Лекции по дисциплине «параллельные и распределенные вычисления» Введение Применение параллельных вычислительных систем (пвс)
— дублирование устройств ЭВМ путем использования, например, нескольких однотипных обрабатывающих процессоров или нескольких устройств оперативной памяти.
Дополнительной формой обеспечения параллелизма может служить конвейерная реализация обрабатывающих устройств, при которой выполнение операций в устройствах представляется в виде исполнения последовательности составляющих операцию подкоманд. Как результат, при вычислениях на таких устройствах на разных стадиях обработки могут находиться одновременно несколько различных элементов данных.
- многозадачный режим (режим разделения времени), при котором для выполнения нескольких процессов используется единственный процессор. Данный режим является псевдопараллельным, когда активным (исполняемым) может быть один, единственный процесс, а все остальные процессы находятся в состоянии ожидания своей очереди; применение режима разделения времени может повысить эффективность организации вычислений (например, если один из процессов не может выполняться из-за ожидания вводимых данных, процессор может быть задействован для выполнения другого, готового к исполнению процесса – см. [73]). Кроме того, в данном режиме проявляются многие эффекты параллельных вычислений (необходимость взаимоисключения и синхронизации процессов и др.), и, как результат, этот режим может быть использован при начальной подготовке параллельных программ;
- параллельное выполнение, когда в один и тот же момент может выполняться несколько команд обработки данных. Такой режим вычислений может быть обеспечен не только при наличии нескольких процессоров, но и при помощи конвейерных и векторных обрабатывающих устройств;
- распределенные вычисления; данный термин обычно применяют для указания параллельной обработки данных, при которой используется несколько обрабатывающих устройств, достаточно удаленных друг от друга, в которых передача данных по линиям связи приводит к существенным временным задержкам. Как результат, эффективная обработка данных при таком способе организации вычислений возможна только для параллельных алгоритмов с низкой интенсивностью потоков межпроцессорных передач данных. Перечисленные условия являются характерными, например, при организации вычислений в многомашинных вычислительных комплексах, образуемых объединением нескольких отдельных ЭВМ с помощью каналов связи локальных или глобальных информационных сетей.
Обмен данными

Как компьютерные кластеры появились в 1980-х годах, так и суперкомпьютеры . Одним из элементов, которые отличали эти три класса в то время, было то, что первые суперкомпьютеры полагались на разделяемую память . На сегодняшний день кластеры обычно не используют физически разделяемую память, хотя многие архитектуры суперкомпьютеров также отказались от нее.
Однако использование кластерной файловой системы необходимо в современных компьютерных кластерах. [ необходима ссылка ] Примеры включают IBM General Parallel File System , Microsoft Cluster Shared Volumes или Oracle Cluster File System .
Рабочая станция
Рабочая станция (англ. Workstation) — комплекс технических и программных средств, предназначенных для решения определенного круга задач.
- Рабочая станция — как место работы специалиста представляет собой полноценный компьютер или компьютерный терминал (устройство ввода / вывода информации, отделенные часто отдаленные от управляющего компьютера), набор необходимого программного обеспечения, при необходимости может дополняться вспомогательным оборудованием: принтер, внешнее устройство хранения данных на магнитных и / или оптических носителях, сканер штрих-кода и др.
- Также термином «рабочая станция» обозначают компьютер в составе локальной вычислительной сети относительно сервера. Компьютеры в локальной сети подразделяются на рабочие станции и серверы. На рабочих станциях пользователи решают прикладные задачи (работают в базах данных, создают документы, выполняют расчеты). Сервер обслуживает сеть и предоставляет собственные ресурсы всем узлам сети, в том числе и рабочим станциям.
Существуют достаточно устойчивые признаки конфигураций рабочих станций, предназначенных для решения определенного круга задач, позволяет отделять их в отдельный профессиональный подкласс: мультимедиа (обработка изображений, видео, звука), САПР (системы автоматизированного проектирования и т.д.).

Каждый такой подкласс может иметь присущие ему особенности и уникальные компоненты, например:
- большой размер монитора и / или несколько мониторов (САПР),
- быстродействующая графическая плата (обработка видео и мультипликация, компьютерные игры),
- большой объем накопителей данных,
- наличие сканера (работа с изображением),
- защищенное исполнение (вооруженные силы, секретные базы данных) и другие.
