Человек и компьютер: сможет ли искусственный интеллект «осознать прочитанное»
Спрос на технологии Natural Language Processing (NLP) возрастает во многих сферах: образование, финансы, государственный сектор, здравоохранение, телекоммуникации, ритейл, юридическая практика. Тренды и барьеры в развитии NLP обсудили эксперты онлайн-конференции «Нас слышат, видят, реагируют: куда движутся технологии?». Мы собрали самые интересные фрагменты выступлений спикеров.
Конференция приурочена к презентации нового Технологического конкурса Up Great ПРО//ЧТЕНИЕ, организованного РВК, Фондом «Сколково» и АСИ. Технический партнер конкурса — Центр компетенций НТИ по направлению «Искусственный интеллект» на базе МФТИ.
Иван Ямщиков, научный сотрудник Института Макса Планка, ИИ-евангелист компании ABBYY: Один из ярчайших философов науки XX века Карл Поппер выдвинул принцип: теория является научной, если существует методологическая возможность её опровержения путём постановки того или иного эксперимента. И сегодня в машинном обучении, особенно в работе с текстами, происходит примерно вот что: у нас есть сильные теоретические разработки, но эксперименты сходятся с ними не всегда.
У нас есть немало разных способов и метрик, чтобы оценить, насколько хороши наши модели ИИ. Но что именно происходит на самом деле в наших головах, когда мы обмениваемся звуками или текстами и коммуницируем, – настоящая загадка. Поэтому обучить ИИ общаться с человеком так, как это делаем мы сами, невероятно сложно.
Если говорить о технических особенностях работы ИИ с текстами, то мы знаем, что проблему может вызвать даже простая конструкция «Вася ел борщ, он был горячий». Кто был горячим, Вася или борщ? Человек догадывается из контекста. Компьютер – не всегда. В рамках конкурса ПРО//ЧТЕНИЕ участникам в некотором смысле предстоит прыгнуть выше головы, решив некоторые очень сложные задачи, связанные с анализом естественного языка.
Вот несколько примеров задач в области NLP, решение которых будет очень ценным для всей области машинного обучения.
- Вопрос предсказуемости реального мира на основании вашей модели ИИ . Ваша модель может быть прекрасной в теории, но нерабочей на практике в реальном мире. Здесь ключевыми могут оказаться вопросы балансировки вашего датасета.
- Вопрос понимания нарратива и сюжета . Современные модели ИИ очень плохо понимают, что это такое. Восстанавливать причинно-следственные связи сложно. Важно понимать, что нарратив – фундаментальная специфика человеческой психики. Машины сегодня плохо воспринимают и извлекают сюжеты.
- Язык как средство социальной демаркации – ИИ должен понимать нюансы . Простой пример: как называют границу между Израилем и Палестиной в англоязычных медиа арабы и евреи. Для одних – это «ограждение безопасности». Для других – «стена апартеида». Люди используют язык как способ культурной, политической и общественной демаркации, усложняя задачу искусственному интеллекту многообразием точек зрения на одни и те же объекты, явления и ситуации.
- Сложность применения теории информации . Любой текст со временем может менять свои состояния: рассказ может трансформироваться в мем, новость может оказаться фейком и так далее. ИИ должен «чувствовать» контекст.
Кирилл Левин, директор научно-исследовательского департамента группы компаний ЦРТ: Группа ЦРТ уже 30 лет создает, развивает и совершенствует технологии на основе ИИ и машинного обучения, которые позволяют обеспечить адекватное взаимодействие человека и машины. Благодаря такой экспертизе, сегодня мы имеем одни из лучших ASR и TTS – распознавание и синтез речи, а наши чат-боты и голосовые интеллектуальные помощники успешно применяются для оптимизации работы крупных банковских институтов, ретейла и телекома.
Расскажу о нашем опыте и наших методах в работе с NLP. Как достичь практической пользы от слабого Natural Language Understanding (NLU)? Например, у нас есть два способа действий, когда мы создаем NLU чат-бот, который способен давать ответы на вопросы из сферы технической поддержки, на типовые вопросы о товаре и так далее.
Первый способ – выстроить решающие правила, основанные на опыте того, как человек понимает контекст. Второй способ – построить автоматическую систему с использованием Machine Learning и различных нейронных сетей. В любом случае нам понадобится очень много данных. А если учесть, что одни и те же явления люди воспринимают по-разному, то на практике вы можете получить совершенно неприменимый в реальной жизни результат.
Сложно надеяться на создание в ближайшее время продукта, который по качеству анализа текста догонит живого человека. Поэтому необходимо по-другому отнестись к технологиям NLP. Не нужно стремиться доработать функции ИИ до уровня человека, тем более эксперта. Наша задача должна заключаться в том, чтобы создавать инструменты, способные помогать человеку и экономить его время. То есть система должна выдавать эксперту несколько релевантных подсказок с вариантами, один из которых он может выбрать.
Михаил Бурцев, заведующий лабораторией нейронных систем и глубокого обучения, МФТИ: Что произошло в сфере NLP за последние два года? Смещение координат. Если первая волна развития ИИ была связана с компьютерным зрением, то сегодня интерес повсеместно смещается в область задач обработки естественного языка.
Какие задачи решают NLP-разработки? Самая простая – классификация предложений. ИИ уже способен общаться с человеком и распознавать его намерения: забронировать столик, узнать прогноз погоды, послушать музыку и так далее. Вторая задача – разметка последовательностей. ИИ способен находить в тексте, например, нужные даты, названия организаций и иные заданные объекты. Третья задача – предсказание продолжения последовательности или генерация последовательности. К примеру, у нас есть фраза и мы хотим сгенерировать ответ на нее. Мы можем натренировать нашу модель, и она будет предсказывать варианты развития диалога. Это типовые задачи, из которых далее вырастают сложные проекты.
За последние два года подход к функциям NLP-решений существенно изменился. C появлением и распространением алгоритмов глубоких нейронных сетей ИИ стало легче обучать. Но и задачи становятся всё сложнее. Эволюция в этой области выглядит примерно так: от применения простых рекуррентных нейронных сетей до самого продвинутого на сегодня так называемого алгоритма Transformer – это гибрид Encoder – Attentionсо свёрточными нейронными сетями, которые позволяют нейросети выучить различные отношения между словами в предложении или тексте.
Какие задачи нужно решить для создания разговорного искусственного интеллекта? Необходимо добиться более глубокого понимания диалога, то есть отойти от решения лишь частных задач. Сегодня в мире активно ведутся исследования в таких направлениях, как генерация нескольких альтернативных гипотез, отбор и оценка этих гипотез. Эта базовая часть, связанная с пониманием языка, на данный момент относительно отработана уже созданными языковыми моделями. Но следующий шаг, после того как мы разберемся с четким пониманием текущего контекста, будет связан с перспективой, с пониманием более стратегического диалога, когда нам наверняка придется моделировать нашего собеседника, планировать диалог, составлять сценарии диалога на будущее.
Константин Кайсин, операционный директор технологических конкурсов Up Great, РВК: Есть большая вероятность, что следующий скачок развития ИИ в России и в мире будет связан с технологиями NLP – с возможностью человека и компьютера общаться друг с другом напрямую, взаимно обучаться и развиваться. Для этого необходимо, чтобы компьютер мог «говорить» на естественном человеческом языке, чтобы он мог на самом деле понимать, о чем повествуется в «живом» тексте. И достижение этого прорыва является основной целью конкурса ПРО//ЧТЕНИЕ.
Также целью конкурса является создание открытого бенчмарка для оценки технологий ИИ и анализа текста. Созданная нами система оценки позволит сравнивать качество работы различных решений и подстегнет конкуренцию и развитие таких решений. Система будет располагаться в открытом доступе.
Также мы хотим, чтобы разработки участников конкурса, ориентированные на долгосрочную перспективу, начали внедряться в России уже в ближайшее время, и будем активно этому содействовать. В первую очередь, от этого конкурса должна выиграть сфера образования. Мы создаем условия конкурса, максимально приближенные к реальным.
Юрий Молодых, директор по развитию технологических конкурсов Up Great, РВК: Модель ИИ, которая сможет победить в данном конкурсе, должна будет научиться выявлять и анонсировать ошибки в текстах на уровне преподавателя, имеющего на проверку текста объемом до 12 000 знаков не более 10 минут. Ограничение по времени для работы ИИ составит 30 секунд на один текст. На текущий момент никто в мире еще не показал таких результатов.
Технология, способная продемонстрировать такой уровень проверки «живого» текста, позволит использовать разработку и как систему поддержки решений преподавателя, и как отдельный тренажер для школьников и студентов.
В конкурсе будут использованы тексты, написанные в рамках обучения по следующим предметам: русский язык, литература, обществознание, история, английский язык. Соревнования будут организованы отдельно для текстов на русском и английском языке. Призовой фонд каждого конкурса составляет по 100 млн рублей. Мы также будем предлагать для участников различные программы поддержки.
Константин Воронцов, доктор физико-математических наук, заведующий лабораторией машинного интеллекта МФТИ: Лаборатория машинного интеллекта МФТИ понимает конкурсную задачу состязания ПРО//ЧТЕНИЕ так: создать ИИ для поиска смысловых ошибок в тексте. Для нас, как для технического партнера конкурса, важно было разобраться, что такое смысловые ошибки и как будут обучаться модели ИИ участников конкурса – необходима обширная база размеченных текстов (то есть текстов, проверенных преподавателями).
Каждый текст будет проверен несколькими преподавателями. Если окажется, что средняя точность алгоритмической разметки, которую составит модель ИИ хотя бы одной из команд-участниц конкурса, превышает среднюю точность экспертной разметки, это и станет преодолением технологического барьера и победой в испытании.
Подать заявку и получить подробную информацию о конкурсе ПРО//ЧТЕНИЕ можно по адресу: ai.upgreat.one
Человек, информация, знания
Обо всех изменениях в окружающем мире человек узнает с помощью своих органов чувств: сигналы от них («первичная» информация) постоянно поступают в мозг. Чтобы понять эти сигналы, т. е. извлечь информацию, человек использует знания — свои представления о природе, обществе, самом себе. Знания позволяют человеку принимать решения, определяют его поведение и отношения с другими людьми.
Можно считать, что знания — это модель мира, которая есть у человека. Получив информацию («поняв» сигналы, поступившие от органов чувств), он корректирует эту модель, дополняет свои знания.
Всегда ли полученная информация увеличивает наши знания? Очевидно, что нет. Например, информация о том, что 2 • 2 = 4 вряд ли увеличит ваши знания, потому что вы это уже знаете, эта информация для вас не нова. Однако она будет новой для тех, кто изучает таблицу умножения. Это значит, что изменение знаний при получении сообщения зависит от того, что человек знал до этого момента. Если он знает всё, что было в полученном сообщении, знания не изменяются.
Вместе с тем сообщение «Учёт вибронных взаимодействий континуализирует моделирование диссипативных структур» (или сообщение на неизвестном языке) также не увеличивает знания, потому что эта фраза, скорее всего, вам непонятна. Иначе говоря, имеющихся знаний не хватает для того, чтобы воспринять новую информацию.
Эти идеи послужили основой семантической (смысловой) теории информации, предложенной в 60-х годах XX века советским математиком Ю. А. Шрейдером. На рисунке 1.2 показано, как зависит количество полученных знаний I от того, какая доля информации 0 в сообщении уже известна получателю.
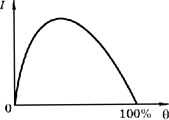
Рис. 1.2

Сообщение увеличивает знания человека, если оно понятно и содержит новые сведения.
К сожалению, «измерить» смысл информации, оценить его числом, довольно сложно. Поэтому для оценки количества информации используют другие подходы, о которых вы узнаете чуть позже.
Когда человек хочет поделиться с кем-то своим знанием, он может сказать: «Я знаю, что. » или «Я знаю, как. ». Это говорит о том, что есть два разных вида знаний. В первом случае знания — это некоторый известный факт, например: «Я знаю, что Луна вращается вокруг Земли». Такие знания называются декларативными, человек выражает их словами (декларирует). Декларативные знания — это факты, законы, принципы.
Второй тип знаний («Я знаю, как. ») называют процедурными. Они выражаются в том, что человек знает, как нужно действовать в той или иной ситуации. К процедурным знаниям относятся алгоритмы решения различных задач.
Для того чтобы сохранить знания и передать другим людям, нужно выразить их на каком-то языке (например, рассказать, записать, нарисовать и т. п.). Только после этого их можно хранить, обрабатывать, передавать, причём с этим может справиться и компьютер. В научной литературе информацию, зафиксированную (закодированную) в какой-то форме, называют данными, имея в виду, что компьютер может выполнять с ними какие-то операции, но не способен понимать смысл.
Для того чтобы данные стали информацией, их нужно понять и осмыслить, а на это способен только человек. Если человек, получающий сообщение, знает язык, на котором оно записано, он может понять смысл этого сообщения, т. е. получить информацию. Обрабатывая и упорядочивая информацию, человек выявляет закономерности — получает знания.
Мы увидели, что в науке существуют достаточно тонкие различия между понятиями «данные», «информация», «знания». Тем не менее на практике чаще всего всё это называется общим термином «информация».
Свойства информации
В идеале информация должна быть:
• объективной (не зависящей от чьего-либо мнения);
• понятной для получателя;
• полезной (позволяющей получателю решать свои задачи);
• достоверной (полученной из надёжного источника);
• актуальной, (значимой в данный момент);
• полной (достаточной для принятия решения).

Конечно, информация не всегда обладает всеми этими свойствами. Информация в сообщении «В стакане мало молока» необъективна (для пессимиста полстакана — это мало, а для оптимиста — много). Сообщение непонятно для не знающих японский язык (оно означает «Я пошёл гулять», только по-японски).
Полезность информации определяется для каждого человека в конкретной ситуации. Например, информация о том, как древние люди добывали огонь, для большинства городских жителей бесполезна, поскольку она никак не помогает им решать свои жизненные проблемы. Вместе с тем в экстремальной ситуации, когда человек оказывается один на один с природой, такие знания очень полезны, потому что сильно увеличивают шансы на выживание, т. е. помогают достичь цели.
Слухи, байки, искажённая информация (в том числе дезинформация) — это примеры недостоверной информации.
Сообщение «10 лет назад здесь был ларёк с мороженым» неактуально, эта информация устарела.
Информация в сообщении «Сегодня будет концерт» неполна, потому что не указано время и участники концерта, и из-за этого мы не можем принять решение (идти или не идти?).
Развитие глобальной сети Интернет, в которую ежеминутно вносится огромное количество самых разнообразных данных, во многом перевернуло привычные представления о работе с информацией. Например, основным источником для поиска учебных материалов теперь фактически является Интернет, а не библиотеки. Однако при использовании информации из Интернета необходимо относиться к ней критически, так как её достоверность никто не гарантирует.
Роль информации в человеческом обществе очень велика. Информация, получаемая нами из разных источников, позволяет принимать решения и во многом определяет всю нашу жизнь. Огромно влияние на общество средств массовой информации (СМИ) — газет, телевидения, изданий в Интернете.
В будущем ожидается переход к информационному обществу, где большая часть населения будет заниматься сбором, обработкой и распространением информации, поэтому высказывание немецкого банкира Н. Ротшильда «Кто владеет информацией, тот владеет миром» становится актуальным как никогда.
