Принципы представления данных и команд в компьютере
В настоящее время, в веке информационных технологий, когда потоки информации достигают предела плотности трафика каналов передачи, наряду с задачами обработки информации, возникают наиболее важные задачи ее упорядочивания, хранения и оперативности доступа к ней.
Именно поэтому понимание принципов построения и функционирования, а также грамотное создание и работа с различными структурами хранения данных (файлами, базами данных, файловыми системами), является одним из главных аспектов при подготовке специалистов. Изучение данных вопросов и закрепление практических навыков необходимо для взращивания уверенных пользователей ПК.
Люди имеют дело со многими видами информации. Услышав прогноз погоды, можно записать его в компьютер, чтобы затем воспользоваться им. В компьютер можно поместить фотографию своего друга или видеосъемку о том, как вы провели каникулы. Но ввести в компьютер вкус мороженого или мягкость покрывала никак нельзя.
Компьютер — это электронная машина, которая работает с сигналами. Компьютер может работать только с такой информацией, которую можно превратить в сигналы. Если бы люди умели превращать в сигналы вкус или запах, то компьютер мог бы работать и с такой информацией. У компьютера, очень хорошо, получается, работать с числами. Он может делать с ними все, что угодно. Все числа в компьютере закодированы «двоичным кодом», то есть, представлены с помощью всего двух символов 1 и 0, которые легко представляются сигналами. Вся информация, с которой работает компьютер, кодируется числами. Независимо от того, графическая, текстовая или звуковая эта информация, что бы ее мог обрабатывать центральный процессор она должна тем или иным образом быть представлена числами.
Кодирование текстовой информации и компьютеры
Если смотреть на текст глазами компьютера, то в тексте нет предложений, абзацев, заголовков и т. д., потому что весь текст просто состоит из отдельных символов. Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
Мы вводим текст в компьютер при помощи клавиатуры, символы которой мы прекрасно понимаем. Нажимая на какую-то букву, мы отправляем в оперативную память компьютера двоичное представление нажатых клавиш. Каждый отдельный символ будет представлен 8-битной кодировкой. Например буква «А» — это «11000000». Получается, что один символ — это 1 байт или 8 бит. При такой кодировке, путем нехитрых подсчетов можно посчитать, что мы можем зашифровать 256 символов. Для кодирования текстовой информации данного количества символов более чем предостаточно.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.

Двоичный код
Самый широко используемый метод кодирования информации – двоичное кодирование. Кодирование данных двоичным кодом применяется во всех современных технологиях.
Двоичный (бинарный) код — последовательность нолей и единиц. Это универсальный способ отображения любых информационных сведений (текстовых сообщений, картинок, звуковых и видеоматериалов). Сведения, закодированные в бинарном коде, очень удобно хранить, обрабатывать и передавать с одного электронного устройства на другое, в чем и заключается преимущества использования двоичного кодирования информации.
Двоичное кодирование информации применяется для различных данных:
- двоичное кодирование текстовой информации заключается в присвоении буквенным, цифровым и другим обозначениям определенного кода. Он записывается в компьютерной памяти цепочкой из нулей и единиц. Порядок кодирования алфавита в двоичный код с помощью стандарта ASCII является наглядным примером;
- вид используемой графики влияет на то, каким образом производится двоичное кодирование графической информации;
- двоичное кодирование звуковой информации происходит после дискретизации звуковой волны и присвоения каждому компоненту соответствующего бинарной цепочки чисел;
- кодирование двоичным кодом видеоматериалов сочетает принципы работы со звуком и растровыми изображениями.
Кодировки стандарта UNICODE [ править ]
Юникод или Уникод (англ. Unicode) — это промышленный стандарт обеспечивающий цифровое представление символов всех письменностей мира, и специальных символов.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей. Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа.Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F. Часть кодов зарезервирована для использования в будущем.
Кодовое пространство [ править ]
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до [math]2^[/math] [math](2 147 483 648)[/math] кодовых позиций, было принято решение использовать лишь [math]1 112 064[/math] для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно — в версии 6.0 используется чуть менее [math]110 000[/math] кодовых позиций ( [math]109 242[/math] графических и [math]273[/math] прочих символов).
Кодовое пространство разбито на [math]17[/math] плоскостей (англ. planes) по [math]2^[/math] [math](65 536)[/math] символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая — для для редко используемых иероглифов китайского письма, третья зарезервирована для архаичных китайских иероглифов. Плоскости [math]15[/math] и [math]16[/math] выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx» (для кодов [math]0000_..FFFF_[/math] ) или «U+xxxxx» (для кодов [math]10000_..FFFFF_[/math] ) или «U+xxxxxx» (для кодов [math]100000_..10FFFF_[/math] ), где xxx — шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код [math]044F_ = 1103_[/math] .
| Плоскости Юникода | ||
|---|---|---|
| Плоскость | Название | Диапазон символов |
| Plane 0 | Basic multilingual plane (BMP) | U+0000…U+FFFF |
| Plane 1 | Supplementary multilingual plane (SMP) | U+10000…U+1FFFF |
| Plane 2 | Supplementary ideographic plane (SIP) | U+20000…U+2FFFF |
| Planes 3-13 | Unassigned | U+30000…U+DFFFF |
| Plane 14 | Supplementary special-purpose plane (SSP) | U+E0000…U+EFFFF |
| Planes 15-16 | Supplementary private use area (S PUA A/B) | U+F0000…U+10FFFF |
Модифицирующие символы [ править ]
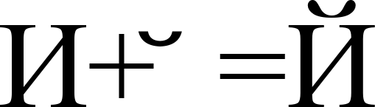
Графические символы в Юникоде делятся на протяжённые и непротяжённые. Непротяжённые символы при отображении не занимают дополнительного места в строке. К примеру, к ним относятся знак ударения. Протяжённые и непротяжённые символы имеют собственные коды, но последние не могут встречаться самостоятельно. Протяжённые символы называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters). Например символ «Й» (U+0419) может быть представлен в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306).
Способы представления [ править ]
Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт.
UTF-8 [ править ]
UTF-8 — представление Юникода, обеспечивающее наилучшую совместимость со старыми системами, использовавшими [math]8[/math] -битные символы. Текст, состоящий только из символов с номером меньше [math]128[/math] , при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше [math]128[/math] изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от двух до шести байт (на деле, только до четырех байт, поскольку в Юникоде нет символов с кодом больше [math]10FFFF_[/math] , и вводить их в будущем не планируется), в которых первый байт всегда имеет вид [math]11xxxxxx[/math] , а остальные — [math]10xxxxxx[/math] .
Символы UTF-8 получаются из Unicode cледующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
| 0x00000000 — 0x0000007F | 0xxxxxxx | ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
| 0x00000080 — 0x000007FF | 110xxxxx 10xxxxxx | кириллица, расширенная латиница, арабский алфавит, армянский алфавит, греческий алфавит, еврейский алфавит и коптский алфавит; сирийское письмо, тана, нко; Международный фонетический алфавит; некоторые знаки препинания |
| 0x00000800 — 0x0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx | все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
| 0x00010000 — 0x001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
| 111111xx | служебные символы c, d, e, f |
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы, называемые overlong sequence, отвергаются по соображениям безопасности.
Принцип кодирования [ править ]
Правила записи кода одного символа в UTF-8 [ править ]
1. Если размер символа в кодировке UTF-8 = [math]1[/math] байт
Код имеет вид (0aaa aaaa), где «0» — просто ноль, остальные биты «a» — это код символа в кодировке ASCII;
2. Если размер символа в кодировке в UTF-8 [math]gt 1[/math] байт (то есть от [math]2[/math] до [math]6[/math] ):
2.1 Первый байт содержит количество байт символа, закодированное в единичной системе счисления; 2.2 «0» — бит терминатор, означающий завершение кода размера 2.3 далее идут значащие байты кода, которые имеют вид (10xx xxxx), где «10» — биты признака продолжения, а «x» — значащие биты.
В общем случае варианты представления одного символа в кодировке UTF-8 выглядят так:
Определение длины кода в UTF-8 [ править ]
| Количество байт UTF-8 | Количество значащих бит |
|---|---|
| [math]1[/math] | [math]7[/math] |
| [math]2[/math] | [math]11[/math] |
| [math]3[/math] | [math]16[/math] |
| [math]4[/math] | [math]21[/math] |
| [math]5[/math] | [math]26[/math] |
| [math]6[/math] | [math]31[/math] |
В общем случае количество значащих бит [math]C[/math] , кодируемых [math]n[/math] байтами UTF-8, определяется по формуле:
[math]C = 7[/math] при [math]n=1[/math]
[math]C = ncdot5+1[/math] при [math]ngt 1[/math]
UTF-16 [ править ]
UTF-16 — один из способов кодирования символов (англ. code point) из Unicode в виде последовательности [math]16[/math] -битных слов (англ. code unit). Данная кодировка позволяет записывать символы Юникода в диапазонах U+0000..U+D7FF и U+E000..U+10FFFF (общим количеством [math]1 112 064[/math] ), причем [math]2[/math] -байтные символы представляются как есть, а более длинные — с помощью суррогатных пар (англ. surrogate pair), для которых и вырезан диапазон [math]D800_..DFFF_[/math] .
