. Лексикографические — классификаторы, модификаторы, словари основных слов, тезаурусы, рубрикаторы и т.д. Документальные — полнотекстовые («первичные» документы) и библиографическо-реферативные («вторичные» документы, отражающие на адресном и содержательном уровнях первичный документ).
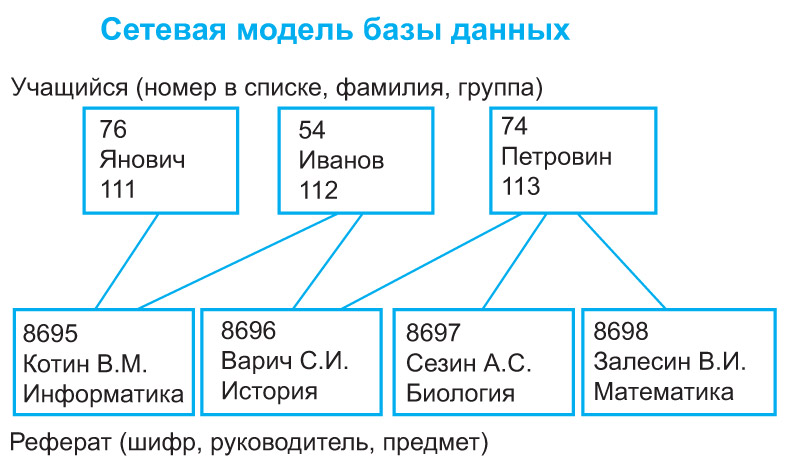
- 3. По типу используемой модели данных — иерархические, сетевые, реляционные.
- 4. По типологии хранения — локальные и распределенные.
- 5. По типологии доступа и характеру использования хранимой информации — специализированные и интегрированные.
- 6. По функциональному назначению (характеру решаемых задач и, соответственно, характеру использования данных) — операционные и справочно-информационные. К последним относятся ретроспективные БД (электронные каталоги библиотек), которые используются для информационной поддержки основной деятельности и не предполагают внесения изменений в уже существующие записи, например, по результатам этой деятельности. Операционные БД предназначены для управления различными технологическими процессами.
- 7. По сфере возможного применения можно различать универсальные и специализированные (или проблемно-ориентированные) системы.
- 8. По степени доступности можно выделить общедоступные и БД с ограниченным доступом пользователей.
Следует отметить, что представленная классификация не является полной и исчерпывающей.
Классификация баз данных БД разделяются: по модели представления данных (по связи между данными) по организации хранения данных и обращения к ним по типу хранимой информации.
Классификация БД по модели представления данных:
иерархическая БД — база данных, в которой связь между элементами осуществляется по типу подчинения и схематично изображается в виде дерева. Иерархия начинается с корневого узла. Каждый узел имеет только одного «предка» и N «потомков». (+) простота и однозначность представления, легкость адресации (-) существенная зависимость от программно — аппаратных средств.
сетевая БД — возможно существование любых взаимосвязей между объектами. Если изобразить эту модель графически, то получится набор узлов на плоскости, связанных линиями со стрелками. (+) теоретически возможны сколь угодно сложные связи между объектами; (-) сложность реализации, существенная зависимость от программно-аппаратных средств.
реляционная БД — представление данных в виде системы взаимосвязанных таблиц. Каждый объект системы описывается в виде таблицы с набором свойств (атрибутов), а взаимосвязь между объектами — связями между таблицами. (+) простота; относительная независимость от программных и аппаратных средств; (-) существенная зависимость скорости обработки от объема БД Использование: все существующие СУБД.
Реляционные СУБД осуществляют: работу с базой данных через экранные формы; организацию запросов на поиск данных с помощью специальных языков запросов высокого уровня; генерацию отчётов различной структуры данных с подведением промежуточных и окончательных итогов; вычислительную обработку путём использования встроенных функций, программ, написанных с использованием языков программирования и макрокоманд.
Классификация БД по организации хранения данных и обращения к ним: локальные (персональные), сетевые (интегрированные), распределенные базы данных.
