Представление символов, таблицы кодировок
В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
Количество символов, которые можно задать последовательностью бит длины [math]n[/math] , задается простой формулой [math]C(n) = 2^n[/math] . Таким образом, от нужного количества символов напрямую зависит количество используемой памяти.
Кодирование символьной информации в компьютере

Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер — по их коду.
Поскольку байт — наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста.
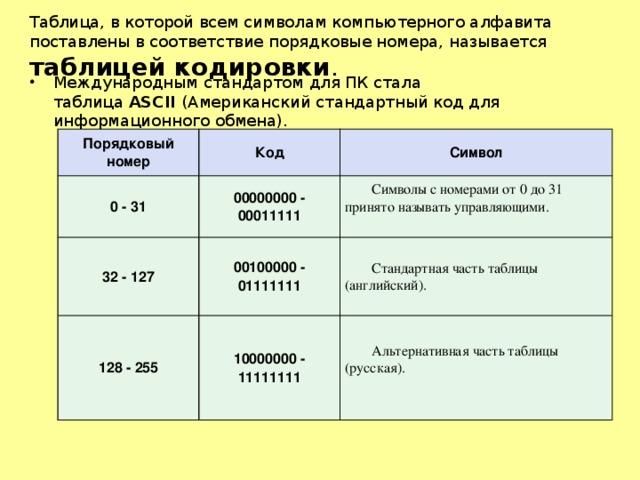
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки .
- Международным стандартом для ПК стала таблица ASCII (Американский стандартный код для информационного обмена).
Порядковый номер
00000000 — 00011111
00100000 — 01111111
Символы с номерами от 0 до 31 принято называть управляющими.
Стандартная часть таблицы (английский).
10000000 — 11111111
Альтернативная часть таблицы (русская).
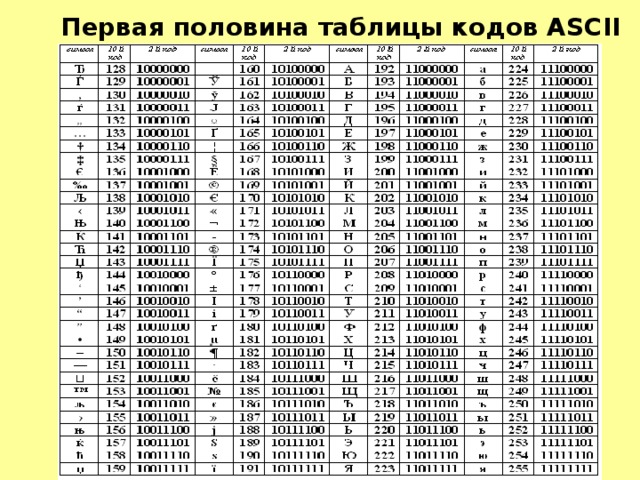
Первая половина таблицы кодов ASCII
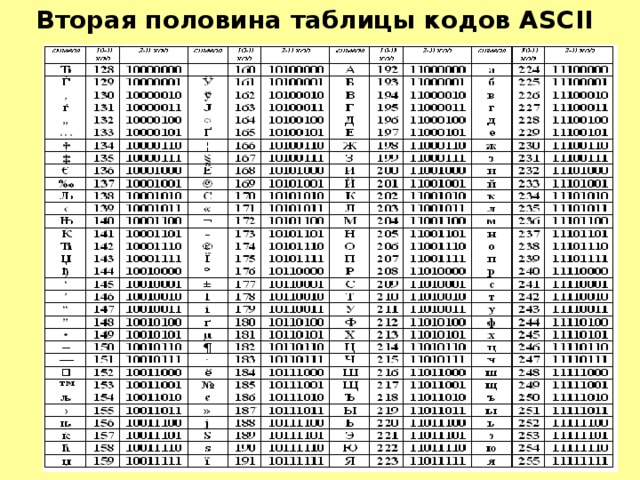
Вторая половина таблицы кодов ASCII

Компьютеры фирмы Apple , работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251 .
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode . Это 16-разрядная кодировка , т.е. в ней на каждый символ отводится 2 байта памяти . Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов .
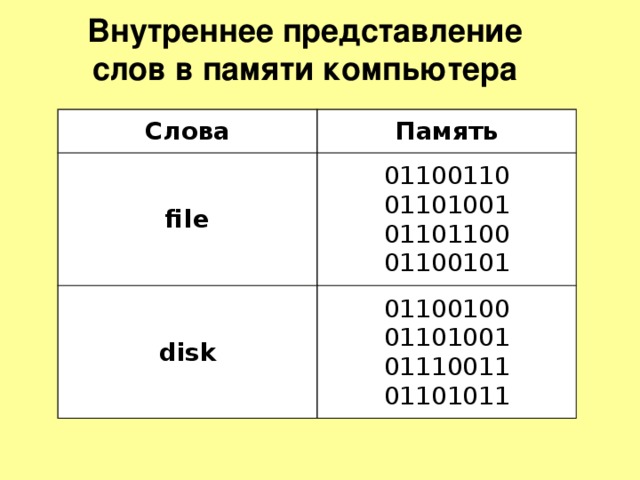
Внутреннее представление слов в памяти компьютера

Используя таблицу ASCII, закодируйте в двоичной форме свою фамилию.
Используя таблицу ASCII, закодируйте в двоичной форме слово byte.
Закодируйте короткую фразу на русском языке. Обменяйтесь полученными кодами с соседом и декодируйте тексты друг друга.
1.Какое количество символов содержит алфавит, используемый для представления текстовой информации в компьютере
5.В таблице кодировки ASCII стандартными(неизменными) являются только символы с номерами
2.Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует
- 256.1024.128
- 256.
- 1024.
- 128
- от 127 до 255.от 0 до 127.от 0 до 255.
- от 127 до 255.
- от 0 до 127.
- от 0 до 255.
- четырехразрядный двоичный код.восьмиразрядный двоичный код.шестнадцатиразрядный двоичный код.
- четырехразрядный двоичный код.
- восьмиразрядный двоичный код.
- шестнадцатиразрядный двоичный код.
6.Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется
3.Двоичный код каждого символа в компьютерном тексте занимает
- таблицей NTFS.таблицей FAT.таблицей кодировки.
- таблицей NTFS.
- таблицей FAT.
- таблицей кодировки.
- 1 байт памяти.1 бит памяти .8 байтов памяти.
- 1 байт памяти.
- 1 бит памяти .
- 8 байтов памяти.
7.С развитием персональных компьютеров типа IBM PC международным стандартом стала таблица кодировки символов
4.В русских национальных кодировках во второй части таблицы ASCII(от 128 до 255) размещаются
- Windows.NTFS.ASCII.
- Windows.
- NTFS.
- ASCII.
- символы русского языка.особые управляющие символы.символы латинского языка.
- символы русского языка.
- особые управляющие символы.
- символы латинского языка.
Таблица кода символов ASCII.

Первая половина для таблицы ASCII. (Именно первая половина, стала стандартом.)

Соблюдение лексикографического порядка, то есть, в таблице буквы (Строчные и прописные) указаны в строгом алфавитном порядке, а цифры по возрастанию, называют принципом последовального кодирования алфавита.
Для русского алфавита тоже соблюдают принцип последовательного кодирования.
Сейчас, в наше время используют целых пять систем кодировок русского алфавита(КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за количества систем кодировок и отсутствия одного стандарта, очень часто возникают недоразумения с переносом русского текста в компьютерный его вид.
Одним из первых стандартов для кодирования русского алфавита на персональных компьютерах считают КОИ8(«Код обмена информацией, 8-битный»). Данная кодировка использовалась в середине семидесятых годов на серии компьютеров ЕС ЭВМ, а со средины восьмидесятых, её начинают использовать в первых переведенных на русский язык операционных системах UNIX.
С начала девяностых годов, так называемого, времени, когда господствовала операционная система MS DOS, появляется система кодирования CP866 («CP» означает «Code Page», «кодовая страница»).
Гигант компьютерных фирм APPLE, со своей инновационной системой, под упралением которой они и работали (Mac OS), начинают использовать собственную систему для кодирования алфавита МАС.
Международная организация стандартизации (International Standards Organization, ISO)назначает стандартом для русского языка еще одну систему для кодирования алфавита, которая называется ISO 8859-5.
А самая распространенная, в наши дни, система для кодирования алфавита, придумана в Microsoft Windows, и называется CP1251.
С второй половины девяностых годов, была решена проблема стандарта перевода текста в цифровой код для русского языка и не только, введением в стандарт системы, под названием Unicode. Она представлена шестнадцатиразрядной кодировкой, это означает, что на каждый символ отводится ровно по два байта оперативной памяти. Само собой, при такой кодировке, затраты памяти увеличены в два раза. Однако, такая кодовая система позволяет переводить в электронный код до 65536 символов.
Специфика стандартной системы Unicode, является включением в себя абсолютно любого алфавита, будь он существующим, вымершим, выдуманным. В конечном счете, абсолютно любой алфавит, в добавок к этом, система Unicode, включает в себя уйму математических, химических, музыкальных и общих символов.
Давайте с помощью таблицы ASCII посмотрим, как может выглядеть слово в памяти вашего компьютера.

Очень часто случается так, что ваш текст, который написан буквами из русского алфавита, не читается, это обусловлено различием систем кодирования алфавита на компьютерах. Это очень распространенная проблема, которая довольно часто обнаруживается.
Юникод — появление универсальной кодировки текста (UTF 32, UTF 16 и UTF 8)
Эти тысячи символов языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных кодировках ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой кодировкой текста, вышедшей под эгидой консорциума Юникод, была кодировка UTF 32 . Цифра в названии кодировки UTF 32 означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного символа в новой универсальной кодировке UTF 32.
В результате чего один и то же файл с текстом, закодированный в расширенной кодировке ASCII и в кодировке UTF 32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью UTF 32 число символов равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество символов использовать в кодировке вовсе и не было необходимости, однако при использовании UTF 32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много и такое расточительство себе никто не мог позволить.
В результате развития универсальной кодировки Юникод появилась UTF 16 , которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. UTF 16 использует два байта для кодирования одного символа. Например, в операционной системе Windows вы можете пройти по пути Пуск — Программы — Стандартные — Служебные — Таблица символов.
В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберите в Дополнительных параметрах набор символов Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из этих символов вы сможете увидеть его двухбайтовый код в кодировке UTF 16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF 16 с помощью 16 бит? 65 536 символов (два в степени шестнадцать) было принято за базовое пространство в Юникод. Помимо этого существуют способы закодировать с помощью UTF 16 около двух миллионов символов, но ограничились расширенным пространством в миллион символов текста.
Но даже удачная версия кодировки Юникод под названием UTF 16 не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них после перехода от расширенной версии кодировки ASCII к UTF 16 вес документов увеличивался в два раза (один байт на один символ в ASCII и два байта на тот же самый символ в кодировке UTF 16). Вот именно для удовлетворения всех и вся в консорциуме Юникод было решено придумать кодировку текста переменной длины .
Такую кодировку в Юникод назвали UTF 8 . Несмотря на восьмерку в названии UTF 8 является полноценной кодировкой переменной длины, т.е. каждый символ текста может быть закодирован в последовательность длинной от одного до шести байт. На практике же в UTF 8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить.
В UTF 8 все латинские символы кодируются в один байт, так же как и в старой кодировке ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в UTF 8. Т.е. базовая часть кодировки ASCII перешла в UTF 8.
Кириллические же символы в UTF 8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания кодировок UTF 16 и UTF 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. Производителям шрифтов остается только исходя из своих сил и возможностей заполнять это кодовое пространство векторными формами символов текста.
Теоретически давно существует решение этих проблем. Оно называетсяUnicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодированоN=2 16 =65 536 символов.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Для символов кириллицы в Юникоде выделено два диапазона кодов:
Cyrillic (#0400 — #04FF)
Cyrillic Supplement (#0500 — #052F).
Но внедрение таблицы Unicode в чистом виде сдерживается по той причине, что если код одного символа будет занимать не один байт, а два байта, что для хранения текста понадобится вдвое больше дискового пространства, а для его передачи по каналам связи – вдвое больше времени.
Поэтому сейчас на практике больше распространено представление Юникода UTF-8 (Unicode Transformation Format). UTF-8 обеспечивает наилучшую совместимость с системами, использующими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байтов. В целом, так как самые распространенные в мире символы – символы латинского алфавита — в UTF-8 по-прежнему занимают 1 байт, такое кодирование экономичнее, чем чистый Юникод.
В кодируемом английском тексте используется только 26 букв латинского алфавита и еще 6 знаков пунктуации. В этом случае текст, содержащий 1000 символов можно гарантированно сжать без потерь информации до размера:
Словарь Эллочки – «людоедки» (персонаж романа «Двенадцать стульев») составляет 30 слов. Сколько бит достаточно, чтобы закодировать весь словарный запас Эллочки? Варианты: 8, 5, 3, 1.
Как текстовая информация может выглядеть в памяти компьютера?
Любой текст набирают на клавиатуре, на клавишах клавиатуры, мы видим привычные для нас знаки (цифры, буквы и т.д.). В оперативную память компьютера они попадают только в виде двоичного кода. Двоичный код каждого символа, выглядит восьмизначным числом, например 00111111.
Поскольку, байт — это самая маленькая адресуемая частица памяти, и память обращена к каждому символу отдельно — удобство такого кодирование очевидно. Однако, 256 символов — это очень удобное количество для любой символьной информации.
Естественно, встал вопрос: Какой конкретно восьми разрядный код принадлежит каждому символу? И как осуществить перевод текста в цифровой код?
Этот процесс условный, и мы вправе придумать различные способы для кодировки символов. Каждый символ алфавита имеет свой номер от 0 до 255. И каждому номеру присвоен код от 00000000 до 11111111.
Таблица для кодировки — это «шпаргалка», в которой указаны символы алфавита в соответствии порядковому номеру. Для различных типов ЭВМ используют разные таблицы для кодировки.
ASCII(или Аски), стала международным стандартом для персональных компьютеров. Таблица имеет две части.
Кодирование текстовой информации и компьютеры
Если смотреть на текст глазами компьютера, то в тексте нет предложений, абзацев, заголовков и т. д., потому что весь текст просто состоит из отдельных символов. Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
Мы вводим текст в компьютер при помощи клавиатуры, символы которой мы прекрасно понимаем. Нажимая на какую-то букву, мы отправляем в оперативную память компьютера двоичное представление нажатых клавиш. Каждый отдельный символ будет представлен 8-битной кодировкой. Например буква «А» — это «11000000». Получается, что один символ — это 1 байт или 8 бит. При такой кодировке, путем нехитрых подсчетов можно посчитать, что мы можем зашифровать 256 символов. Для кодирования текстовой информации данного количества символов более чем предостаточно.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.

Про биты
Итак, дети, садитесь, урок первый, представьте себе выключатель. Нет, не двоичный логарифм вероятности… А обычный такой выключатель, тумблер, рычажок, что угодно, включающее например лампочку, когда находится в одном положении и выключающее в другом. На некоторых рычажках даже подписывают буковки I/O, как указатели положений ручки. Нет, выключатель не несёт в себе информацию. Он выключает свет.
У выключателя есть два положения — вкл/выкл. Если мы поставим рядом два выключателя, то количество комбинаций позиций, которое могут занимать их ручки — четыре. (Когда оба выключены, когда оба включены, и две комбинации когда включен только один из них). Если мы возьмём систему из трёх выключателей — они смогут занимать восемь комбинаций. И так далее, N выключателей имеют 2^N комбинаций. Выключатель который имеет только два положения (вкл/выкл) мы можем назвать битом. Если мы представим, что положениям вкл/выкл соответствуют числа 1 и 0, то можно легко записать какое-нибудь целое число в двоичной системе счисления, используя только последовательный набор выключателей, так чтобы каждый выключатель отвечал за свой двоичный разряд.
Безусловно выключатели мы можем применить к магнитной дорожке, или оптическому диску, так, чтобы при помощи специального устройства можно было «включать» или «выключать» их маленькие участки. Теперь мы наконец подошли к тому, что все компьютерные запоминающие устройства состоят из «ноликов и единичек».
Однако, в этих ноликах и единичках нам надо хранить информацию. Какую же информацию нам можно хранить? Давайте рассмотрим один бит. Мы можем условно договориться, что он может хранить информацию, и два его состояния вкл/выкл содержат значения «баклажан» и «не баклажан» соответственно. Это отлично подходит, когда нам надо произвести учёт баклажанов! Однако в реальном мире компьютеры, которые умеют только считать баклажаны — не пользуются спросом. Выходит выключатель (бит) не может нести в себе информацию. Чтобы записывать ноликами и единичками какую-то информацию, было решено группировать их по несколько штук, и такую группу называть байтом.
На заре компьютеров байты составляли 4, потом 5, потом 6 бит… Группа из 6 бит может принимать целых 64 значений. Вполне неплохо, так как можно создать некую таблицу соответствий этих значений определённым символам — кодировку. Такая кодировка уже может содержать цифры и заглавные буквы латинского алфавита, а также некоторые арифметические знаки. «Шестибитные-кодировки» — применялись на компьютерах в 1950-х — 1960-х годах.
Для человека который только начинает изучать информатику, будет понятно и легко запомнить что байт — является минимальной единицей информации. В байт можно записать какое-нибудь число, либо например какой-нибудь символ из таблицы символов (англ. charset, буквально «набор символов») — кодировки (codepage, encoding).
С развитием компьютеров, появилась потребность в большем количестве значений для байта. В 1963-м году появилась первая редакция семибитной кодировки ASCII. Поэтому байты стали занимать 7 бит. 7 бит, требующиеся для одного символа данной кодировки позволяют использовать 128 значений. В этой кодировке уже были включены строчные латинские символы, и больший набор управляющих и арифметических символов.
Всемирное распространение компьютеров подтолкнуло дальнейшее расширение границ занимаемых байтом. Для различных языков требовалось чтобы таблица символов также могла хранить алфавит того языка, где используется данная ЭВМ. На текущий момент восемь — это последнее и видимо окончательное количество бит составляющих байт. Соответственно байт может принимать 256 значений. По сравнению с таблицей ASCII в. новых таблицах символов — организовалось 128 вакантных мест. Теперь я думаю можно рассказать как значения хранятся в различных кириллических кодировках.