В UTF-16 символы кодируются двухбайтовыми словами с использованием всех возможных диапазонов значений (от [math]0000_[/math] до [math]FFFF_[/math] ). При этом можно кодировать символы Unicode в диапазонах [math]0000_..D7FF_[/math] и [math]E000_..10FFFF_[/math] . Исключенный отсюда диапазон [math]D800_..DFFF_[/math] используется как раз для кодирования так называемых суррогатных пар — символов, которые кодируются двумя [math]16[/math] -битными словами. Символы Unicode до [math]FFFF_[/math] включительно (исключая диапазон для суррогатов) записываются как есть [math]16[/math] -битным словом. Символы же в диапазоне [math]10000_..10FFFF_[/math] (больше [math]16[/math] бит) уже кодируются парой [math]16[/math] -битных слов. Для этого их код арифметически сдвигается до нуля (из него вычитается минимальное число [math]10000_[/math] ). В результате получится значение от нуля до [math]FFFFF_[/math] , которое занимает до [math]20[/math] бит. Старшие [math]10[/math] бит этого значения идут в лидирующее (первое) слово, а младшие [math]10[/math] бит — в последующее (второе). При этом в обоих словах старшие [math]6[/math] бит используются для обозначения суррогата. Биты с [math]11[/math] по [math]15[/math] имеют значения [math]11011_2[/math] , а [math]10[/math] -й бит содержит [math]0[/math] у лидирующего слова и [math]1[/math] — у последующего. В связи с этим можно легко определить к чему относится каждое слово.
UTF-16LE и UTF-16BE [ править ]
Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт. Который из двух байт в словах идёт впереди, старший или младший, зависит от порядка байт. Подробнее об этом будет сказано ниже.
UTF-32 [ править ]
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно [math]32[/math] бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Главное преимущество UTF-32 перед кодировками переменной длины заключается в том, что символы Юникод непосредственно индексируемы. Получение [math]n[/math] -ой кодовой позиции является операцией, занимающей одинаковое время. Напротив, коды с переменной длиной требует последовательного доступа к [math]n[/math] -ой кодовой позиции. Это делает замену символов в строках UTF-32 простой, для этого используется целое число в качестве индекса, как обычно делается для строк ASCII.
Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства не оправдано.
Хотя использование неменяющегося числа байт на символ удобно, но не настолько, как кажется. Операция усечения строк реализуется легче в сравнении с UTF-8 и UTF-16. Но это не делает более быстрым нахождение конкретного смещения в строке, так как смещение может вычисляться и для кодировок фиксированного размера. Это не облегчает вычисление отображаемой ширины строки, за исключением ограниченного числа случаев, так как даже символ «фиксированной ширины» может быть получен комбинированием обычного символа с модифицирующим, который не имеет ширины. Например, буква «й» может быть получена из буквы «и» и диакритического знака «крючок над буквой». Сочетание таких знаков означает, что текстовые редакторы не могут рассматривать [math]32[/math] -битный код как единицу редактирования. Редакторы, которые ограничиваются работой с языками с письмом слева направо и составными символами (англ. Precomposed character), могут использовать символы фиксированного размера. Но такие редакторы вряд ли поддержат символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства и вряд ли смогут работать одинаково хорошо с символами UTF-16.
Порядок байт [ править ]
В современной вычислительной технике и цифровых системах связи информация обычно представлена в виде последовательности байт. В том случае, если число не может быть представлено одним байтом, имеет значение в каком порядке байты записываются в памяти компьютера или передаются по линиям связи. Часто выбор порядка записи байт произволен и определяется только соглашениями.
В общем случае, для представления числа [math]M[/math] , большего [math]255[/math] (здесь [math]255=2^8-1[/math] — максимальное целое число, записываемое одним байтом), приходится использовать несколько байт. При этом число [math]M[/math] записывается в позиционной системе счисления по основанию [math]256[/math] :
[math]M = sum_^A_icdot 256^i=A_0cdot 256^0+A_1cdot 256^1+A_2cdot 256^2+dots+A_ncdot 256^n.[/math]
Набор целых чисел [math]A_0,dots,A_n[/math] , каждое из которых лежит в интервале от [math]0[/math] до [math]255[/math] , является последовательностью байт, составляющих [math]M[/math] . При этом [math]A_0[/math] называется младшим байтом, а [math]A_n[/math] — старшим байтом числа [math]M[/math] .
Варианты записи [ править ]
Порядок от старшего к младшему [ править ]
Порядок от старшего к младшему (англ. big-endian): [math]A_n,dots,A_0[/math] , запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP, он используется в заголовках пакетов данных и во многих протоколах более высокого уровня, разработанных для использования поверх TCP/IP. Поэтому, порядок байт от старшего к младшему часто называют сетевым порядком байт (англ. network byte order). Этот порядок байт используется процессорами IBM 360/370/390, Motorola 68000, SPARC (отсюда третье название — порядок байт Motorola, Motorola byte order).
В этом же виде (используя представление в десятичной системе счисления) записываются числа индийско-арабскими цифрами в письменностях с порядком знаков слева направо (латиница, кириллица). Для письменностей с обратным порядком (арабская) та же запись числа воспринимается как «от младшего к старшему».
Порядок байт от старшего к младшему применяется во многих форматах файлов — например, PNG, FLV, EBML.
Порядок от младшего к старшему [ править ]
Порядок от младшего к старшему (англ. little-endian): [math]A_0,dots,A_n[/math] , запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86-процессорами, в связи с чем иногда его называют интеловский порядок байт (по названию фирмы-создателя архитектуры x86).
В противоположность порядку big-endian, соглашение little-endian поддерживают меньше кросс-платформенных протоколов и форматов данных; существенные исключения: USB, конфигурация PCI, таблица разделов GUID, рекомендации FidoNet.
Переключаемый порядок [ править ]
Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байт выбирается программно во время инициализации операционной системы, но может быть выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байт операционной системы. Переключаемый порядок байт иногда называют англ. bi-endian.
Смешанный порядок [ править ]
Смешанный порядок байт (англ. middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Число представляется последовательностью машинных слов, которые записываются в формате, естественном для данной архитектуры, но сами слова следуют в обратном порядке.
Классический пример middle-endian — представление [math]4[/math] -байтных целых чисел на [math]16[/math] -битных процессорах семейства PDP-11 (известен как PDP-endian). Для представления двухбайтных значений (слов) использовался порядок little-endian, но [math]4[/math] -хбайтное двойное слово записывалось от старшего слова к младшему.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Различия [ править ]

Существенным достоинством little-endian по сравнению с big-endian порядком записи считается возможность «неявной типизации» целых чисел при чтении меньшего объёма байт (при условии, что читаемое число помещается в диапазон). Так, если в ячейке памяти содержится число [math]00000022_[/math] , то прочитав его как int16 (два байта) мы получим число [math]0022_[/math] , прочитав один байт — число [math]22_[/math] . Однако, это же может считаться и недостатком, потому что провоцирует ошибки потери данных.
Обратно, считается что у little-endian, по сравнению с big-endian есть «неочевидность» значения байт памяти при отладке (последовательность байт (A1, B2, C3, D4) на самом деле значит [math]D4C3B2A1_[/math] , для big-endian эта последовательность (A1, B2, C3, D4) читалась бы «естественным» для арабской записи чисел образом: [math]A1B2C3D4_[/math] ). Наименее удобным в работе считается middle-endian формат записи; он сохранился только на старых платформах.
Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся от младших разрядов к старшим). Порядок байт в слове — обычный для данной архитектуры.
Маркер последовательности байт [ править ]
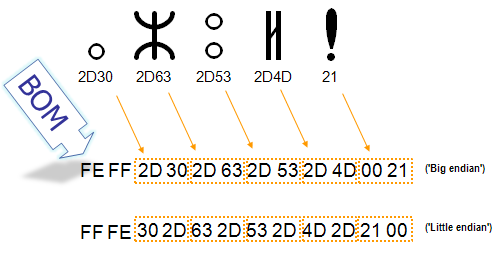
Для определения формата представления Юникода в начало текстового файла записывается сигнатура — символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый маркером последовательности байт (англ. byte order mark (BOM)). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует.
| Кодирование | Представление (Шестнадцатеричное) |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16 (BE) | FE FF |
| UTF-16 (LE) | FF FE |
| UTF-32 (BE) | 00 00 FE FF |
| UTF-32 (LE) | FF FE 00 00 |
В кодировке UTF-8, наличие BOM не является существенным, поскольку, нет альтернативной последовательности байт. Когда BOM используется на страницах или редакторах для контента закодированного в UTF-8, иногда он может представить пробелы или короткие последовательности символов, имеющие странный вид (такие как ). Именно поэтому, при наличии выбора, для совместимости, как правило, лучше упустить BOM в UTF-8 контенте.Однако BOM могут еще встречаться в тексте закодированном в UTF-8, как побочный продукт перекодирования или потому, что он был добавлен редактором. В этом случае BOM часто называют подписью UTF-8.
Когда символ закодирован в UTF-16, его [math]2[/math] или [math]4[/math] байта можно упорядочить двумя разными способами (little-endian или big-endian). Изображение справа показывает это. Byte order mark указывает, какой порядок используется, так что приложения могут немедленно расшифровать контент. UTF-16 контент должен всегда начинатся с BOM.
BOM также используется для текста обозначенного как UTF-32. Аналогично UTF-16 существует два варианта четырёхбайтной кодировки — UTF-32BE и UTF-32LE. К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом
Проблемы Юникода [ править ]
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.