Классификация БД по типу хранимой информации: документальные, фактографические, лексикографические. Среди документальных БД различают библиографические, реферативные и полнотекстовые. К лексикографическим БД относятся различные словари (классификаторы, многоязычные словари, словари основ слов и т.п.).
Остановимся на классификации банков информации. Эта классификация может быть проведена с разных точек зрения. По назначению можно выделить следующие классы банков информации Могилев А.В., Пак Н.И., Хённер Е.К. Информатика. 2-е изд. Учеб. пособие. — М: Изд. центр Академия, 2003. — С. 108. :
информационно-справочные системы (общего назначения и специализированные);
банки данных в автоматизированных системах управления (предприятий и организаций, технологическими процессами и т.д.);
банки данных в системах автоматизации научных исследований.
Однако такая классификация является не вполне строгой и завершенной. По режиму функционирования можно рассматривать банки информации пакетного, диалогового и смешанного типов, В связи с широким распространением персональных компьютеров, локальных и глобальных сетей ЭВМ подавляющее распространение получили диалоговые системы.
По архитектуре вычислительной среды различают централизованные и распределенные банки информации.
К настоящему времени сложились следующие три основных типа банков информации: банки документов, банки данных и банки знаний.
Модели памяти
Директива .MODEL определяет модель памяти, используемую программой. После этой директивы в программе находятся директивы объявления сегментов ( .DATA, .STACK, .CODE, SEGMENT ). Синтаксис задания модели памяти
.MODEL модификатор МодельПамяти СоглашениеОВызовах
Параметр МодельПамяти является обязательным.
Основные модели памяти:
| Модель памяти | Адресация кода | Адресация данных | Операци- онная система |
Чередование кода и данных |
| TINY | NEAR | NEAR | MS-DOS | Допустимо |
| SMALL | NEAR | NEAR | MS-DOS, Windows | Нет |
| MEDIUM | FAR | NEAR | MS-DOS, Windows | Нет |
| COMPACT | NEAR | FAR | MS-DOS, Windows | Нет |
| LARGE | FAR | FAR | MS-DOS, Windows | Нет |
| HUGE | FAR | FAR | MS-DOS, Windows | Нет |
| FLAT | NEAR | NEAR | Windows NT, Windows 2000, Windows XP, Windows Vista | Допустимо |
Модель tiny работает только в 16-разрядных приложениях MS-DOS. В этой модели все данные и код располагаются в одном физическом сегменте. Размер программного файла в этом случае не превышает 64 Кбайт.
Модель small поддерживает один сегмент кода и один сегмент данных. Данные и код при использовании этой модели адресуются как near (ближние).
Модель medium поддерживает несколько сегментов программного кода и один сегмент данных, при этом все ссылки в сегментах программного кода по умолчанию считаются дальними (far), а ссылки в сегменте данных — ближними (near).
Модель compact поддерживает несколько сегментов данных, в которых используется дальняя адресация данных (far), и один сегмент кода с ближней адресацией (near).
Модель large поддерживает несколько сегментов кода и несколько сегментов данных. По умолчанию все ссылки на код и данные считаются дальними (far).
Модель huge практически эквивалентна модели памяти large.
Особого внимания заслуживает модель памяти flat , которая используется только в 32-разрядных операционных системах. В ней данные и код размещены в одном 32-разрядном сегменте. Для использования в программе модели flat перед директивой .model flat следует разместить одну из директив:
Желательно указывать тот тип процессора, который используется в машине, хотя это не является обязательным требованием. Операционная система автоматически инициализирует сегментные регистры при загрузке программы, поэтому модифицировать их нужно только в случае если требуется смешивать в одной программе 16-разрядный и 32-разрядный код. Адресация данных и кода является ближней ( near ), при этом все адреса и указатели являются 32-разрядными.
Параметр модификатор используется для определения типов сегментов и может принимать значения use16 (сегменты выбранной модели используются как 16-битные) или use32 (сегменты выбранной модели используются как 32-битные).
Параметр СоглашениеОВызовах используется для определения способа передачи параметров при вызове процедуры из других языков, в том числе и языков высокого уровня (C++, Pascal). Параметр может принимать следующие значения:
При разработке модулей на ассемблере, которые будут применяться в программах, написанных на языках высокого уровня, обращайте внимание на то, какие соглашения о вызовах поддерживает тот или иной язык. Используются при анализе интерфейса программ на ассемблере с программами на языках высокого уровня.
Информационные технологии. 10 класс (Базовый уровень)
Основой современных информационных технологий являются данные. Практически все информационные системы в той или иной степени связаны с функциями долговременного хранения и обработки данных. Информация является фактором, определяющим эффективность любой сферы деятельности.
Данные, предназначенные для компьютерной обработки, целесообразно структурировать, т. е. организовывать определенным образом. Именно структурирование позволяет пользователю оптимизировать работу с данными (сократить время поиска, обеспечить эффективное хранение, исключить ошибки при обработке).
База данных (БД) — совокупность взаимосвязанных и организованных определенным образом данных.
Базы данных можно классифицировать исходя из способов организации их хранения и обработки:
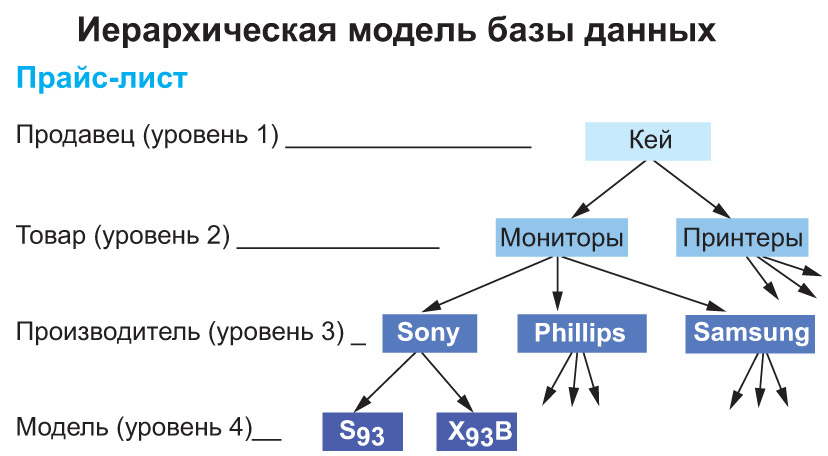
1. Иерархическая. Такую модель можно изобразить в виде дерева, состоящего из объектов различных уровней.
2. Сетевая. Является обобщением иерархической, т. е. каждый элемент вышестоящего уровня может быть связан с любыми элементами следующего уровня.
3. Реляционная. В такой модели данные организованы в виде таблиц, между которыми установлены связи.
Рассмотрим реляционные БД, как наибольший распространенный в сегодняшнее время.
Таблицы состоят из строк и столбцов. В таблицах баз данных — это записи и поля.
Запись — строка таблицы базы данных, содержащая данные об одном объекте.
В таблице из примера 1.1 пять записей и каждая запись содержит данные об определенном киносеансе.
Поле — столбец таблицы базы данных, в котором указываются значения определенного свойства объектов базы данных.
В таблице из примера 1.1 (п. 3) четыре поля: «Кинотеатр», «Фильм», «Время», «Стоимость».
Взаимодействие с базами данных лежит в основе функционирования многих ресурсов в Интернете.
Электронный школьный журнал работает с базой данных, содержащей информацию о педагогическом коллективе учреждения образования, об учащихся, классах, учебных предметах, отметках и т. д.
Доступ к базе данных необходим при оплате товаров в супермаркете, когда кассир считывает штрих-код с покупок, а также при поиске товаров в интернет-магазинах.
При посещении Национальной библиотеки обычно приходится обращаться к базе данных, содержащей сведения обо всех книгах, имеющихся в этой библиотеке, о ее читателях, заявках на бронирование книг и т. д.
В спорте тренеры используют базы данных , чт обы разрабатывать стратегию игры, программы питания и тренировок спортсменов или планировать виды взаимодействия с болельщиками.
Пример 1.1. Классификация баз данных.
3. Таблица реляционной БД.


Франк Кодд (23 августа 1923 г. — 18 апреля 2003 г.) — британский ученый, труды которого заложили основы теории реляционных баз данных. Работая в компании IBM, он установил правила, определяющие базу данных как реляционную.