История
История создания кластеров неразрывно связана с ранними разработками в области компьютерных сетей. Одной из причин для появления скоростной связи между компьютерами стали надежды на объединение вычислительных ресурсов. В начале 1970-х годов группой разработчиков протокола TCP/IP и лабораторией Xerox PARC были закреплены стандарты сетевого взаимодействия. Появилась и операционная система Hydra для компьютеров PDP-11 производства DEC, созданный на этой основе кластер был назван C.mpp (Питтсбург, штат Пенсильвания, США, 1971 год). Тем не менее, только около 1983 года были созданы механизмы, позволяющие с лёгкостью пользоваться распределением задач и файлов через сеть, по большей части это были разработки в SunOS (операционной системе на основе BSD от компании Sun Microsystems).
Первым коммерческим проектом кластера стал ARCNet, созданный компанией Datapoint в 1977 году. Прибыльным он не стал, и поэтому строительство кластеров не развивалось до 1984 года, когда DEC построила свой VAXcluster на основе операционной системы VAX/VMS. ARCNet и VAXcluster были рассчитаны не только на совместные вычисления, но и совместное использование файловой системы и периферии с учётом сохранения целостности и однозначности данных. VAXCluster (называемый теперь VMSCluster) — является неотъемлемой компонентой операционной системы HP OpenVMS, использующих процессоры DEC Alpha и Itanium.
Два других ранних кластерных продукта, получивших признание, включают Tandem Hymalaya (1994, класс HA) и IBM S/390 Parallel Sysplex (1994).
История создания кластеров из обыкновенных персональных компьютеров во многом обязана проекту Parallel Virtual Machine. В 1989 году это программное обеспечение для объединения компьютеров в виртуальный суперкомпьютер открыло возможность мгновенного создания кластеров. В результате суммарная производительность всех созданных тогда дешёвых кластеров обогнала по производительности сумму мощностей «серьёзных» коммерческих систем.
Создание кластеров на основе дешёвых персональных компьютеров, объединённых сетью передачи данных, продолжилось в 1993 году силами Американского аэрокосмического агентства NASA, затем в 1995 году получили развитие кластеры Beowulf, специально разработанные на основе этого принципа. Успехи таких систем подтолкнули развитие grid-сетей, которые существовали ещё с момента создания UNIX.
Кластер – единица хранения данных
Наиболее часто с понятием «кластер» пользователи компьютера сталкивается при форматировании флешки, диска либо какого-нибудь другого носителя информации.
На рисунке диалоговые окно форматирования диска на операционной системе Windows 7. Это окно практически не отличается в разных ОС семейства Windows.
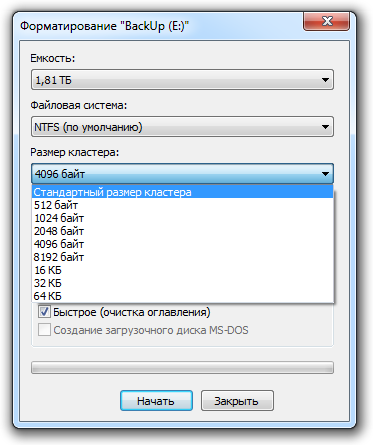
В диалоговом окне мы видим, что один из параметров форматирования носит название «Размер кластера». Давайте вместе разберемся, что такое кластер и зачем так важно определять его размер.
Начнём того, что файл на диск записывается небольшими частями, эти части совсем не обязательно идут друг за другом, порой они раскиданы по всему диску. Удаляя файл, мы очищаем эти части от информации, записывая — мы заполняем их снова. Понятно, что записывая и удаляя файлы, мы как бы перемешиваем информацию на диске.
Чтобы прочитать файл, жесткому диску приходится считывать её из с разных участков своей памяти. Думаю, понятно, что считывание информации с различных областей диска может существенно замедлять работу системы, ведь гораздо проще считывать информацию последовательно, чем прыгать с места на место.
Понятие кластер, в нашем случае, как раз и относится к этим участкам носителя информации. Кластер – это участки памяти на диске, имеющие определенный заданный объем, являющийся минимальным для хранения файлов.
Чем больше кластер, тем меньше переходов совершит система при считывании информации и тем быстрее будет работать система. Но не все так просто, как кажется на первый взгляд! Кластер может быть занят данными только из одного файла и если даже файл по своему объёму меньше размера кластера, то фактически он будет занимать размер целого кластера. Если размер файла, разделить на размер кластера, то остаток от деления все равно займется одним кластером. Таким образом, возникает дилемма, чем жертвовать — скоростью работы или свободным местом на жёстком диске.
Содержание
Обозначаются аббревиатурой HA (англ. High Availability — высокая доступность). Создаются для обеспечения высокой доступности сервиса, предоставляемого кластером. Избыточное число узлов, входящих в кластер, гарантирует предоставление сервиса в случае отказа одного или нескольких серверов. Типичное число узлов — два, это минимальное количество, приводящее к повышению доступности. Создано множество программных решений для построения такого рода кластеров.
