Приветствую вас, дорогие читатели блога. Сегодня я хочу рассказать вам о некоторых сервисах, которые давно у меня лежат в закладках. Речь пойдет о сервисах распознавания текста онлайн.

Наверное, у каждого был случай, когда вы хотели переписать какой-то текст с картинки или PDF файла. Это могли быть какие-то документы или просто красивая цитата. У меня таких случаев было немало и меня всегда выручали сервисы распознавания текста. Конечно, существуют и программы для этой цели, но я предпочитаю такие простые задачи делать онлайн.
Ниже вы можете увидеть перечень сервисов, благодаря которым распознать текст с изображения проще простого. Все сервисы абсолютно бесплатны и не требуют регистрации.
Принцип сервисов весьма прост. Вы загружаете изображение, содержащее текст, сервис его обрабатывает и выдает вам готовый текст, избавляя вас от его переписывания. Качество распознавания текста с изображения напрямую зависит от качества самого изображения.
Где можно распознать текст с PDF файла, картинки или фотографии бесплатно
Итак, вот список сервисов:
www.newocr.com – позволяет распознать текст бесплатно с изображений таких форматов как: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu. Сервис поддерживает множество языков. После распознания текста с картинки, его можно скопировать и вставить в свой документ.
www.onlineocr.net — аналогичный предыдущему сервис, с тем лишь отличием, что здесь распознанный текст можно скачать в форматах Microsoft Word (docx), Microsoft Exel (xlsx), Text Plain (txt).
www.free-ocr.com – сервис, поддерживающий форматы jpg, png, bmp, pdf, jpeg, tiff, tif и gif. Языков распознавания чуть меньше чем в предыдущих сервисах, но тоже немало. Скачать распознанный тест можно в txt формате.
www.i2ocr.com – сервис, поддерживающий более 60 языков. Кроме основной функции распознавания текста с изображений, здесь есть такие инструменты как:
- Конвертация web-страницы в PDF;
- Преобразование web-страницы в изображение (скриншот);
- Генератор кнопок CSS3;
- Международные клавиатуры;
- Преобразователь формата изображений;
Качество извлечения текста с изображений
Особой разницы в качестве распознавания текста на изображениях между сервисами я не заметил, поэтому в качестве примера покажу лишь первый сервис.
Для примера я взял несколько изображений разного размера и качества изображенного текста.
Изображение 1 (790 X 588 px)
Изображение 2 (793 X 1024 px)
Изображение 3 (600 X 350 px)
И вот результат самого текста, который сервис распознал на картинке.
Результат 1 изображения:
Шел 25 год без
собственной яхты и домика
на берегу океана, мысль о
продаже почки перестает
казаться безумной.
В первом изображении текст распознан идеально и вообще без ошибок.
Результат 2 изображения:
Меню В новогоднюю ночь
ЯТриветственный коктейль
(Шампанское советское) 150 гр.
Соленая квашенные, домашние. 60/1 гр.
Грибочки из погребка.
Яссорти аз маранованньск грибов. 64,5 гр.
ч Мясное Яссорта (ростбиф, язык буякенана) 85 гр.
Сельдь с картофелем и луком красным. 100 гр.
Лосось камчатский с травами дикими 58,5 гр.
Селедочка под шубкой. 200 гр.
Холодец, с мясом. 182 гр.
Оливье мясной 150 гр.
Салат с куриной грудкой а грибочкама 150 гр.
фруктовая ваза
(виноград, груша, бананы, яблоко, апельсин, кави) 375 гр.
Сигбная корзина 85 гр.
Кулебяка с лососем и судаком или 212 гр.
Товядана со сметаной и сыром картофельным
гратаном а соусом красное вино 247 гр.
Запеченые груши с красным вином,
мороженным и грецкими орехами 142 гр.
Напитки
Шампанское (Российское полсл. 750 гр.
7 (Водка Лунтика 500 гр.
(Вано Красное Ундурага сух, 750 гр.
Фано *Белое <Ундурага сук. 750 гр.
$ода с газом 600 гр.
Фода без газа 600 гр. ., №3
3 . , , ‘ , :Морс (промышленный) 1000 гр.»?`
Сок/‘!пельсан ( 2л. ) 2000 гр.
Здесь видно присутствие ошибок. Это связано с особенностю шрифта и контрастом текста на основном фоне.
Результат 3 изображения:
Чтобы питательные маски отдали вашей коже
есь свой полезный арсенал, важно
7 олнять их правильно. Вот моменты,
ые нужно учитывать при
Ь; _ ьэоваиии питательных масок для лица.
Йтательные маски нельзя х
ранить, они
“тотовятся непосредственно перед
Чоцедурой
е_ перед применением питательной маски
[Гдлицо необходимо очистить скрабом и слегка
вает-рить
лице питательная маска держится 20
минуъ‘после чего смывается теплой водой
в темение часа после использования
питательной маски на улицу желательно не
ьд‘выходить
стота применения питательных масок для
и лица — 2-3 в неделю
спользуйте принцип — две недели делаете
В третьем примере левая часть столбца имееет плохую контрастность, поэтому некоторы слова вообще не распознаны.
На основе этих трех примеров, можно сделать простой вывод – чем лучше и отчетливее виден текст на изображении, тем более качественное будет распознавание текста. Многое так же зависит от шрифта текста. Если шрифт простой, то его сервис прочтет без труда, ну а чем сложнее шрифт, тем больше будет ошибок при распознавании текста.
7 инструментов для распознавания текста онлайн и офлайн
Эти сайты и программы помогут извлечь текстовое содержимое изображений и бумаг, чтобы вам было удобнее с ним работать.
1. Office Lens
- Платформы: Android, iOS, Windows.
- Распознаёт: снимки камеры.
- Сохраняет: DOCX, PPTX, PDF.
Этот сервис от компании Microsoft превращает камеру смартфона или ПК в бесплатный сканер документов. С помощью Office Lens вы можете распознать текст на любом физическом носителе и сохранить его в одном из «офисных» форматов или в PDF. Итоговые текстовые файлы доступны для редактирования в Word, OneNote и других сервисах Microsoft, интегрированных с Office Lens. К сожалению, с русским языком программа справляется не так хорошо, как с английским.





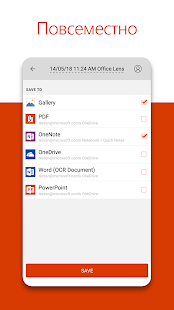

2. Adobe Scan
- Платформы: Android, iOS.
- Распознаёт: снимки камеры.
- Сохраняет: PDF.
Adobe Scan тоже использует камеру смартфона, чтобы сканировать бумажные документы, но сохраняет их копии только в формате PDF. Приложение полностью бесплатно. Результаты удобно экспортировать в кросс‑платформенный сервис Adobe Acrobat, который позволяет редактировать PDF‑файлы: выделять, подчёркивать и зачёркивать слова, выполнять поиск по тексту и добавлять комментарии.




3. FineReader
- Платформы: веб, Android, iOS, Windows.
- Распознаёт: JPG, TIF, BMP, PNG, PDF, снимки камеры.
- Сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A, PPTX, EPUB, FB2.
FineReader славится высокой точностью распознавания. Увы, бесплатные возможности инструмента ограниченны: после регистрации вам позволят отсканировать всего 10 страниц. Зато каждый месяц будут начислять ещё по пять страниц в качестве бонуса. Подписка стоимостью 129 евро позволяет сканировать до 5 000 страниц в год, а также открывает доступ к десктопному редактору PDF‑файлов.
4. Online OCR
- Платформы: веб.
- Распознаёт: JPG, GIF, TIFF, BMP, PNG, PCX, PDF.
- Сохраняет: TXT, DOC, DOCX, XLSX, PDF.
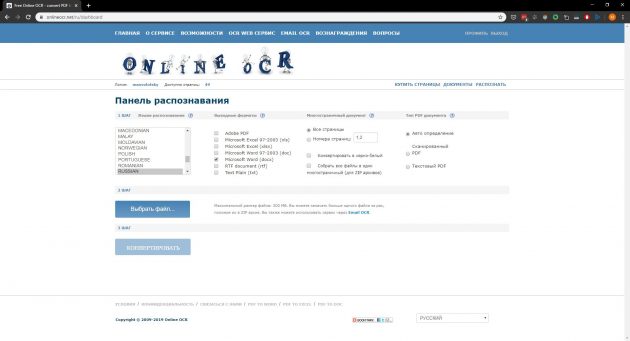
Веб‑сервис для распознавания текстов и таблиц. Без регистрации Online OCR позволяет конвертировать до 15 документов в час — бесплатно. Создав аккаунт, вы сможете отсканировать 50 страниц без ограничений по времени и разблокируете все выходные форматы. За каждую дополнительную страницу сервис просит от 0,8 цента: чем больше покупаете, тем ниже стоимость.
5. img2txt
- Платформы: веб.
- Распознаёт: JPEG, PNG, PDF.
- Сохраняет: PDF, TXT, DOCX, ODF.
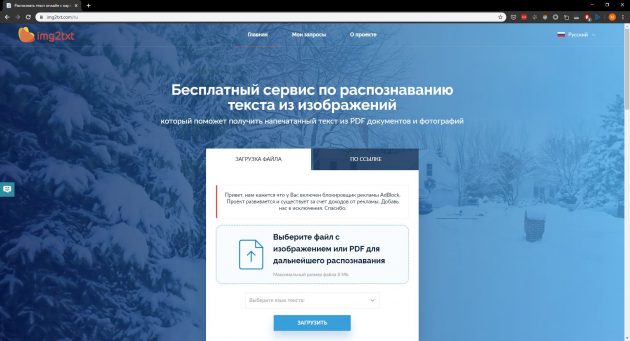
Бесплатный онлайн‑конвертер, существующий за счёт рекламы. img2txt быстро обрабатывает файлы, но точность распознавания не всегда можно назвать удовлетворительной. Сервис допускает меньше ошибок, если текст на загруженных снимках написан на одном языке, расположен горизонтально и не прерывается картинками.
6. Microsoft OneNote
- Платформы: Windows, macOS.
- Распознаёт: популярные форматы изображений.
- Сохраняет: DOC, PDF.
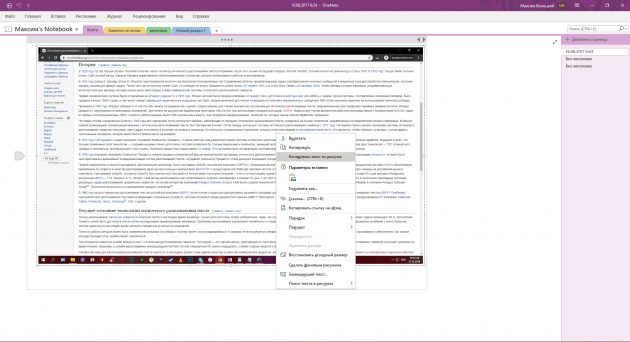
В настольной версии популярного блокнота OneNote тоже есть функция распознавания текста, которая работает с загруженными в заметки изображениями. Если кликнуть правой кнопкой мыши по снимку документа и выбрать в появившемся меню «Копировать текст из рисунка», то всё текстовое содержимое окажется в буфере обмена. Программа доступна бесплатно.
7. Readiris 17
- Платформы: Windows, macOS.
- Распознаёт: JPEG, PNG, PDF и другие.
- Сохраняет: PDF, TXT, PPTX, DOCX, XLSX и другие.
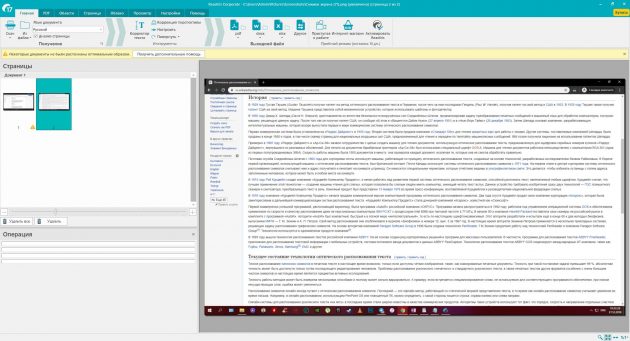
Мощная профессиональная программа для работы с PDF и распознавания текста. С высокой точностью конвертирует документы на разных языках, включая русский. Но и стоит Readiris 17 соответственно — от 49 до 199 евро в зависимости от количества функций. Вы можете установить пробную версию, которая будет работать бесплатно 10 дней. Для этого нужно зарегистрироваться на сайте Readiris, скачать программу на компьютер и ввести в ней данные от своей учётной записи.
Распознаем текст онлайн с картинок, отсканированных документов бесплатно и без регистрации
Приветствую вас, дорогие читатели блога. Сегодня я хочу рассказать вам о некоторых сервисах, которые давно у меня лежат в закладках. Речь пойдет о сервисах распознавания текста онлайн.
Наверное, у каждого был случай, когда вы хотели переписать какой-то текст с картинки или PDF файла. Это могли быть какие-то документы или просто красивая цитата. У меня таких случаев было немало и меня всегда выручали сервисы распознавания текста. Конечно, существуют и программы для этой цели, но я предпочитаю такие простые задачи делать онлайн.
Ниже вы можете увидеть перечень сервисов, благодаря которым распознать текст с изображения проще простого. Все сервисы абсолютно бесплатны и не требуют регистрации.
Принцип сервисов весьма прост. Вы загружаете изображение, содержащее текст, сервис его обрабатывает и выдает вам готовый текст, избавляя вас от его переписывания. Качество распознавания текста с изображения напрямую зависит от качества самого изображения.
Где можно распознать текст с PDF файла, картинки или фотографии бесплатно
Итак, вот список сервисов:
www.newocr.com – позволяет распознать текст бесплатно с изображений таких форматов как: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu. Сервис поддерживает множество языков. После распознания текста с картинки, его можно скопировать и вставить в свой документ.
www.onlineocr.net — аналогичный предыдущему сервис, с тем лишь отличием, что здесь распознанный текст можно скачать в форматах Microsoft Word (docx), Microsoft Exel (xlsx), Text Plain (txt).
www.free-ocr.com – сервис, поддерживающий форматы jpg, png, bmp, pdf, jpeg, tiff, tif и gif. Языков распознавания чуть меньше чем в предыдущих сервисах, но тоже немало. Скачать распознанный тест можно в txt формате.
www.i2ocr.com – сервис, поддерживающий более 60 языков. Кроме основной функции распознавания текста с изображений, здесь есть такие инструменты как:
- Конвертация web-страницы в PDF;
- Преобразование web-страницы в изображение (скриншот);
- Генератор кнопок CSS3;
- Международные клавиатуры;
- Преобразователь формата изображений;
Качество извлечения текста с изображений
Особой разницы в качестве распознавания текста на изображениях между сервисами я не заметил, поэтому в качестве примера покажу лишь первый сервис.
Для примера я взял несколько изображений разного размера и качества изображенного текста.
Изображение 1 (790 X 588 px)
Изображение 2 (793 X 1024 px)
Изображение 3 (600 X 350 px)
И вот результат самого текста, который сервис распознал на картинке.
Результат 1 изображения:
Шел 25 год без
собственной яхты и домика
на берегу океана, мысль о
продаже почки перестает
казаться безумной.
В первом изображении текст распознан идеально и вообще без ошибок.
Результат 2 изображения:
Меню В новогоднюю ночь
ЯТриветственный коктейль
(Шампанское советское) 150 гр.
Соленая квашенные, домашние. 60/1 гр.
Грибочки из погребка.
Яссорти аз маранованньск грибов. 64,5 гр.
ч Мясное Яссорта (ростбиф, язык буякенана) 85 гр.
Сельдь с картофелем и луком красным. 100 гр.
Лосось камчатский с травами дикими 58,5 гр.
Селедочка под шубкой. 200 гр.
Холодец, с мясом. 182 гр.
Оливье мясной 150 гр.
Салат с куриной грудкой а грибочкама 150 гр.
фруктовая ваза
(виноград, груша, бананы, яблоко, апельсин, кави) 375 гр.
Сигбная корзина 85 гр.
Кулебяка с лососем и судаком или 212 гр.
Товядана со сметаной и сыром картофельным
гратаном а соусом красное вино 247 гр.
Запеченые груши с красным вином,
мороженным и грецкими орехами 142 гр.
Напитки
Шампанское (Российское полсл. 750 гр.
7 (Водка Лунтика 500 гр.
(Вано Красное Ундурага сух, 750 гр.
Фано *Белое <Ундурага сук. 750 гр.
$ода с газом 600 гр.
Фода без газа 600 гр. ., №3
3 . , , ‘ , :Морс (промышленный) 1000 гр.»?`
Сок/‘!пельсан ( 2л. ) 2000 гр.
Здесь видно присутствие ошибок. Это связано с особенностю шрифта и контрастом текста на основном фоне.
Результат 3 изображения:
Чтобы питательные маски отдали вашей коже
есь свой полезный арсенал, важно
7 олнять их правильно. Вот моменты,
ые нужно учитывать при
Ь; _ ьэоваиии питательных масок для лица.
Йтательные маски нельзя х
ранить, они
“тотовятся непосредственно перед
Чоцедурой
е_ перед применением питательной маски
[Гдлицо необходимо очистить скрабом и слегка
вает-рить
лице питательная маска держится 20
минуъ‘после чего смывается теплой водой
в темение часа после использования
питательной маски на улицу желательно не
ьд‘выходить
стота применения питательных масок для
и лица — 2-3 в неделю
спользуйте принцип — две недели делаете
В третьем примере левая часть столбца имееет плохую контрастность, поэтому некоторы слова вообще не распознаны.
На основе этих трех примеров, можно сделать простой вывод – чем лучше и отчетливее виден текст на изображении, тем более качественное будет распознавание текста. Многое так же зависит от шрифта текста. Если шрифт простой, то его сервис прочтет без труда, ну а чем сложнее шрифт, тем больше будет ошибок при распознавании текста.
OCR РАСПОЗНАВАНИЕ ТЕКСТА ИЗ PDF И ИЗОБРАЖЕНИЙ
Как работает наш OCR сервис
Что такое OCR
Вы когда-нибудь хотели иметь возможность найти в печатном цифровом материале или отсканированном документе конкретный текст? Или возникла ли у вас необходимость отредактировать содержимое журнала или отсканированного PDF-документа, не перепечатывая весь документ? Классическим решением во всех этих случаях было бы перенабрать весь контент и его отредактировать. Это все еще нормальная практика, когда дело доходит до редактирования печатных контрактов, брошюр или страниц журнала. Но мы все знаем, насколько трудоемким и беспокойным может стать это решение, если источник представляет собой обыкновенное изображение. Бесплатный OCR сервис — это то, что может решить вашу проблему, сэкономить деньги, сэкономить ваше драгоценное время и обеспечить быстрые и эффективные результаты всего за несколько шагов.
Оптическое распознавание символов или OCR — это технология, позволяющая преобразовывать печатные или рукописные документы в редактируемые текстовый материал. Просто отсканировав напечатанные документы с помощью программного обеспечения для распознавания текста OCR, вы можете легко конвертировать файлы в печатные копии, которые можно редактировать, копировать или распространять согласно вашим требованиям. Сканеры текста OCR очень универсальны и могут сканировать текст из изображений, печатных документов и файлов PDF. Программное обеспечение OCR можно загрузить или использовать в качестве онлайн-сервисов.
Как работает OCR
Хотя понятие «машинного распознавания текста» не ново и появилось еще в 1960-х годах, в то время компьютер мог считать единственный вариант шрифта, называемый OCR-A. С развитием технологии сканеры текста OCR стали более продвинутыми и позволили пользователям использовать эту технологию для более широкого спектра приложений. В настоящее время текстовые сканеры OCR в основном используют два различных метода для преобразования печатного текста в редактируемый.
Метод сопоставления матриц
Первый метод — это метод сопоставления матриц. Этот метод работает по принципу сопоставления печатного текста с базой данных шаблонов символов и шрифтов. Сканер текста OCR сканирует напечатанный текст, сравнивает его с существующей библиотекой шаблонов и, когда совпадение найдено, преобразует данные в соответствующий код ASCII. Затем вы можете манипулировать этими данными в соответствии с вашими требованиями. Этот метод быстро возвращает результаты, но из-за ограниченной базы данных символов метод сопоставления матриц имеет свои ограничения. Алгоритм завершается ошибкой, когда он пытается распознать текст, которого нет в его базе данных, и выводит неверный текст. Следовательно, пользователи должны сохранять бдительность при использовании этого метода, поскольку он может генерировать ошибки, которые необходимо будет впоследствии исправить вручную.
Метод извлечения особенностей
Другой метод, используемый программным обеспечением OCR, — это метод извлечения признаков текста. Этот метод основан на искусственном интеллекте, где онлайн программное обеспечение OCR предназначено для определения общих точек в форме букв, таких как искривления, наклоны и пробелы в алфавите. Сканеры текста OCR ищут эти общие точки в тексте и возвращают результаты в коде символов ASCII после того, как найден определенный процент «совпадения». Следовательно, этот метод ищет повторяющиеся шаблоны или правила, которые представляют букву, и программное обеспечение может предсказать букву, просто просматривая общие точки, найденные в шаблоне. Метод является более гибким и может работать с большим количеством печатных или рукописных документов.
Кроме того, искусственный интеллект постоянно обновляет свои знания о различных почерках и шрифтах, что делает его более универсальным в использовании и оставляет возможности дальнейших улучшений и модернизаций алгоритма.
OCR онлайн сервисы
Самый простой способ сконвертировать распечатанные файлы в редактируемую версию — использование онлайн-сервисов OCR, в том числе нашим сервисом. Использовать онлайн-сервисы OCR чрезвычайно просто, поскольку вам нужно только отсканировать документ, загрузить его, и файл будет преобразован в редактируемую версию. Бесплатный сервис OCR — это отличная возможность для бизнеса сэкономить своё драгоценное время и деньги.
Есть несколько преимуществ использования бесплатных услуг OCR онлайн сервисов. Эти преимущества включают в себя:
- Время, затрачиваемое на весь процесс, значительно сокращается, и большие документы можно подготовить всего за несколько минут. Редактировать контракты, страницы журналов и брошюры теперь стало очень просто.
- Упрощение процесса извлечения данных из сложных документов.
- Снижение вероятности человеческой ошибки, связанной с методом чтения и перепечатывания.
- Устранение трудозатрат в часах, необходимых для затратного процесса ввода данных.
- Сканеры текста OCR являются сложными и могут также распознавать сложные почерки, которые могут занять время, чтобы человеческий глаз мог их прочитать и обработать.
Благодаря более быстрому циклу обработки и современным сканерам распознавания текста, эта технология может сэкономить достаточно значительное количество времени и средств для пользователей, которые смогут распорядиться своим временем более эффективно.
ABBYY FineReader полная версия
Abbyy FineReader отлично подойдет для быстрой работы с сфотографированным текстом, оцифровки старых печатных изданий и даже перевода конспектов в электронный вид. Этот продукт российской компании ABBYY начиная с 2009 года удостаивался различных премий: «Лучший софт», «Лучшее профессиональное ПО» и проч. 
Она позволяет быстро и качественно получить текст из отснятых или отсканированных документов, не меняя последовательности страниц в документе и их структуры. Полученный документ можно сохранять в разных форматах, просматривать, редактировать, искать по содержимому и прикреплять к электронным письмам. 
ABBYY FineReader: что это за программа
В основу FineReader Professional Edition положена технология OCR, заключающаяся в следующем: программа не подбирает загруженное в нее изображение символа, сравнивая с, возможно, бесчисленным множеством шаблонов в поисках подходящего, а делает несколько предположений, на что похож данный оптический объект, что это за знак, постепенно проверяя их.
Затем программа для сканирования выбирает наиболее похожий символ и ищет у исходного сходства с ним. Кроме того, программа способна самообучаться: оцифровывать части документа, опираясь на предыдущий опыт работы с этим же документом. К примеру, седьмая глава отсканированной книги будет обрабатываться несколько быстрее, чем первая, именно за счет обучаемости софта.
Необязательно загружать отсканированные файлы – достаточно будет фотографии с телефона или фотоаппарата(минимально допустимые характеристики – 2МП + автофокус), которую затем можно отредактировать во встроенном редакторе изображений. Кроме того, в ней можно сделать снимок части экрана – screenshot.
Продукт поддерживает более 190 языков, из которых в 48 встроена поддержка орфографии; используемые в файле языки можно настроить заранее или позволить определить самостоятельно. Также вручную можно задать тип обрабатываемого участка: рисунок, таблица, текст. При помощи технологии ADRT сохраняется не только исходная структура документа – нумерация страниц, оглавление, примечания – но даже расположение на странице текста и таблиц.
Для устройств под управлением windows 7 и windows 10 основные задачи(сценарии) доступны прямо из главного окна. А для системы windows 8 в дополнение к ним поддерживаются базовые жесты для сенсорных устройств, такие как масштабирование и прокрутка. В процессе работы можно выбрать, что важнее в данном конкретном случае: скорость или качество работы, и экономить до 50% времени.
С какими форматами работает?
В большинстве случаев Файн Ридер используется для работы с форматом PDF, однако он способен сохранять обработанные файлы не только в нем:
- RTF.
- DOC.
- DOCX.
- DJVU.
- ODT.
- PPT.
- TXT.
- DBF.
- CSV.
- LIT.
- Fb2.
- Epub.
- Создавать HTML-документы.
Кроме того, его можно запускать прямо из пакета Microsoft Office(Excel,Word,Outlook) и сохранять готовые документы в облако. На примере это можно рассмотреть так: документ, высланный вам по почте, находится в формате PDF. Вы откроете его в FineReaderе, распознаете и преобразуете в word-файл, отредактируете как вам необходимо, и сохраните в формате пакета OpenOffice Writer – ODT. Или снова в PDF или оставите в DOC.

Установка
Установщик предоставляется бесплатно и без регистрации. После скачивания файла вы увидите в папке загрузки текстовый документ README.txt и приложение ABBYY.FineReader.v12.0.101.496.exe.

Закройте все окна Microsoft Office. Запустите установчник 

Выберите адрес каталога, куда нужно будет установить программу, «обычный» режим установки

и необходимые опции перед началом установки: рекомендуется убрать галочки во всех строках, кроме второй: «Создать ярлык для ABBYY FineReader 12 на рабочем столе».

После этого ждите окончания процесса. Установка обычно занимает около 10 минут, но не завершайте процесс, не дождавшись окончания: на «засоренном» компьютере она может длиться до получаса или часа.

После появления окна, сообщающего о завершении установки, нажмите кнопку «готово», и программой можно пользоваться – ключик активации уже встроен в файлы.

Интерфейс
Последняя версия ABBYY FineReader 12 обладает дружелюбным пользователю интерфейсом. Верхняя строка разделена на вкладки:
- Файл
- Правка
- Вид
- Документ
- Страница
- Область
- Сервис
- Справка

Основная используемая вкладка «Файл» содержит в себе опции «Новая задача», «Сканировать страницы», «Открыть PDF или изображение», «Сохранить документ», «Отправить по электронной почте», «Печать» и т.д. 
По умолчанию при старте приложения открывается окно «Задача»

Которое также можно вызвать одноименной кнопкой в верхней левой части экрана. В подпунктах можно выбрать одну из стандартных задач – конвертирование, создание электронных таблиц и т.п.- или создать свою пользовательскую задачу.
Слева находится вертикальный список из нескольких пунктов – смотря с чем необходимо работать:
- «Основные» — отображает наиболее популярные действия, такие как быстрое сканирование, сканирование в PDF и Microsoft Word;
- «Microsoft Word», «Excel», Adobe PDF — здесь показываются действия-связки Файнридера и Ворда, Экселя, PDF соответственно, например, «Сканировать в..»;
- В пункте «Другие» находятся кнопки сканирование в прочие и редко используемые форматы: HTML,EPUB и т.д;
- В «Моих задачах» можно создать персонально-ориентированную задачу, облегчающую повседневную работу.
Выбор языка для работы с файлом
Во вкладке настройки можно изменить «Выбор языка», для распознавания текста файла. 

Цветовой режим
В меню «Цветовой режим» предлагается выбрать из цветного или черно-белого, причем во втором случае объем выдаваемого файла будет меньше и время на обработку уменьшится. 
На панели окна Изображение можно выбрать и отметить области распознавания, проверить результат работы и двух сопоставляемых (слева и справа) окнах. В правом – результате распознавания – при помощи встроенного текстового редактора правки можно вносить прямо в нем.
Программа выделяет 4 вида областей:
- Текст
- Картинка
- Фоновая картинка
- Таблица
После выполнения всех манипуляций необходимо запустить распознавание текста снова. Стоит заметить, что распознавать можно только отдельную область без обработки всех остальных страниц документа, что упрощает работу с большими файлами – просто выделите ее и нажмите кнопку «копировать». Необходимо знать, что рукописные тексты программа распознать не сможет. На примере ниже представлен неправильно выбранный документ, не подлежащий обработке.

Как пользоваться
Ознакомьтесь визуально с принципом работы данной программы:
Горячие клавиши
Помимо основных, отображаемых в пользовательском интерфейсе, клавиш, в FineReader существуют т.н. «горячие клавиши». Ниже приведен их неполный список.
Стандартные команды, знакомые нам по пакету MS Office:
- Ctrl+S – сохранение документа
- Ctrl+P – напечатать документ/текст
- Ctrl+Z – отмена предыдущей команды
- Ctrl+X, Ctrl+C, Ctrl+V – вырезать, скопировать, вставить текст/изображение
- И др.











