Зачем нужны базы данных
Если вы будете делать веб-приложение — например интернет-магазин, блог или игры, — почти наверняка вы столкнётесь с базой данных. Вот что это такое с точки зрения программирования, какие тут основные понятия и что с ними делать.
Вокруг нас всегда много разных данных, например:
- телефонные номера;
- дела на день;
- записи на бумажках, стикерах и в блокнотах;
- опубликованные мысли разных людей;
- фотографии в смартфоне;
- и всё остальное, что можно прочитать, увидеть или услышать.
Если это компьютерная игра, то данными будут типы и местоположения врагов, их уровень здоровья, уровень здоровья героя, тип героя, его положение, характеристики карты.
Если это приложение для работы с клиентом, то там будут храниться имя клиента, его заказы, номер телефона, уровень в программе лояльности.
Если это служба слежения за гражданами — фотография, имя, посещённые станции метро и улицы, место работы.
Элементы базы данных Access
Ниже приведены краткие описания элементов стандартной базы данных Access.

Таблица базы данных похожа на электронную таблицу — и там, и там информация расположена в строках и столбцах. Поэтому импортировать электронную таблицу в таблицу базы данных обычно довольно легко. Основное различие заключается в том, как данные структурированы.
Чтобы база данных была как можно более гибкой и чтобы в ней не появлялось излишней информации, данные должны быть структурированы в виде таблиц. Например, если речь идет о таблице с информацией о сотрудниках компании, больше одного раза вводить данные об одном и том же сотруднике не нужно. Данные о товарах должны храниться в отдельной таблице, как и данные о филиалах компании. Этот процесс называется нормализацией.
Строки в таблице называются записями. В записи содержатся блоки информации. Каждая запись состоит по крайней мере из одного поля. Поля соответствуют столбцам в таблице. Например, в таблице под названием «Сотрудники» в каждой записи находится информация об одном сотруднике, а в каждом поле — отдельная категория информации, например имя, фамилия, адрес и т. д. Поля выделяются под определенные типы данных, например текстовые, цифровые или иные данные.
Еще один способ описания записей и полей — визуализация старого стиля каталога карток библиотеки. Каждая карточка в карточке соответствует записи в базе данных. Каждый фрагмент сведений на отдельной карточке (автор, заголовок и так далее) соответствует полю в базе данных.
Дополнительные сведения о таблицах см. в статье Общие сведения о таблицах.
Типы и виды баз данных, классификация
Существует достаточно много типов и видов баз данных, поэтому описывать их все в данной публикации мы не будем. Однако самые распространённые всё же упомянем.
Важно понять, что, говоря о данных, мы подразумеваем определенную информацию, например, о товаре в интернет-магазине. И в этих данных содержатся конкретные параметры и свойства. Однако лучше всего рассматривать БД на конкретных примерах.
Реляционные базы данных
Данный тип БД является старейшим: теоретические основы подхода заложены британским ученым Эдгаром Коддом в 1970 году. Здесь данные формируются в таблицы из строк и столбцов. В строках приводятся сведения об объектах (значения свойств), а в столбцах — сами свойства объектов (поля).
Нормализация
Сложные взаимоотношения объектов в реляционных БД моделируются с помощью внешних ключей – ссылок на другие таблицы. Это позволяет подходить к вопросу проектирования базы данных с позиций нормализации – минимизации избыточности при описании свойств объектов.
Например, если речь идет о меню ресторана, то у каждого блюда есть вес, цена, наименование, калорийность и категория, к которой оно относится — горячие закуски, холодные закуски, первые блюда, десерты, салаты и так далее. Связь между блюдами и категорией выполняется посредством ссылочного поля индекса категории в таблице блюд.
Такой подход позволяет:
- Минимизировать объем базы данных: не нужно каждому блюду прописывать название категории.
- Повысить целостность системы: в указанном примере все блюда привязаны к категориям меню. Добавление блюда без категории невозможно, равно как и указание в качестве ссылки индекса несуществующей категории.
- Упростить масштабирование: новые блюда могут быть добавлены в существующие категории. Также не исключается добавление новых категорий, привязка новых блюд к ним и перераспределение блюд по категориям.