Отказоустойчивые кластеры и системы разделяются на 3 основных типа:
- с холодным резервом или активный/пассивный. Активный узел выполняет запросы, а пассивный ждет его отказа и включается в работу, когда таковой произойдет. Пример — резервные сетевые соединения, в частности, Алгоритм связующего дерева. Например, связка DRBD и HeartBeat/Corosync.
- с горячим резервом или активный/активный. Все узлы выполняют запросы, в случае отказа одного нагрузка перераспределяется между оставшимися. То есть кластер распределения нагрузки с поддержкой перераспределения запросов при отказе. Примеры — практически все кластерные технологии, например, Microsoft Cluster Server. OpenSource проект OpenMosix.
- с модульной избыточностью. Применяется только в случае, когда простой системы совершенно недопустим. Все узлы одновременно выполняют один и тот же запрос (либо части его, но так, что результат достижим и при отказе любого узла), из результатов берется любой. Необходимо гарантировать, что результаты разных узлов всегда будут одинаковы (либо различия гарантированно не повлияют на дальнейшую работу). Примеры — RAID и Triple modular redundancy.
Конкретная технология может сочетать данные принципы в любой комбинации. Например, Linux-HA поддерживает режим обоюдной поглощающей конфигурации (англ. takeover ), в котором критические запросы выполняются всеми узлами вместе, прочие же равномерно распределяются между ними. [1]
Кластер – единица хранения данных
Наиболее часто с понятием «кластер» пользователи компьютера сталкивается при форматировании флешки, диска либо какого-нибудь другого носителя информации.
На рисунке диалоговые окно форматирования диска на операционной системе Windows 7. Это окно практически не отличается в разных ОС семейства Windows.

В диалоговом окне мы видим, что один из параметров форматирования носит название «Размер кластера». Давайте вместе разберемся, что такое кластер и зачем так важно определять его размер.
Начнём того, что файл на диск записывается небольшими частями, эти части совсем не обязательно идут друг за другом, порой они раскиданы по всему диску. Удаляя файл, мы очищаем эти части от информации, записывая — мы заполняем их снова. Понятно, что записывая и удаляя файлы, мы как бы перемешиваем информацию на диске.
Чтобы прочитать файл, жесткому диску приходится считывать её из с разных участков своей памяти. Думаю, понятно, что считывание информации с различных областей диска может существенно замедлять работу системы, ведь гораздо проще считывать информацию последовательно, чем прыгать с места на место.
Понятие кластер, в нашем случае, как раз и относится к этим участкам носителя информации. Кластер – это участки памяти на диске, имеющие определенный заданный объем, являющийся минимальным для хранения файлов.
Чем больше кластер, тем меньше переходов совершит система при считывании информации и тем быстрее будет работать система. Но не все так просто, как кажется на первый взгляд! Кластер может быть занят данными только из одного файла и если даже файл по своему объёму меньше размера кластера, то фактически он будет занимать размер целого кластера. Если размер файла, разделить на размер кластера, то остаток от деления все равно займется одним кластером. Таким образом, возникает дилемма, чем жертвовать — скоростью работы или свободным местом на жёстком диске.
Содержание
Кластеры высокой доступности
Обозначаются аббревиатурой HA (High Availability — высокая доступность). Создаются для обеспечения высокой доступности сервиса, предоставляемого кластером. Избыточное число узлов, входящих в кластер, гарантирует предоставление сервиса в случае отказа одного или нескольких серверов. Типичное число узлов — два, это минимальное количество, приводящее к повышению доступности. Создано множество программных решений для построения такого рода кластеров.
Отказоустойчивые кластеры и системы вообще строятся по трем основным принципам:
- с холодным резервом или активный/пассивный. Активный узел выполняет запросы, а пассивный ждет его отказа и включается в работу, когда таковой произойдет. Пример — резервные сетевые соединения, в частности, Алгоритм связующего дерева. Например связка DRBD и HeartBeat.
- с горячим резервом или активный/активный. Все узлы выполняют запросы, в случае отказа одного нагрузка перераспределяется между оставшимися. То есть кластер распределения нагрузки с поддержкой перераспределения запросов при отказе. Примеры — практически все кластерные технологии, например, Microsoft Cluster Server. OpenSource проект OpenMosix.
- с модульной избыточностью. Применяется только в случае, когда простой системы совершенно недопустим. Все узлы одновременно выполняют один и тот же запрос (либо части его, но так, что результат достижим и при отказе любого узла), из результатов берется любой. Необходимо гарантировать, что результаты разных узлов всегда будут одинаковы (либо различия гарантированно не повлияют на дальнейшую работу). Примеры — RAID и Triple modular redundancy.