Информация в технике
Практически все современные технические устройства (телевизоры, телефоны, стиральные машины, системы управления самолётами и судами и т. д.) строятся на микропроцессорах, которые обрабатывают информацию: анализируют сигналы с датчиков, выбирают нужный режим работы. Широко используются системы программного управления, например станки, обрабатывающие детали по программе, заложенной в памяти. Эту программу очень легко поменять и настроить станок на изготовление другой детали.

Многие опасные, тяжёлые и утомительные работы за человека могут выполнить роботы, у которых датчики заменяют органы чувств. Например, человекоподобный робот (андроид) Asimo (рис. 1.3), разработанный фирмой Honda, умеет распознавать предметы, жесты, звуки, узнавать лица, разговаривать через домофон, передавать данные через Интернет.
Рис. 1.3. Робот Asimo (www.robotonline.net)
Наиболее универсальным устройством для обработки информации можно считать компьютер. Хотя современные компьютеры пока не умеют работать с вкусовой и обонятельной информацией (запахами), работы в этом направлении ведутся. Уже существуют экспериментальные приборы, названные «электронный нос» и «электронный язык»; они построены на основе химических датчиков.
Сейчас в теоретической информатике считается, что компьютер может хранить и обрабатывать только данные, но не информацию. Многие учёные полагают, что машина принципиально не может научиться понимать смысл информации и делать выводы 1 . Эту точку зрения подтверждает фактический провал проекта «компьютеров пятого поколения» (Япония, 1980-е гг.), в ходе которого планировалось создать машины, общающиеся с человеком на естественном языке. Тем не менее учёные уделяют этим проблемам огромное внимание. Например, возникло целое научное направление data mining («добыча данных»), в котором изучаются методы извлечения информации («смысла», закономерностей, связей, знаний) из огромных наборов данных. В некоторых случаях действительно удаётся использовать огромные вычислительные мощности компьютеров для того, чтобы найти неизвестные ранее закономерности, которые можно использовать на практике.
1 Тем не менее суперкомпьютер Watson фирмы IBM, умеющий отвечать на вопросы, заданные на естественном языке, в 2011 г. выиграл у лучших игроков в телевизионной викторине Jeopardy! (аналог телепередачи «Что? Где? Когда?»).
Вопросы и задания
1. Что изучает информатика?
2. Какие научные направления обычно включают в информатику?
3. Что такое искусственный интеллект?
4. Как связана неопределённость знания с получением информации?
5. Как связана информация и сложность объекта?
6. Объясните, почему термин «информация» трудно определить.
7. Согласны ли вы с «определением» информации, которое дал Н. Винер? Как вы его понимаете?
8. Как человек воспринимает информацию?
9. Чем отличается текст от набора символов?
10. К какому виду информации относятся видеофильмы?
11. Что такое тактильная информация?
12. Всякая ли информация увеличивает знания? Почему?
13. На каких идеях основана семантическая теория информации?
14. Приведите примеры своих декларативных и процедурных знаний.
15. В чём, на ваш взгляд, разница между понятиями «данные», «информация», «знания»?
16. Почему считают, что компьютер может работать только с данными?
17. Какими свойствами должна обладать «идеальная» информация?
18. Приведите примеры необъективной, непонятной, бесполезной, недостоверной, неактуальной и неполной информации.
19. Может ли информация быть достоверной, но бесполезной? Достоверной, но необъективной? Объективной, но недостоверной? Актуальной, но непонятной?
20. Приведите примеры обработки информации в технических устройствах.
21. Что умеет робот Asimo? Какую информацию он обрабатывает?
22. Что такое «электронный нос» и «электронный язык»?
23. Как вы считаете, смогут ли компьютеры научиться понимать смысл данных?
Подготовьте сообщение
а) «Информация в жизни общества»
б) «Интернет и изменение уклада жизни людей»
в) «Информационное общество: плюсы и минусы»
г) «Как оценить смысл информации?»