- Повысить отказоустойчивость: за счет оптимальной организации схемы таблиц запросы на выборку и агрегацию будут работать с меньшим объемом данных, а значит, быстрее, чем без нормализации. При увеличении числа записей в таблицах со временем это позволит поддерживать положительный пользовательский опыт.
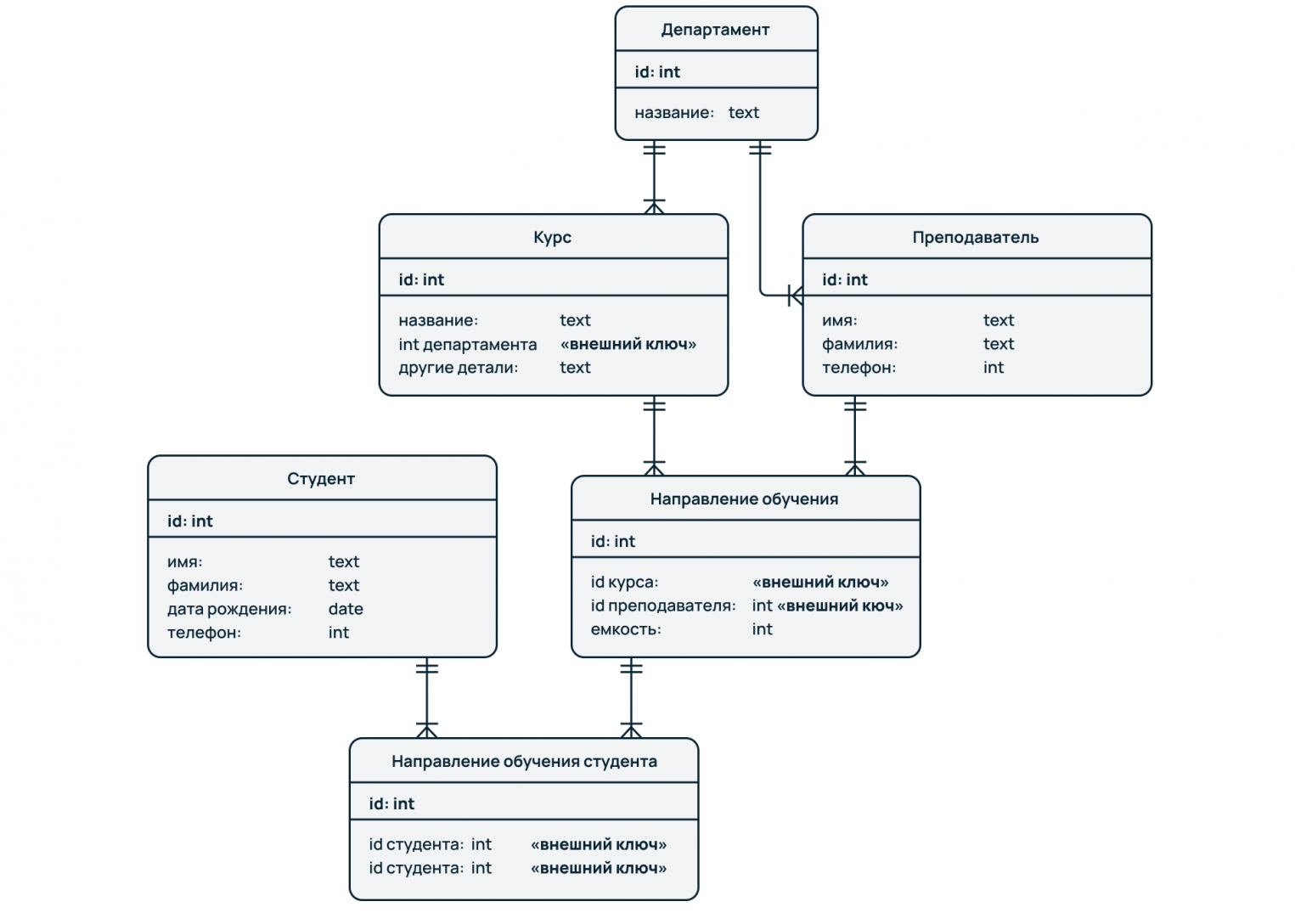
Наглядный пример моделирования сложных взаимоотношений в реляционных БД приведен на рисунке выше. Здесь мы видим модель базы данных учебного заведения, где есть следующие объекты: ученик, курс, преподаватель, отдел, направление обучения.