Кластеры распределения нагрузки
Принцип их действия строится на распределении запросов через один или несколько входных узлов, которые перенаправляют их на обработку в остальные, вычислительные узлы. Первоначальная цель такого кластера — производительность, однако, в них часто используются также и методы, повышающие надёжность. Подобные конструкции называются серверными фермами. Программное обеспечение (ПО) может быть как коммерческим (OpenVMS, MOSIX, Platform LSF HPC, Solaris Cluster, Moab Cluster Suite, Maui Cluster Scheduler), так и бесплатным (OpenMosix, Sun Grid Engine, Linux Virtual Server).
Вычислительные кластеры
Кластеры используются в вычислительных целях, в частности в научных исследованиях. Для вычислительных кластеров существенными показателями являются высокая производительность процессора в операциях над числами с плавающей точкой (flops) и низкая латентность объединяющей сети, и менее существенными — скорость операций ввода-вывода, которая в большей степени важна для баз данных и web-сервисов. Вычислительные кластеры позволяют уменьшить время расчетов, по сравнению с одиночным компьютером, разбивая задание на параллельно выполняющиеся ветки, которые обмениваются данными по связывающей сети. Одна из типичных конфигураций — набор компьютеров, собранных из общедоступных компонентов, с установленной на них операционной системой Linux, и связанных сетью Ethernet, Myrinet, InfiniBand или другими относительно недорогими сетями. Такую систему принято называть кластером Beowulf. Специально выделяют высокопроизводительные кластеры (Обозначаются англ. аббревиатурой HPC Cluster — High-performance computing cluster). Список самых мощных высокопроизводительных компьютеров (также может обозначаться англ. аббревиатурой HPC) можно найти в мировом рейтинге TOP500. В России ведется рейтинг самых мощных компьютеров СНГ.
Системы распределенных вычислений (grid)
Такие системы не принято считать кластерами, но их принципы в значительной степени сходны с кластерной технологией. Их также называют grid-системами. Главное отличие — низкая доступность каждого узла, то есть невозможность гарантировать его работу в заданный момент времени (узлы подключаются и отключаются в процессе работы), поэтому задача должна быть разбита на ряд независимых друг от друга процессов. Такая система, в отличие от кластеров, не похожа на единый компьютер, а служит упрощённым средством распределения вычислений. Нестабильность конфигурации, в таком случае, компенсируется больши́м числом узлов.
Кластер серверов, организуемых программно
Кластер серверов (в информационных технологиях) — группа серверов, объединённых логически, способных обрабатывать идентичные запросы и использующихся как единый ресурс. Чаще всего серверы группируются посредством локальной сети. Группа серверов обладает большей надежностью и большей производительностью, чем один сервер. Объединение серверов в один ресурс происходит на уровне программных протоколов.
В отличие от аппаратного кластера компьютеров, кластеры организуемые программно, требуют:
- наличия специального программного модуля (Cluster Manager), основной функцией которого является поддержание взаимодействия между всеми серверами — членами кластера:
- синхронизации данных между всеми серверами — членами кластера;
- распределение нагрузки (клиентских запросов) между серверами — членами кластера;
- если клиентская программа не умеет распознавать кластер, она будет работать только с тем сервером, к которому обратилась изначально, а при попытке Cluster Manager перераспределить запрос на другие серверы, клиентская программа может вообще лишиться доступа к этому серверу (результат зависит от конкретной реализации кластера).
Применение
В большинстве случаев, кластеры серверов функционируют на раздельных компьютерах. Это позволяет повышать производительность за счёт распределения нагрузки на аппаратные ресурсы и обеспечивает отказоустойчивость на аппаратном уровне.
Однако, принцип организации кластера серверов (на уровне программного протокола) позволяет исполнять по нескольку программных серверов на одном аппаратном. Такое использование может быть востребовано:
Объединение серверов в кластеры
На ноде proxmox имеем интерфейс eth0, который подключен к физическому порту коммутатора.
192.168.1.100 — proxmox (нода)
Необходимо создать сетевой мост vmbr0.
Мост является виртуальной реализацией физического коммутатора. Виртуальные машины подключаются к мосту как подключаются компьютеры кабелем к обычному коммутатору.
Все подключенные виртуальные машины к сетевому мосту могут обмениваться между собой данными.
Если мост подключен к физическому интерфейсу — виртуальные машины могут обмениваться данными с внешними сетевыми устройствами.

Чтобы виртуальные машины имели доступ во внешнюю физическую сеть (eth0) делаем следующее:











