Все о Data Science: описание, особенности, как стать специалистом

Данные – то, что нужно не только грамотно обрабатывать, но еще и собирать, а также хранить. С развитием информационных технологий люди стали задумываться над тем, каким образом справиться с поставленными задачами с максимальной эффективностью. Так появилось совершенно новое направление, которое называется Data Science.
Люди, решившие стать специалистами в соответствующей области сегодня высоко ценятся. Но не совсем понятно, кто это, а также чем занимаются подобные «ученые». В данной статье будет раскрыта тайна Дата Науки.
Что изучает Data Science
Каждый день человечество генерирует примерно 2,5 квинтиллиона байт различных данных. Они создаются буквально при каждом клике и пролистывании страницы, не говоря уже о просмотре видео и фотографий в онлайн-сервисах и соцсетях.
Наука о данных появилась задолго до того, как их объемы превысили все мыслимые прогнозы. Отсчет принято вести с 1966 года, когда в мире появился Комитет по данным для науки и техники — CODATA. Его создали в рамках Международного совета по науке, который ставил своей целью сбор, оценку, хранение и поиск важнейших данных для решения научных и технических задач. В составе комитета работают ученые, профессора крупных университетов и представители академий наук из нескольких стран, включая Россию.
Сам термин Data Science вошел в обиход в середине 1970-х с подачи датского ученого-информатика Петера Наура. Согласно его определению, эта дисциплина изучает жизненный цикл цифровых данных от появления до использования в других областях знаний. Однако со временем это определение стало более широким и гибким.
Data Science (DS) — междисциплинарная область на стыке статистики, математики, системного анализа и машинного обучения, которая охватывает все этапы работы с данными. Она предполагает исследование и анализ сверхбольших массивов информации и ориентирована в первую очередь на получение практических результатов.
В 2010-х годах объемы данных стали расти по экспоненте. Свою роль сыграл целый ряд факторов — от повсеместного распространения мобильного интернета и популярности соцсетей до всеобщей оцифровки сервисов и процессов. В итоге профессия дата-сайентиста быстро превратилась в одну из самых популярных и востребованных. Еще в 2012 году позицию дата-сайентиста журналисты назвали самой привлекательной работой XXI века (The Sexiest Job of the XXI Century).
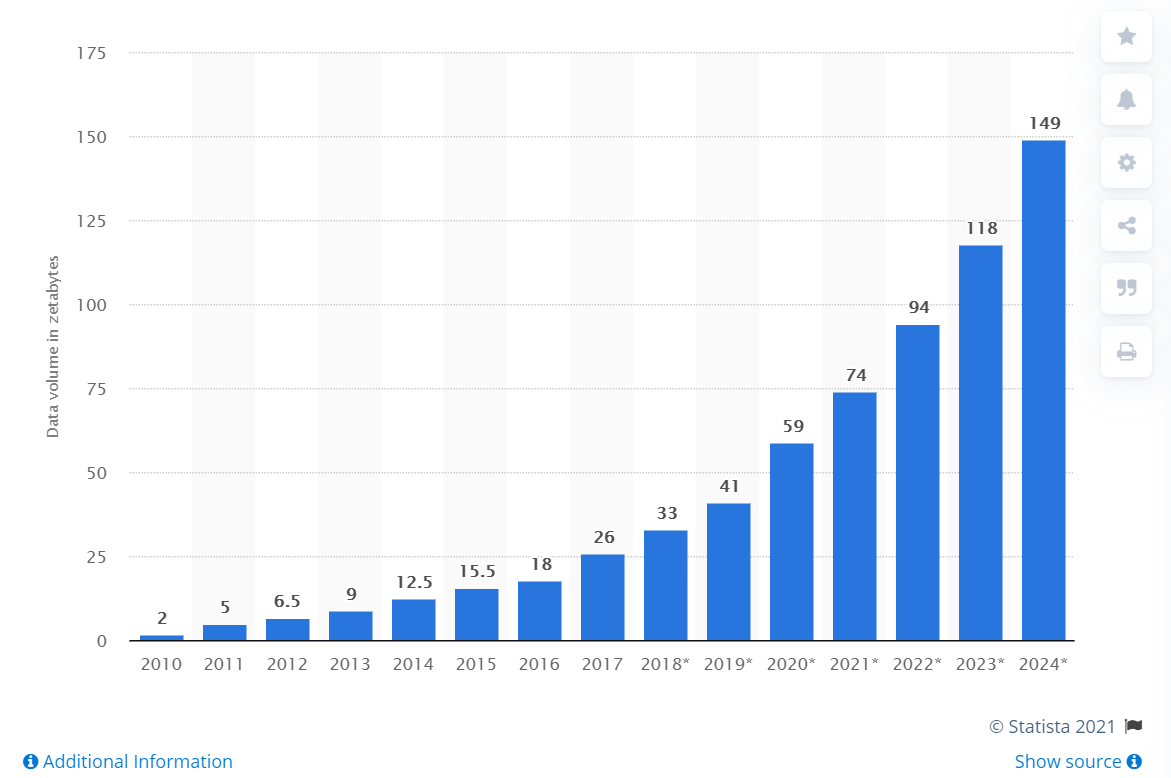
Объем данных, созданных, собранных и потребленных во всем мире с 2010 по 2024 год (в зеттабайтах) (Фото: Statista)
Развитие Data Science шло вместе с внедрением технологий Big Data и анализа данных. И хотя эти области часто пересекаются, их не следует путать между собой. Все они предполагают понимание больших массивов информации. Но если аналитика данных отвечает на вопросы о прошлом (например, об изменениях в поведениях клиентов какого-либо интернет-сервиса за последние несколько лет), то Data Science в буквальном смысле смотрит в будущее. Специалисты по DS на основе больших данных могут создавать модели, которые предсказывают, что случится завтра. В том числе и предсказывать спрос на те или иные товары и услуги.
Особенности профессии
Обычные специалисты по статистике, системный аналитик или бизнес-аналитик по отдельности не могут обрабатывать массивы информации, которые относятся к категории Big Data. Для этого нужен профи с междисциплинарным образованием, компетентный в математике и статистике, экономике и бизнесе, информатике и компьютерных технологиях, – специалист по работе с данными, то есть Data Scientist .
Главные задачи Data Scientist´а:
- извлекать необходимую информацию из самых разнообразных источников, используя информационные потоки в режиме реального времени;
- устанавливать скрытые закономерности в массивах данных и статистически анализировать их для принятия грамотных бизнес-решений.
Рабочиее место датасайентиста – не 1 компьютер и даже не 1 сервер, а кластер серверов.
Data Scientist, как настоящий учёный, занимается не только сбором и анализом данных, но и изучает их в разных контекстах и под разными углами, подвергая сомнению любые предположения. Важнейшее качество дата-сайентиста – это умение видеть логические связи в системе собранной информации и на основе количественного анализа разрабатывать эффективные бизнес-решения. В современном конкурентном и быстро меняющемся мире, в постоянно растущем потоке информации Data Scientist незаменим для принятия правильных бизнес-решений.

Что делает Data Scientist
В разных компаниях задачи дата-сайентиста будут отличаться, но основные этапы работы похожи:
- Выяснить, что нужно заказчику.
- Оценить, возможно ли решить поставленную задачу методами машинного обучения (ML).
- Собрать данные для анализа, преобразовать их в формат, более удобный для работы по методике ML. (Если возможность применить ML есть, а если целесообразнее использовать методы математической статистики, визуализации, то задачу решает бизнес-аналитик.)
- Найти критерии оценки, чтобы выяснить, насколько эффективной будет модель, которую предстоит создать.
- Запрограммировать и «натренировать» модель ML.
- Оценить экономическую целесообразность применения этой модели (на этом этапе возможна помощь других специалистов – бизнес-аналитика, главного экономиста предприятия и др.).
- Внедрить модель в производство/продукт.
- Сопровождать внедренную модель – дорабатывать, если нужно, или адаптировать под текущие запросы заказчика.
Что можно сделать по такому шаблону? Очень много. Дата-сайентисты создали сотни сервисов, к которым мы давно привыкли и пользуемся каждый день. Алгоритмы поисковых систем, прогнозы погоды в смартфонах, голосовые помощники, программы распознавания лиц или изображений, рекомендательные алгоритмы, подбирающие видео и музыку или потенциальных друзей в соцсетях, чат-боты – всё это плоды трудов Data Scientist′ов.

В работе с данными Data Scientist использует:
- статистические методы;
- моделирование баз данных;
- методы интеллектуального анализа;
- искусственный интеллект для работы с данными;
- методы проектирования и разработки баз данных.

Что один графический процессор делает быстрее другого?
Лучший показатель производительности графического процессора — комбинация пропускной способности, FLOPS и Tensor Cores.
Чтобы углубить ваше понимание и помочь сделать осознанный выбор, расскажу о том, какие части аппаратного обеспечения ускоряют работу GPU для двух наиболее важных тензорных операций: перемножения матриц и свертки.
Простой и эффективный способ думать о матричном умножении — это то, что оно ограничено пропускной способностью. То есть пропускная способность памяти является наиболее важной особенностью GPU, если вы хотите использовать LSTM и другие рекуррентные сети, которые выполняют многократное умножение матриц.
Для сверточных нейронных сетей имеет значение скорость обучения. Таким образом, TFLOP на графическом процессоре — лучший показатель производительности ResNet и других сверточных архитектур.
Тензорные сердечники слегка меняют уравнение. Это очень простые специализированные вычислительные блоки, которые могут ускорить вычисления — но не пропускную способность памяти — и, таким образом, наибольшее преимущество можно увидеть для сверточных сетей, которые с тензорными ядрами быстрее примерно на 30-100% .
В целом, правило выбора GPU для машинного обучения следующее:
- с мотрите на показатели пропускной способности, если вы работаете с RNN;
- смотрите на показатели FLOPS, если вы работаете со сверткой;
- используйте тензорные ядра, если можете себе позволить.
Инструменты Data Science
Специалисты в области Data Science хоть и не являются разработчиками, но должны уметь программировать и создавать приложения. В противном случае у них попросту не будет достаточного количества инструментов для обработки данных. Поэтому придется изучить хотя бы один из двух наиболее востребованных в Data Science языков программирования.
R. Это язык с открытым исходным кодом и программное окружение для создания статистических вычислений. R предлагает большое количество библиотек и инструментов для фильтрации и предобработки данных. Также с помощью него можно визуализировать данные и тренировать модели машинного обучения для корректного взаимодействия с полученной информацией.
Python. Объектно-ориентированный язык программирования общего назначения. Python настолько универсален, что применяется практически в любых сферах деятельности, включая работу с искусственным интеллектом и обработку числовых значений.
Также дата-сайентисты задействуют в своей деятельности такие инструменты, как Apache Spark, Tableau, Microsoft PowerBI и десятки других, помогающих взаимодействовать с данными.
Не знаешь, с чего начать? Протестируй это

Требования к поступающим: немного школьной математики будет кстати
Что понадобится в учебе: усидчивость, внимательность, любовь к деталям
Кому понравится: дотошным и усидчивым; кому нужен быстрый старт карьеры
Сколько зарабатывают начинающие специалисты: ~50-100 тыс. рублей
На заре активного распространения интернет-технологий команды разработки использовали ручное тестирование своих систем, нанимая студентов, которые вручную проверяли работоспособность тех или иных функций.
Со временем появились системы для создания автоматических и нагрузочных тестов, способных имитировать действия человека в самых разных окружениях. Но в тестировщики все так же охотно берут новичков.
Так что это все еще самый простой способ входа в IT , если нужно сменить профиль работы. А если освоить соответствующую программу SkillFactory, можно претендовать на неплохой доход.

Учебная программа комплексно имитирует работу тестировщика: человек вливается в коллектив в роли «стажера», постепенно повышая знания и навыки до уровня начинающего QA-инженера.
В ходе работы придется освоить ручное и автоматизированное тестирование на Python, разобраться с алгоритмами работы программ и сайтов, отработать основные способы решение задач и научиться работать в команде.
Используют и Selenium, и баг-трекеры. Все по-взрослому. Заодно появится активный аккаунт на GitHub и ряд проектов в портфолио. Так что работа найдется без труда.
В отличие от других программ онлайн-школы, большинство задач ведутся в автономном режиме : программа усваивается самостоятельно, а с вопросами и практическими задачами работают менторы — профессиональные тестировщики крупных информационных компаний.

Тестировщики, умеющие писать автотесты — бесценны
Ещё и время прохождение курса не ограничено. Поэтому можно учиться в собственном режиме, совмещая с текущей работой или учебой.
А совсем новичкам карьерный центр SkillFactory поможет собрать резюме , отработать собеседование и найти работу. И это очень полезная в начале карьеры фишка.
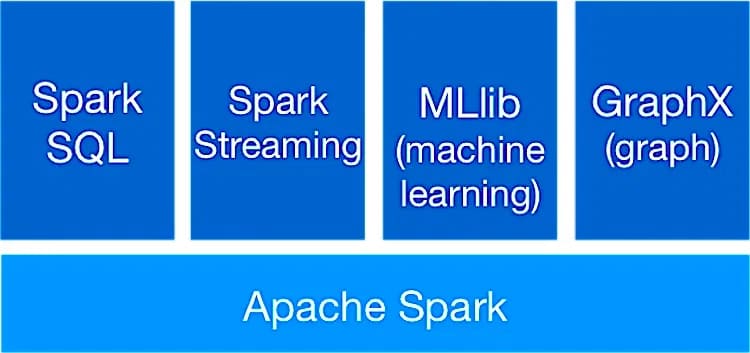
Apache Spark
Плюсы:
Надежность и отказоустойчивость.
Эффективно реализует модели машинного обучения для больших наборов данных.
Может получать данные из нескольких источников данных.
Поддержка нескольких языков.
Минусы:
Высокая кривая обучения.
Плохая визуализация данных.
Цена: Бесплатно.
Apache Spark — это механизм обработки данных с открытым исходным кодом, созданный для больших наборов данных. Он использует современный планировщик DAG, оптимизатор запросов и эффективный механизм выполнения для достижения высокой производительности как для пакетных, так и для потоковых данных. Он может выполнять рабочие нагрузки до 100 раз быстрее.
Spark использует множество библиотек, включая GraphX, MLlib для машинного обучения, Spark Streaming, SQL и DataFrames. Все эти библиотеки могут быть легко объединены в одно приложение.
Этот инструмент имеет иерархическую архитектуру главный-подчиненный. «Драйвер Spark» — это главный узел, который управляет несколькими рабочими (подчиненными) узлами и доставляет результаты данных клиентскому приложению.
Фундаментальная структура Spark — это устойчивые распределенные наборы данных, отказоустойчивый набор компонентов, которые могут быть распределены между несколькими узлами в кластере и работать с ними параллельно.
Он предоставляет более 80 операторов высокого уровня, что упрощает разработку параллельных приложений. Кроме того, вы также можете использовать Spark в интерактивном режиме из оболочек R, Python, Scala и SQL.
Data science
Сообщество для data science инженеров или для тех, кто хочет им стать. Я публикую интересные материалы, которые нахожу по ходу своей работы. Хочу поделиться этим с вами. Рад комментариям и обсуждениям

Data science запись закреплена
Прими участие в масштабном онлайн-хакатоне «Moscow City Hack 2022» от Агентства инноваций Москвы!
Тебя ждут:
Призовой фонд 3 400 000 ₽;
Задачи по разработке сервисов для мотивации студентов, привлечения волонтеров, цифрового маркетинга, импортозамещения и разоблачения fake news;
Показать полностью.
Эксперты от крупного бизнеса и Правительства Москвы;
Образовательная программа с мастер-классами и интенсивами;
Красочный мерч, подарки от партнеров и много крутых активностей

Хакатон пройдет 10-13 июня 2022 года
Регистрируйся уже сейчас!
https://bit.ly/3FRQ6tL
Узнать подробности и найти команду можно в нашем Telegram-чате
t.me/MoscowCityHack
Data science запись закреплена

Ovision — лидер в области биометрии проводит хакатон OVision Hack
Кейсы — уникальные: разработка realtime-решения для распознавания атрибутов лица из готовых модулей, оптимизация поиска лиц по базам, а ещё — пентест работающей системы распознавания лиц.
Показать полностью.

Что интересно, лидер в области технологий по распознаванию лиц не просто разрешит взломать свою же систему, но и предложит за это денежный приз и возможность получить работу в компании
Призовой фонд: 500.000 рублей
Когда: 15-17 апреля, а подать заявку можно до 13 апреля
Скорее регистрируйтесь на OVision Hack и покоряйте новые IT-вершины: https://tprg.ru/qN1a
Ещё больше интересных проектов и новостей вы найдёте в каналах организаторов:
Data science запись закреплена
Ищу гостя для записи выпуска подкаста.
Тема: VPN как это работает и как не потерять свои данные
Нужен специалист в области кибер безопасности. Хорошо знакомый с принципом работы VPN
Data science запись закреплена


Data science запись закреплена
Много у кого до сих пор возникают проблемы с разворачивание kafka локально. Накидал проект, где все есть, надо только запустить
Data science запись закреплена
3-5 декабря Транспортные инновации Москвы проведут онлайн-хакатон по кибербезопасности Moscow Secure Traffic.
Участникам предстоит решить один из двух кейсов, посвященных поиску нестандартных решений в области кибербезопасности сервисов Московского транспорта.
Команды, предложившие самые перспективные решения, смогут побороться за крупные денежные призы.
Показать полностью.
Для участников будет организован идеатон по оптимизации транспортных потоков Москвы с отдельным призовым фондом в 100 000 рублей.
Общий призовой фонд хакатона составит 500 000 рублей.
Членами жюри и экспертами хакатона выступят представители ТИМ, ЦОДД, ИЦ «Безопасный транспорт», Акселератора Возможностей, МГУ им. М. В. Ломоносова, ИНТЦ МГУ «Воробьевы горы», ФИЦ ИУ РАН, АО «Лаборатория Касперского», Positive Technologies, Сбер, ГК «Программный продукт» и RuSIEM.
Прием заявок на хакатон открыт до 2 декабря.
Data science запись закреплена

Для участия в Sibur Challenge 2021 срочно ищем data scientist и digital-специалистов, работающих с алгоритмами машинного обучения!
Призовой фонд 650 000 рублей.
Одна задача. 5 призовых мест.
Регистрация и telegram-чат участников уже открыты!
Показать полностью.
https://bit.ly/31LTHd3
Что вас ждет:
» Работа с реальной задачей от СИБУР Диджитал, IТ-компанией нефтехимической группы СИБУР;
» Поддержка и ответы на вопросы — в чате и на субботних вебинарах;
» Возможность объединяться в команды;
» Прямой доступ к ведущим экспертам индустрии;
» Возможность получить приглашение на работу или стажировку;
» Дополнительные вознаграждения за активности;
» Общение с единомышленниками;
» Финальная презентация решений победителей;
Sibur Challenge — ежегодный онлайн-чемпионат по анализу данных, организованный СИБУР Диджитал, IТ-компанией нефтехимической группы СИБУР, совместно с профессиональным сообществом экспертов и команд по искусственному интеллекту AI Community. Чемпионат по Data Science пройдет уже в четвертый раз.
Финальная презентация решений победителей пройдет 11 декабря 2021. Онлайн.
Подай заявку на участие!
https://bit.ly/31LTHd3
Добавляйся в чат и в числе первых получай доступ к данным по задаче!
Data science запись закреплена
29-31 октября пройдет онлайн-хакатон EVRAZ AI Challenge от международной горно-металлургической компании EVRAZ
Узнайте на хакатоне, чем айтишники занимаются в промышленности, а также .
Продуйте металл через Data Science;
Показать полностью.
Разработайте компьютерное зрение для контроля опасных зон агломашины;
Станьте частью команды EVRAZ;
Прокачайте свои скиллы вместе с экспертами EVRAZ.
Приглашаем принять участие всех, кому интересен Data Science и Computer Vision,
Призовой фонд — 500 000 рублей
Регистрируйтесь до 26 октября 23:59 по ссылке: https://vk.cc/c75gLP
Обязательно приглашайте друзей и добавляйтесь в Telegram-чат, чтобы найти единомышленников: https://clck.ru/XzPqB
Мы ждём вас на хакатоне!
Data science запись закреплена
1 октября в Москве пройдет Russia Open Source Summit, где на одной площадке соберутся все, кто в России создает программное обеспечение на основе открытого кода.
На открытии саммита будет представлен проект стратегии развития Open Source в России. После презентации проекта всем участникам мероприятия предложат выбрать одну из рабочих групп для внесения предложений в документ.
В рамках деловой программы будет выделен отдельный трек для шоу-кейсов (питчей) от стартапов, созданных на базе открытого кода. Можно подать заявку на выступление.
Принять участие можно бесплатно, регистрация на сайте — https://russiaos.ru/summit/.
Мероприятие начнется в 10:00 на площадке Radisson Collection Hotel.
Подготовка стратегии ведется российским экспертным ИТ-сообществом в открытом формате, в том числе на площадке Telegram — https://t.me/OpenSourceRu
Data science запись закреплена
ДО 30 СЕНТЯБРЯ ОТКРЫТ БЕСПЛАТНЫЙ ДОСТУП к материалам прошедшей на днях онлайн-конференции об аналитике данных, машинном обучении, ИИ, гибридных облаках, информационной безопасности и обнаружении мошенничества.
Транскрипты выступлений спикеров, видеозаписи, презентации: https://cutt.ly/1EjxOFM
День 1.
МАШИННОЕ ОБУЧЕНИЕ
Показать полностью.
— Обзор технологий ML и применение в задачах бизнеса
— Проекты ML/AI от 10 БАНКов и Эффекты от: Capital One, Siemens Financial Services, Space
— Neobank, PrivatBank, Root Insurance, BlueVine, OakNorth, Fannie Mae, Coinbase, UniCred, John Hancock.
— 5 ключевых факторов успешного применения ML
— Круглый стол по применению ML
— Обзор сервисов для машинного обучения
— Критерии по отбору проектов ML
Эксперт: Александр Патрушев, архитектор специализированных решений – Искусственный Интеллект, Amazon Web Service.
День 2
ГИБРИДНЫЕ ОБЛАКА
— Когда гибридная инфраструктура оправдана?
— Построение гибрида на уровне сети.
— Безопасное взаимодействие в выделенных сетевых окружениях AWS
— Организация работы с копией данных, хранящихся в датацентр
— Распределенная обработка данных пользователей из разных регионов и стран
— Быстрое построение dev/test окружений за пределами периметра организации
Эксперт: Андрей Фирсов, Архитектор решений AWS, Softline Group
День 3
НЕТ МОШЕННИЧЕСТВУ В ИНТЕРНЕТЕ
— Инструменты AWS для обнаружения мошеннических действий.
— Вы узнаете, как определить, можно ли доверять новому пользователю, с момента первого взаимодействия с вашим сервисом.
— Инструменты для оценки подозрительных онлайн-транзакций до обработки платежей и выполнения заказов.
— Обзор практических кейсов по обнаружению случаев регистрации мошенников и проверке подозрительных транзакций.
Эксперт: Владислав Гавриленко, руководитель направления AWS в SOFTPROM