Связь преподавателя с отделом организована через секцию и курс (внешние ключи id курса и id преподавателя в таблице Секция, а также Отдел в таблице Курс). Связь ученика с направлением обучения реализована через таблицу Направление обучения студента (внешние ключи id студента и id направления обучения).
Таким образом, чтобы посчитать, например, количество студентов на курсе и детализировать статистику по преподавателям, необходимо написать запрос с присоединением учеников к направлению, курсу и преподавателям, сделав соответствующую группировку по преподавателям.
Язык запросов SQL
Запросы в реляционных базах данных формируют с помощью структурированного языка SQL. Его предложения позволяют:
- делать выборки,
- проводить агрегации и группировки,
- изменять и удалять данные,
- модифицировать структуру БД (создавать таблицы, поля),
- управлять доступом пользователей к тем или иным операциям и пр.
Денормализация
Помимо нормализации, в реляционных БД существует и обратный процесс — денормализация. Он направлен на перенос наиболее часто используемых полей из внешних таблиц во внутренние. Рассмотрим это на примере мессенджера.
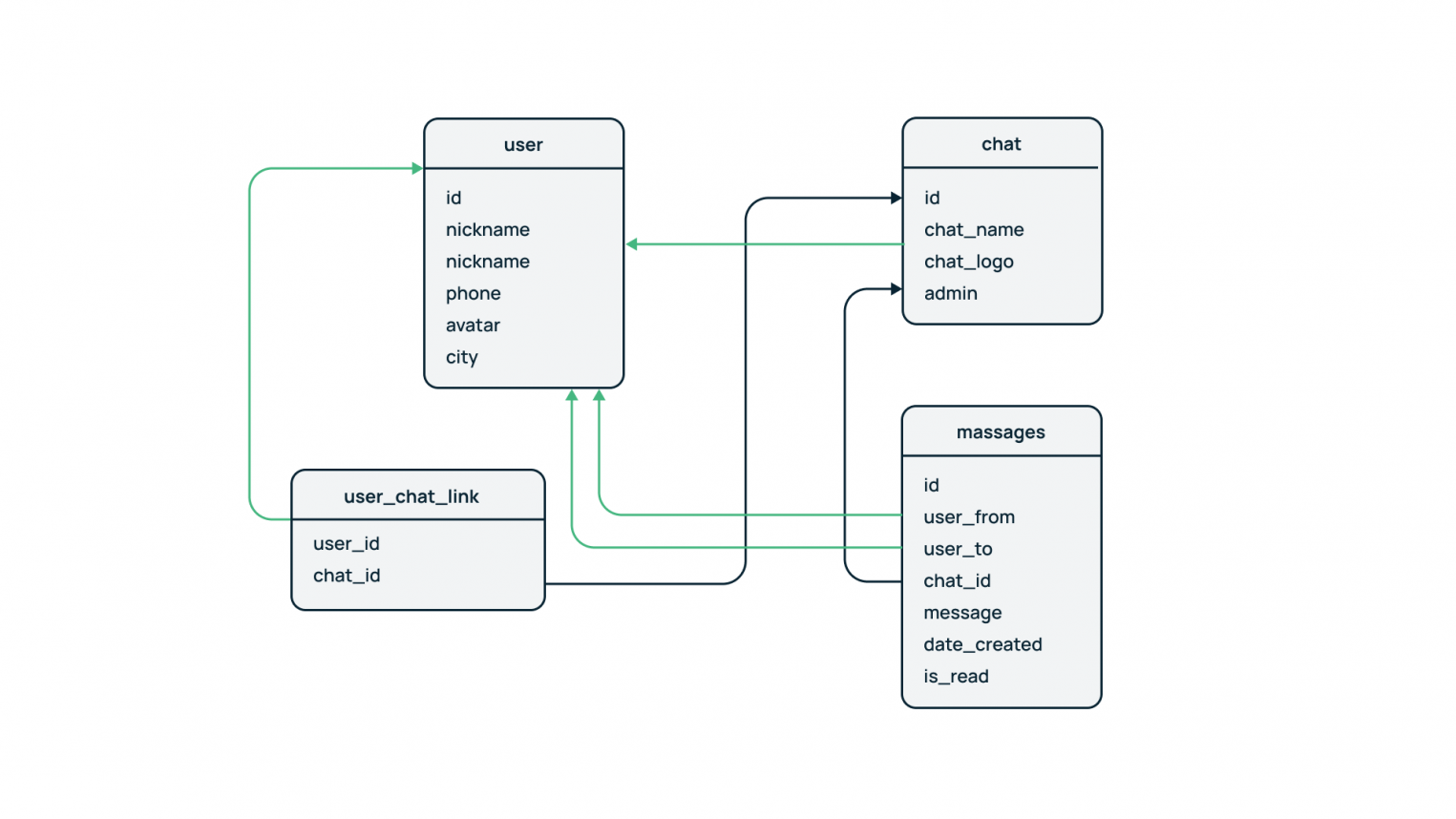
Пользователь (user) оставляет сообщения (messages) в чатах (chat). Структура данных такова, что сообщения связаны с пользователем и чатом через внешние ключи (user_from и user_to, а также chat_id в таблице сообщений; user_id и chat_id в таблице user_chat_link). Поскольку схема нормализована, то различные запросы на выборку, подсчет и агрегацию статистики по чатам, пользователям и сообщениям необходимо выполнять с помощью присоединения внешних таблиц.
На относительно небольших объемах данных эти запросы будут отрабатывать быстро, а с увеличением размера базы – замедляться. Причина кроется в механизме присоединения. Он основан на построчном сравнении двух и более таблиц по условию соединения — например, равенство chat_id в messages и id в chat. А это дает нагрузку на сервер базы данных, которая с ростом ее размера только увеличивается. Для оптимизации такого рода запросов и существует механизм денормализации.
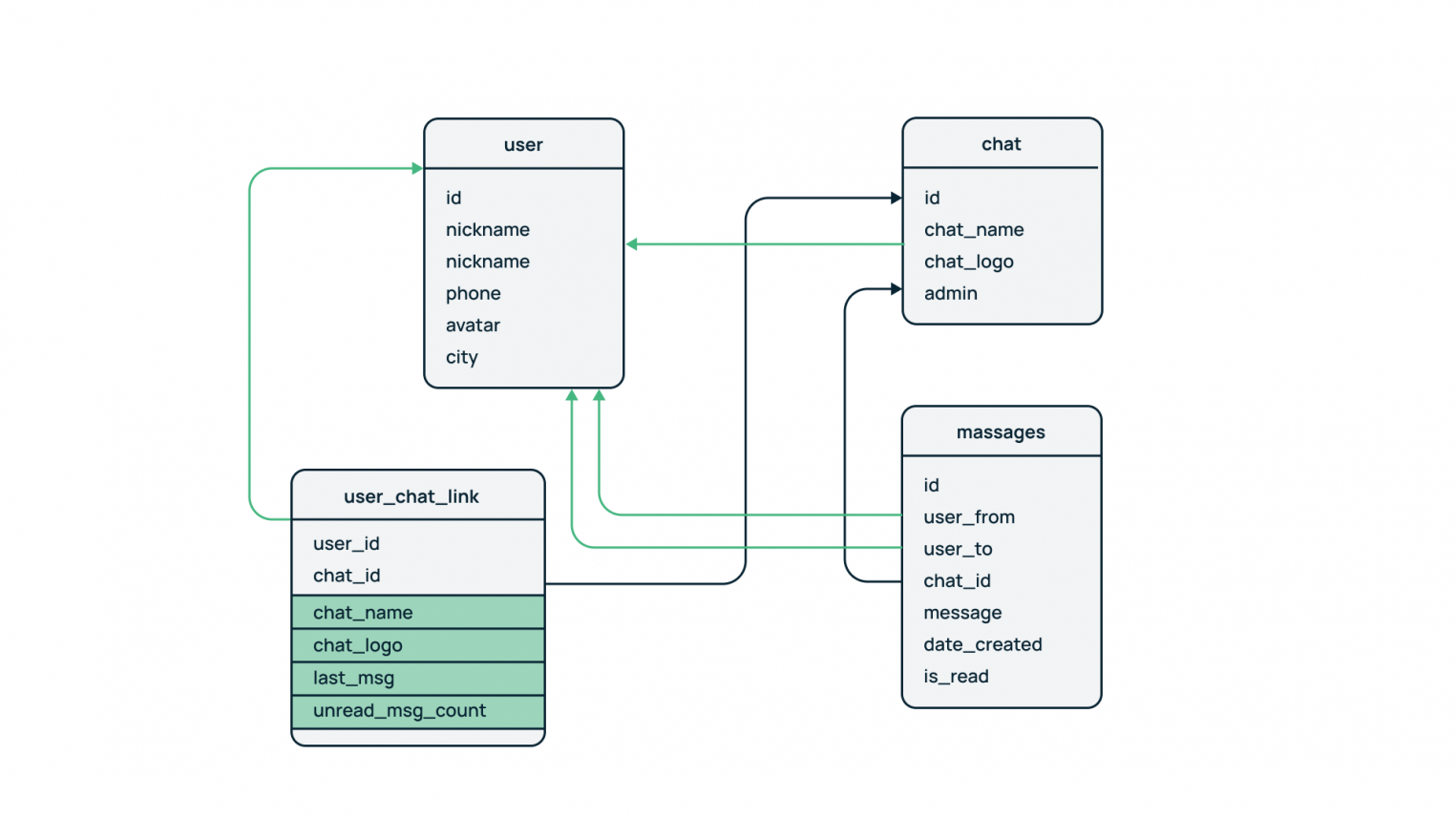
В таблицу связи пользователя и чата user_chat_link добавлены дублирующие поля имени чата (chat_name) и аватара (chat_logo). Также туда выводятся последнее сообщение (last_msg) и количество непрочитанных сообщений (unread_msg_count).
Теперь для получения указанных выше полей и проведения аналитики по ним можно использовать таблицу user_chat_link без необходимости соединения с таблицей сообщений. Тем не менее, такой подход имеет ограничения.
За счет дополнительных полей оптимизируются запросы на чтение и агрегацию данных, однако ценой этого является вынужденная избыточность и усложнение бизнес-логики приложения. В частности, усложняется написание запросов изменения данных (update и delete), а также модификации структуры базы (create).
Использование денормализации должно быть тщательно осмыслено. Нужно быть уверенным в том, что нормализованная структура, оптимизированные запросы и правильно настроенные индексы более не способны удовлетворять критерию быстродействия.
Преимущества реляционного подхода:
- определение сложных отношений между объектами,
- нормализация и денормализация данных,
- структурированный язык запросов,
- богатая история развития и широкое распространение (основной инструмент при разработке различных приложений и сервисов).
Недостатки подхода: жесткая структура сведений об объектах.
Примеры: MySQL, MariaDB, PostgreSQL, SQLite и др.
Реляционные БД
Реляционные базы данных – старейший тип до сих пор широко используемых БД общего назначения. Данные и связи между данными организованы с помощью таблиц. Каждый столбец в таблице имеет имя и тип. Каждая строка представляет отдельную запись или элемент данных в таблице, который содержит значения для каждого из столбцов.
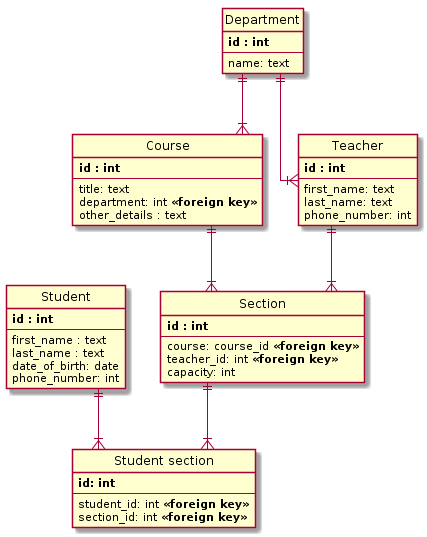
- поле в таблице, называемое внешним ключом, может содержать ссылки на столбцы в других таблицах, что позволяет их соединять;
- высокоорганизованная структура и гибкость делает реляционные БД мощными и адаптируемыми ко различным типам данных;
- для доступа к данным используется язык структурированных запросов (SQL);
- надёжный выбор для многих приложений.
Сравнение SQL и NoSQL
Подавляющее большинство пользователей достаточно давно используют SQL-системы, доверяя их надежности. Наиболее распространена СУБД MySQL. Ниже приведем сравнение SQL и NoSQL, чтобы вы самостоятельно смогли сделать вывод и выбрать наилучший в вашей ситуации вариант.
| SQL | NoSQL | |
|---|---|---|
| Работа с информацией | Строгое стандартизированное представление данных | Способность и свобода обработки любого вида сведений |
| Масштабируемость | Вертикальное масштабирование (увеличение объема системных ресурсов, затрачиваемых на работу с информацией) | Кроме вертикального, применяет и горизонтальное масштабирование |
| Техническая поддержка | Качественное решение проблем благодаря продолжительной жизни системы и накопленного за счет этого опыта | Молодость систем не позволяет оперативно исправлять возникающие ошибки и сбои |
| Формирование запросов | На основе стандартных методов с применением языка SQL | Каждая NoSQL-СУБД использует специфическую технологию |
| Хранение сведений и доступ к ним | Достаточно быстро, удобно и понятно | Часто необходимо детально изучить систему, чтобы облегчить работу, но NoSQL-СУБД продолжают стремительно совершенствоваться и постепенно завоевывают популярность |
| Надежность | Высокая, проверенная не одним годом существования | Тоже достаточно высокая, но пока вызывает меньше доверия |
Как видим, SQL-системы просты, понятны и надежны, но и NoSQL в этом плане не отстают от них и стремятся если не перегнать, то хотя бы догнать по популярности.
Основные понятия и элементы баз данных
Базы данных понадобились тогда, когда возникла потребность хранить большие объёмы однотипной информации, уметь её оперативно использовать. Базами данных (в широком понимании этого слова) пользовались на протяжении всей истории жрецы, чиновники, купцы, ростовщики, алхимики.
Основное требование к базам данных – удобство доступа к данным, возможность оперативно получить исчерпывающую информацию по любому интересующему вопросу (важно не только то, что информация содержится в базе, важно то, насколько она хорошо структирована и целостна).
Лишь только появились и распространились компьютеры, почти сразу на них возложили тяжёлый и кропотливый труд по обработке и структурированию данных, появились базы данных (БД) в их нынешнем понимании.
Согласно современным требованиям к базам данных, информация, содержащаяся в них, должна быть:
- непротиворечивой (не должно быть данных, противоречащих друг другу);
- неизбыточной (следует избегать ненужного дублирования информации в базе, избыточность может привести к противоречивости – например, если какие – то данные изменяют, а их копию в другой части базы забыли изменить);
- целостной (все данные должны быть связаны, не должно быть ссылок на несуществующие в базе данные)
Реляционная модель баз данных была предложена Эдгаром Коддом в конце 70-х годов. В рамках этой модели база данных представляет собой набор таблиц, связанных друг с другом отношениями. При достаточной простоте (а значит, и удобстве реализации на компьютере) данная модель обладает гибкостью, позволяющей описывать сложно структурированные данные. Кроме того, для этой модели достаточно глубоко проработано теоретическое обоснование, что также даёт возможность эффективнее использовать компьютер при создании базы данных и работе с ней. В плане правил связи в реляционной модели реализуется отношение «один–ко–многим» связи между таблицами. Это значит, что одной записи в главной таблице соответствует несколько записей в подчинённой таблице (в том числе может не соответствовать ни одной записи). Другие типы связей: «один-к-одному», «много-к-одному» и «много-ко-многим» — можно свести к данному типу «один-ко-многим». Реляционные базы данных состоят из связанных таблиц.
Таблица представляет собой двумерный массив, в котором хранятся данные. Столбцы таблицы (в рамках принятых обозначений БД) называются полями, строки – записями. Количество полей таблицы фиксировано, количество записей – нет. Фактически таблица – нефиксированный массив записей с одинаковой структурой полей в каждой записи. Добавить в таблицу новую запись не составляет труда, а то время как добавление нового поля влечёт за собой рестрктуризацию всей таблицы и может вызвать определённые трудности. В качестве значений полей в записях могут храниться числа, строки, картинки и т.д. Таблицы баз данных хранятся на жёстком диске (на локальном компьютере или на сервере баз данных – в зависимости от типа БД). Одной таблице соответствуют обычно несколько файлов – один основной и несколько вспомогательных. Тонкости организации таблиц зависят от используемого формата (dBase, Paradox, InterBase, Microsoft Access и т.д.)
Ключ – поле или комбинация полей таблицы, значения в которых однозначно определяют запись. Ключ потому так и называется, что, имея значения ключевых полей, можно однозначно получить доступ к нужной записи. Таким образом, ключи чрезвычайно полезны для связи таблиц. Записывая значения ключа в отведённые поля подчинённой таблицы и тем самым, задавая ссылку, обеспечиваем связь двух записей – записи в главной таблице и записи в подчинённой таблице. В одной записи подчинённой таблицы может находиться и несколько ссылок на записи главной таблицы. Например, в школьном журнале может быть таблица – список дежурств, где в каждой записи содержатся фамилии и имена (ключ их двух полей) нескольких дежурных. Так осуществляется связь различных записей главной таблицы и реализуется достаточно сложная структура данных. В школьной практике в качестве ключевых полей используются имена и фамилии, но в БД лучше отводить специальные ключевые поля – индивидуальные номера (коды) записей. Это гарантированно уберегает от возможных проблем с однофамильцами. В школе же, где не требуется такая компьютерная чёткость, появление в одном классе двух учеников с одинаковыми именами и фамилиями – очень редкое событие, поэтому можно простить подобное техническое упущение. Кроме связывания, ключи могут использоваться для прямого доступа к записям, ускорения работы с таблицей.
Индекс – поле, так же, как и ключ, специально выделенное в таблице, данные в котором, однако, могут повторяться. Они также служат для ускорения доступа и, кроме того, для сортировки и выборок.
Нормальные формы были придуманы, скорее, для автоматизации процесса создания баз данных, нежели как руководство тем, кто создаёт их вручную (автоматическое проектирование больших баз данных может производиться с помощью специальных систем программ – средств (CASE). Реально при ручной разработке проектировщик сразу же задумывает необходимую структуру, планирует нужные таблицы, а не идёт от одной большой таблицы. Нормальные формы фактически формализуют интуитивно понятые требования к организации данных, помогая, прежде всего, избежать избыточного дублирования данных.
Первая нормальная форма:
- информация в полях неделимая (к примеру, имя и фамилия должны быть разными полями, а не одним);
- в таблице нет повторяющихся групп полей
Вторая нормальная форма:
- выполнена первая форма;
- любое неключевое поле однозначно идентифицируется ключевыми полями (фактически, требование наличия ключа)
Третья нормальная форма:
- выполнена вторая форма
- неключевые поля должны однозначно идентифицироваться только ключевыми полями (это значит, что данные, не зависящие от ключа, должны быть вынесены в отдельную таблицу)
Требование третьей нормальной формы имеет тот смысл, что таблицу с полями (Имя, Фамилия, Класс, Классный руководитель) необходимо разбить на две таблицы (Имя, Фамилия, Класс) и (Класс, Классный руководитель), поскольку поле Класс однозначно определяет поле Классный руководитель (а согласно третьей форме, однозначно определять должны только ключи).
Для более глубокого понимания тонкостей проведения операций с записями в таблицах необходимо иметь понятия о способах доступа, транзакциях и бизнес-правилах.
Способы доступа определяют, как технически производятся операции с записями. Способы доступа выбираются программистом во время разработки приложения. Навигационный способ основан на последовательной обработке нужных записей поодиночке. Он обычно используется для небольших локальных таблиц. Реляционный способ основан на обработке сразу набора записей с помощью SQL-запросов. Он используется для больших удалённых БД.
Транзакции определяют надёжность выполнения операций по отношению к сбоям. В транзакцию объединяется последовательность операций, которая либо должна быть выполнена полностью, либо не выполнена совсем. Если во время выполнения транзакции произошёл сбой, то все результаты всех операций, входящих в неё отменяются. Это гарантирует то, что не нарушается корректность базы данных даже в случае технических (а не программных) сбоев.
Бизнес-правила определяют правила проведения операций и представляют механизмы управления БД. Задавая возможные ограничения на значения полей, они также вносят свой вклад в поддержание корректности базы. Несмотря на возможные ассоциации с бизнесом как коммерцией, бизнес-правила не имеют к нему прямого отношения и просто являются правилами управления базами данных.











